
Article Source
- Title: Elements of Scale: Composing and Scaling Data Platforms
- Authors: Ben Stopford
Column Orientation
Column Orientation is another simple idea. Instead of storing data as a set of rows, appended to a single file, we split each row by column. We then store each column in a separate file.
We keep the order of the files the same, so row N has the same position (offset) in each column file. This is important because we will need to read multiple columns to service a single query, all at the same time. This means ‘joining’ columns on the fly. If the columns are in the same order we can do this in a tight loop which is very cache- and cpu-efficient. Many implementations make heavy use of vectorisation to further optimise throughput for simple join and filter operations.
Writes can leverage the benefit of being append-only. The downside is that we now have many files to update, one for every column in every individual write to the database. The most common solution to this is to batch writes in a similar way to the one used in the LSM approach above. Many columnar databases also impose an overall order to the table as a whole to increase their read performance for one chosen key.

By splitting data by column we significantly reduce the amount of data that needs to be brought from disk, so long as our query operates on a subset of all columns.
In addition to this, data in a single column generally compresses well. We can take advantage of the data type of the column to do this, if we have knowledge of it. This means we can often use efficient, low cost encodings such as run-length, delta, bit-packed etc. For some encodings predicates can be used directly on the uncompressed stream too.
The result is a brute force approach that will work particularly well for operations that require large scans. Aggregate functions like average, max, min, group by etc are typical of this.
This is very different to using the ‘heap file & index’ approach we covered earlier. A good way to understand this is to ask yourself: what is the difference between a columnar approach like this vs a ‘heap & index’ where indexes are added to every field?
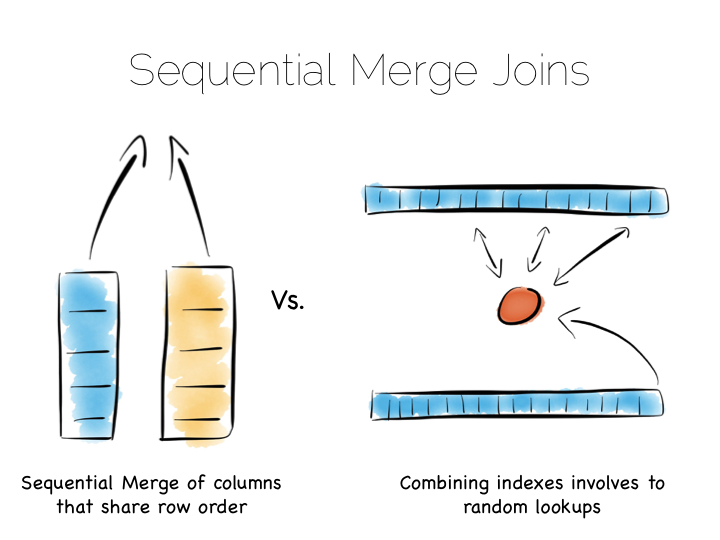
The answer to this lies in the ordering of the index files. BTrees etc will be ordered by the fields they index. Joining the data in two indexes involves a streaming operation on one side, but on the other side the index lookups have to read random positions in the second index. This is generally less efficient than joining two indexes (columns) that retain the same ordering. Again we’re leveraging sequential access.

So many of the best technologies which we may want to use as components in a data platform will leverage one of these core efficiencies to excel for a certain set of workloads.
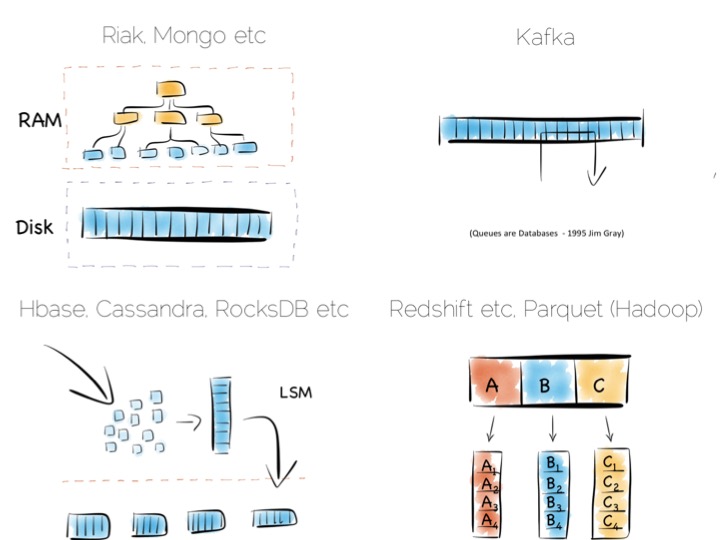
Storing indexes in memory, over a heap file, is favoured by many NoSQL stores such as Riak, Couchbase or MongoDB as well as some relational databases. It’s a simple model that works well.
Tools designed to work with larger data sets tend to take the LSM approach. This gives them fast ingestion as well as good read performance using disk based structures. HBase, Cassandra, RocksDB, LevelDB and even Mongo now support this approach.
Column-per-file engines are used heavily in MPP databases like Redshift or Vertica as well as in the Hadoop stack using Parquet. These are engines for data crunching problems that require large traversals. Aggregation is the home ground for these tools.
Other products like Kafka apply the use of a simple, hardware efficient contract to messaging. Messaging, at it’s simplest, is just appending to a file, or reading from a predefined offset. You read messages from an offset. You go away. You come back. You read from the offset you previously finished at. All nice sequential IO.
This is different to most message oriented middleware. Specifications like JMS and AMQP require the addition of indexes like the ones discussed above, to manage selectors and session information. This means they often end up performing more like a database than a file. Jim Gray made this point famously back in his 1995 publication Queue’s are Databases.
So all these approaches favour one tradeoff or other, often keeping things simple, and hardware sympathetic, as a means of scaling.
So we’ve covered some of the core approaches to storage engines. In truth we made some simplifications. The real world is a little more complex. But the concepts are useful nonetheless.