Article Source
- Title: The Virginian Database, Written Summer 2010.
-
Authors: Peter Bakkum pbb7c@virginia.edu @PBBakkum, NEC Laboratories America, Princeton, New Jersey
The Virginian Database
Abstract
General purpose GPUs are a new and powerful hardware device with a number of applications in the realm of relational databases. We describe a database framework designed to allow both CPU and GPU execution of queries. Through use of our novel data structure design and method of using GPU-mapped memory with efficient caching, we demonstrate that GPU query acceleration is possible for data sets much larger than the size of GPU memory. We also argue that the use of an opcode model of query execution combined with a simple virtual machine provides capabilities that are impossible with the parallel primitives used for most GPU database research. By implementing a single database framework that is efficient for both the CPU and GPU, we are able to make a fair comparison of performance for a filter operation and observe speedup on the GPU. This work is intended to provide a clearer picture of handling very abstract data operations efficiently on heterogeneous systems in anticipation of further application of GPU hardware in the relational database domain. Speedups of 4x and 8x over multicore CPU execution are observed for arbitrary data sizes and GPU-cacheable data sizes, respectively.
Introduction
This is an experimental heterogeneous SQL database written to compare data processing on the CPU and NVIDIA GPUs. It was written by Peter Bakkum during the summer of 2010 at NEC Laboratories America in Princeton with several subsequent expansions. It shares no code with any other database system. A thanks goes to the Systems Architecture group at NEC, Srimat Chakradhar in particular, and the LAVA Lab group at UVa, Prof. Kevin Skadron in particular.
Despite its name, this particular project has no affiliation with UVa.
A preliminary academic paper is available here. This research builds on a previous project that accelerated portions of the SQLite database with GPUs available here.
For background on this area, I recommend the following excellent article: Data Monster: Why graphics processors will transform database processing.
Research
The idea behind this project is simple; By executing database queries on the GPU we can achieve significant acceleration, while still using SQL as the programmer’s interface. Few commercial products use GPGPU acceleration, and there has yet to be a SQL database that exploits GPUs to their full potential. This research attempts to contribute to the development of future databases.
The purpose of this database is to test and demonstrate several novel ideas relating to RDBMS-like computation on the GPU. Thus, all queries can be executed on the CPU with a single thread, the CPU with multiple threads, or the GPU.
The ideas are as follows:
-
An opcode model of execution: Most GPU parallel primitives assign each operation to a separate CUDA kernel. Virginian uses high-granularity switching between discrete operations within a single kernel. This is advantageous because a global synchronization is not needed between operations.
-
The Tablet data structure: By vertically partitioning data, it can be moved in discrete sets between CPU and GPU memory. This enables queries even on data sets larger than GPU memory.
-
Mapped memory with lazy writes: Mapping main memory onto the GPU obviates the need for data transfers before and after a query execution, the most expensive piece of GPU query processing. Writes back to main memory are cached lazily on the GPU to guarantee coalescing.
This is a “SQL Database” in that it has a SQL interface and is capable of performing several types of queries on non-volatile data, but is far from supporting the full SQL standard, and only handles filters through SELECT. It is not suitable for production, but has been written to be small and make it easy to experiment and compare execution on the CPU and GPU.
This code was developed on Linux 2.6 machines and tested with NVIDIA Tesla C1060, Geforce GTX 570, and Tesla C2050 cards on CUDA 4.0 and above. Compiling will at the very least probably involve tweaking the project makefile, and might involve changing some code. The code involves system calls to unix libraries, so compiling on anything other than Linux may be harder, and compiling on Windows may require some major changes, though I’ve never tried it. As stated, this is an experimental project and it will be difficult to use if you are unfamiliar with C and CUDA.
Documentation generated by Doxygen has been uploaded here.
Results
This research is more about the organization of the database than the query running times, since they depend on many factors and are somewhat specific to the workload I have focused on. Please read my note about the results below. The results are for brute force SELECT queries with conditions and math operations.
On the machines I have tested with, GPU execution is 2x - 5x faster than multicore CPU execution when all-in data and results transfers to and from the GPU are included. When these are cached on the GPU, it is around 5x - 10x faster than the CPU. Speedup depends on the query, number of data records, number of result records, and the specific test hardware. Your mileage may vary.
Here are some performance charts that compare running times of a 10 query suite on the CPU and two GPU execution techniques. The mapped configuration is applicable to arbitrary data sizes, while the cached configuration applies only for data sizes that fit within the GPU’s global memory.
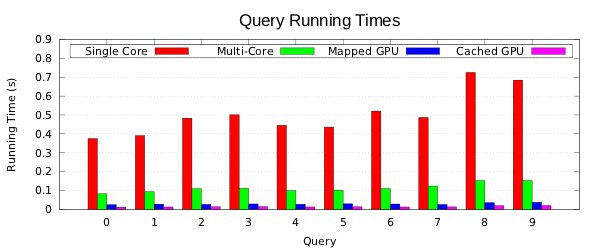
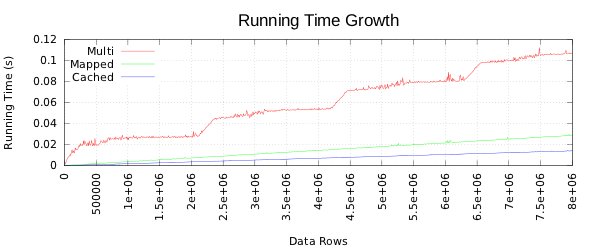
A Note About Results
The classic issue with research like this that compares CPU and GPU running times is that one implementation is way more optimized than the other, or the authors fail to mention that the GPU results do not include memory transfer times, or something along those lines, leading to inflated results. There was even a paper by Intel, ominously titled “Debunking the 100X GPU vs. CPU myth,” released to refute some of the most egregious offenders in terms of comparison. My impression is that this has lead some people to conclude ‘this GPU thing is overblown’.
I would disagree. Though it may not be in the range of 100x, most of these problems still have significant speedup on the GPU. An NVIDIA manager responded to the Intel paper with, “It’s a rare day in the world of technology when a company you compete with stands up at an important conference and declares that your technology is only up to 14 times faster than theirs.”
Here is what you should know about these results:
-
They are for a particular hardware configuration, on a particular query set, on a particular data set, with particular workload characteristics, etc. This research is fundamentally about the data structures and programming techniques I used, not producing a CPU/GPU comparison. GPU technology will likely look very different in just a few years, so what matters is how you program them, not what the speedup is today.
-
Here is one perspective: These results used an Intel Core i7 960 and an NVIDIA GTX 570. The CPU has 4 (hyperthreaded) cores, 25.6 GB/s memory throughput, and can do about 70 GFLOPS. The GPU has 480 cores, 152 GB/s memory throughput, and is benchmarked at 1405 GFLOPS. Obviously there are many differences between the two, but the GPU has enough horsepower that its easy to see how this acceleration is possible.
-
I have no doubt that neither of my implementations is truly ‘optimal’ and that if you were to spend time playing with my code you could probably make either faster than it is today. I’ve aimed more for CPU/GPU coprocessing than blowing one hardware or another out of the water. Again, the real problem here is how you write your code to work on the CPU while exploiting GPU hardware.
License
Copyright (C) 2012 Peter Bakkum
(MIT License)
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the “Software”), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
Using Virginian
Setup
The first step to use Virginian is to download the source by running
git clone git@github.com:bakks/virginian.git
You may be able to use Virginian simply by linking against the virginian.h and
virginian.a files in the lib/ directory. If this does not work, or if you want
to run the included tests and benchmarks, you will have to compile the project
yourself.
Compilation
To compile Virginian, verify that your machine fits the requirements below and follow these instructions:
-
Open
src/Makefileand verify the locations of the programs and libraries shown at the top, notably theGCC,GPP, andCUDAvariables. You may also want to change theCUDA_LIBRARYfunction tolib64if you have the 64 bit version of CUDA. -
Run
make cleanin the project’s root directory -
Run
makein the project’s root directory
It will then create
a large test database and call make in the src/ directory, which
will make all of the project source files and run a test to compare the
running times of queries for single and multicore CPU execution and GPU
execution. These tests can be run again just by executing make in the src/
directory. Some benchmarks are output as release/*.dat.
There are 2 modes of compilation: debug, and release. The
release settings enable optimization on the CPU but do not affect the GPU
speed, thus
timing results should only be reported from
release settings. The compilation mode is set in src/Makefile.
If any of the tests fail, there was a problem. I’ve attempted to verify all the functionality I’ve written, and all tests pass for me, but CUDA still has some problems that result in non-deterministic behavior. The first thing to try is a hard reset of your machine, as GPU devices can sometimes enter a state where kernel launches or even simple memory writes fail randomly until the device is reset.
Requirements
The requirements for compilation are as follows:
-
Linux 2.6/3.0
-
CUDA 4.0
-
An SM 2.0 NVIDIA GPU
The following programs are required:
-
gcc 4.4
This is always accessed through nvcc and if compiling in the debug or gccrelease modes. Last tested with gcc v4.4.6. Note that nvcc is not compatible with gcc versions greater than 4.4.
-
g++ 4.4
Used for running and compiling test code written in C++. Last tested with g++ v4.4.6.
-
nvcc
CUDA compiler, used for GPU related code. Last tested with nvcc v4.0.
-
flex
Used for SQL code compiler. Last tested with flex v2.5.
-
bison
Used for SQL code compiler. Last tested with bison v2.4.
-
awk
There is an awk script that scrapes a header file to automatically generate a C file used for debugging. Last tested with mawk v1.3.3.
-
make
This project lives in a make world. Last tested with GNU Make v3.81.
Using the Virginian API
This project’s interface is well documented but I haven’t taken the step of
dividing the user-facing and internal functionality, so the documentation covers
both. Using the code externally should be fairly straightforward. The
compilation and testing process outputs an archive file to the lib/ directory
that can be compiled with another C/C++ project. The files you need are
lib/virginian.a and lib/virginian.h.
The example/ directory contains a very
simple project useful for getting started using this code. The main function
from this project is shown below. To use the database I recommend you start from
the example and read the documentation or even look at the source code to add
functionality. The interface overall is not very user friendly, email me if you
get stuck.
Supported Queries
Only a small subset of SQL is supported right now. The following shows acceptable syntax:
SELECT <expression list> FROM <table name> WHERE <condition list>
An expression can be a column or mathematical value, and math operations are
supported, e.g. col0 + 10. A condition compares two expressions and evaluates
to a boolean, e.g. col0 + 10 < col1. Conditions can be chained together with
ORs and ANDs. Floating point and integer queries work,
strings are not supported.
Example
/**
* This is a simple example of a program that uses the Virginian database. This
* is intended to help begin experimenting with the code, there is significant
* functionality that is not utilized. For more information on the functions
* used below, see the documentation or source files. A make file is included to
* show how compilation works.
*/
#include <stdio.h>
#include <unistd.h>
#include "virginian.h"
int main()
{
// declare db state struct
virginian v;
// delete database file if it exists
unlink("testdb");
// initialize state
virg_init(&v);
// create new database in testdb file
virg_db_create(&v, "testdb");
// create table called test with an integer column called col0
virg_table_create(&v, "test", VIRG_INT);
virg_table_addcolumn(&v, 0, "col0", VIRG_INT);
// insert 100 rows, using i as the row key and x as the value for col0
int i, x;
for(i = 0; i < 100; i++) {
x = i * 5;
virg_table_insert(&v, 0, (char*)&i, (char*)&x, NULL);
}
// declare reader pointer
virg_reader *r;
// set optional query parameters
v.use_multi = 0; // not multithreaded
v.use_gpu = 0; // don't use GPU
v.use_mmap = 0; // don't use mapped memory
// execute query
virg_query(&v, &r, "select id, col0 from test where col0 <= 25");
// output result column names
unsigned j;
for(j = 0; j < r->res->fixed_columns; j++)
printf("%s\t", r->res->fixed_name[j]);
printf("\n");
// output result data
while(virg_reader_row(&v, r) != VIRG_FAIL) {
int *results = (int*)r->buffer;
printf("%i\t%i\n", results[0], results[1]);
}
// clean up after query
virg_reader_free(&v, r);
virg_vm_cleanup(&v, r->vm);
free(r);
// close database
virg_close(&v);
// delete database file
unlink("testdb");
}
Compile-time Options
There are several macros that change the program at compile time. They are added by editing the CUSTOM_FLAGS variable of the Makefile in the src/ folder. The format should be -D MACRO_NAME.
-
VIRG_DEBUG
Enables debugging code, such as printing out the higher-level opcodes as they execute and initializing memory areas to 0xDEADBEEF.
-
VIRG_DEBUG_SLOTS
Enables tablet slot information printing to stdout. This prints out a listing of the tablet ids and locks whenever a lock is acquired or released.
-
VIRG_NOPINNED
Do not declare the main-memory tablet slots as pinned. This switches the allocation to a malloc() rather than a cudaMallocHost(). This means that GPU execution cannot use streaming or mapped memory.
-
VIRG_NOTWOSTEP
Do not buffer results temporarily in GPU global memory before writing them to main memory. This two-step copy operation makes mapped memory on the C1060 faster by an order of magnitude but should be disabled for ION boards because there is no distinction between GPU memory and main memory.
Architecture
The project can be broken into the following components, which roughly correspond to the source code directories.
-
Query Parser
Accepts SQL as input and outputs programs in discrete steps known as opcodes.
-
Virtual Machine
Executes an opcode program, processing data records and outputting a result set. The virtual machine has been written on both the CPU and GPU.
-
Tablet Functionality
Code that manipulates the tablet data structure to add and read data.
-
Table Functionality
Manages groups of tablets in tables
-
Memory Functionality
Code that manages tablets in a pre-allocated space in memory.
-
Database Functionality
Code that manages paging tablets between memory and disk, and writes metadata to a database file to ensure non-volatile storage of data.
-
Test Code
Written in C++ with GTest, this tests the above functionality.
Opcodes
These opcodes are the steps into which a query is broken down. Each opcode has four arguments, though few opcodes use all four. The first three are integer values, while the fourth can be any type.
In general the first two opcodes are used to refer to virtual machine registers and the third is used to refer to a program counter value, such as the end of the parallel section. These are just conventions, however, and not all opcodes are organized in this way.
These opcodes are loosely based on the SQLite opcodes but have a number of subtle semantic differences. The SQLite opcodes can be seen at http://sqlite.org/opcode.html. The changes have been made both to better support heterogeneous execution and to make things a little simpler. The biggest change is that even though the virtual machine operating on each row can diverge and have an independent program counter, that program counter can never decrease. In other words, execution over the data-parallel segment proceeds as a waterfall, so opcodes can only jump ahead.
Higher-Level Opcodes
These opcodes control setting up query execution and launching the data-parallel segment. These opcodes do not handle row data directly and are implemented in vm/execute.c. They are listed in alphabetical order.
-
Finish [], [], [], []
This opcode marks the end of the data-parallel segment of query execution. Its purpose is to provide a jump location for the higher-level virtual machine and to clean up the remaining tablet locks of the data-parallel segment.
-
Parallel [], [], [end of parallel section], []
Begins the data-parallel segment of query execution. Depending on the configuration settings, this either launches a single-core, multi-core, or GPU virtual machine that treats every row as independent in its processing. The third argument refers to the opcode marking the end of the parallel segment, which should always be Finish.
-
ResultColumn [column type], [], [], [column name]
Prepares the result tablet to receive a certain column of data. The type is one of the integer enumerations of data types, such as VIRG_INT, and the name is a character pointer to a location in memory of a c string containing the result column names. Note that only the semantics to call this opcode once are currently implemented.
-
Table [table id], [], [], []
Opens a handle on a table for execution. Required when beginning execution.
Lower-Level Opcodes
These opcodes are used to work directly with the data of a table, and can be independently executed for each row. They are specifically designed to be platform independent, meaning they are used for both CPU and GPU execution. Intermediate data during this lower-level step is stored in the virtual machine registers, which are unions that allow the virtual machine to temporarily store any variable type. They should not be confused with the notion of the CUDA register space, and in fact are stored in local memory on the GPU.
The four arguments are referred to as p1, p2, p3, and p4. Register locations are referred to as a reg[] array. Thus, reg[p1] refers to the p1-th virtual machine register.
One of the virtual machine elements associated with each row is the concept of validity. The SELECT operation is just a filter, so we determine which rows are valid and invalid, and the ResultRow opcode only outputs those rows which are valid. This is different from the SQLite semantics, where only valid rows execute this opcode, and this change was intended to better support coordination among threads on the GPU and within the SIMD block on the GPU.
-
Add [destination register], [source register 1], [source register 2], [] Executes the operation reg[p1] = reg[p2] + reg[p3].
-
And [comparison register 1], [comparison register 2], [jump location], [validity] If (reg[p1] && reg[p2]) evaluates to true, then the program counter associated with this row jumps to p3 and the rows validity is set to the integer value of p4.
-
Cast [target type], [register], [], [] Casts the value in register p2 to the type denoted by p1, such as VIRG_INT.
-
Column [destination register], [source column], [], []
Loads the value from from the p2-th fixed column of the current table and places it in the p1-th register.
-
Converge [], [], [], []
Marks the end of the data-parallel query execution segment. This opcode causes the lower-level virtual machine to exit and return control to the higher-level virtual machinemachine.
-
Div [destination register], [source register 1], [source register 2], []
Executes the operation reg[p1] = reg[p2] / reg[p3].
-
Eq [comparison register 1], [comparison register 2], [jump location], [validity]
If (reg[p1] == reg[p2]) evaluates to true, then the program counter associated with this row jumps to p3 and the rows validity is set to the integer value of p4.
-
Float [destination register], [], [], [constant]
Sets the value of reg[p1] to the float value of p4.
-
Ge [comparison register 1], [comparison register 2], [jump location], [validity]
If (reg[p1] >= reg[p2]) evaluates to true, then the program counter associated with this row jumps to p3 and the rows validity is set to the integer value of p4.
-
Gt [comparison register 1], [comparison register 2], [jump location], [validity]
If (reg[p1] > reg[p2]) evaluates to true, then the program counter associated with this row jumps to p3 and the rows validity is set to the integer value of p4.
-
Integer [destination register], [constant], [], []
Sets the value of reg[p1] to p2, which is an integer value.
-
Invalid [], [], [], []
Invalidates all rows that have this opcode executed, so the only rows that are output by ResultRow are those that jump over this opcode.
-
Le [comparison register 1], [comparison register 2], [jump location], [validity]
If (reg[p1] <= reg[p2]) evaluates to true, then the program counter associated with this row jumps to p3 and the rows validity is set to the integer value of p4.
-
Lt [comparison register 1], [comparison register 2], [jump location], [validity]
If (reg[p1] < reg[p2]) evaluates to true, then the program counter associated with this row jumps to p3 and the rows validity is set to the integer value of p4.
-
Mul [destination register], [source register 1], [source register 2], []
Executes the operation reg[p1] = reg[p2] * reg[p3].
-
Neq [comparison register 1], [comparison register 2], [jump location], [validity]
If (reg[p1] != reg[p2]) evaluates to true, then the program counter associated with this row jumps to p3 and the rows validity is set to the integer value of p4.
-
Not [test register], [], [jump location], [validity]
If reg[p1] evaluates to true, then the program counter associated with this row jumps to p3 and the rows validity is set to the integer value of p4.
-
Or [comparison register 1], [comparison register 2], [jump location], [validity]
If (reg[p1] || reg[p2]) evaluates to true, then the program counter associated with this row jumps to p3 and the rows validity is set to the integer value of p4.
-
Result [start register], [result columns], [], []
If the current row is still valid then output the registers from reg[p1] to reg[p1 + p2] as a row of fixed-size results. The CPU virtual machine attempts to efficiently group the copies of a column in adjacent rows, while the GPU coalesces these writes after an atomic scatter operation conducted in two-steps in shared and global memory.
-
Rowid [destination register], [], [], []
Loads the value of the current row’s primary key and places it in reg[p1]
-
Sub [destination register], [source register 1], [source register 2], []
Executes the operation reg[p1] = reg[p2] - reg[p3].