
Article Source
- Title: 램클라우드(RAMCloud)
RAMCloud Overview
지난 40년간 마그네틱 디스크는 가장 주요한 저장공간이었다. 대용량 데이터들은 디스크에 기록되고 읽혀졌으며, 상대적으로 용량이 작았던 메인 메모리 때문에 데이터 버퍼링 및 메모리의 효율적 사용이 매우 중요하였다. 때문에 Jim Gray의 5분의 규칙(five-minute rule) 과 같이 데이터 버퍼링 또는 캐싱에 대한 경험적 규칙이 얘기되어 왔다. 실제 디스크에 기반한 DBMS에서도 이 버퍼의 성능이 엄청나게 큰 영향을 미쳐왔다.
5분의 규칙은 1987년, 짐 그레이가 SIGMOD Record에서 언급한 것으로 디스크와 메모리의 접근 시간과 용량을 간단히 수식화하여 약 5분 내 다시 참조될 데이터는 메모리에 올려두는 것이 좋다라고 언급한 것이다. 해당 논문이 쓰여지고 10년뒤 97년에 그레이는 다시 그당시의 저장 계층의 특성에 의해 이 규칙이 어떻게 변화되었는지 다시 소개하였고, 또 다시 10년 뒤 2008년에는 고츠 그라페(Goetz Graefe)가 SSD의 출현에 의해 이 규칙이 어떻게 변화되는지를 소개하였다.(2007년에 짐 그레이가 실종되서 그는 쓰지 못하였다.)
디스크는 세월이 지남에 따라 그
저장용량(capacity)은 엄청나게 개선되어 왔다. 하지만, 저장 용량에 비해
접근 지연시간(latency)은 크게 개선되지 못하여 왔다. 아래 표를
보자.
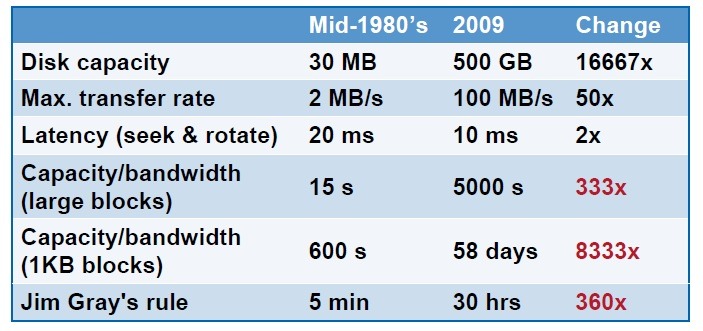
따라서 저장용량을 bandwidth로 나누어보면, 용량에 비해 bandwidth 개선이 턱없이 부족함을 보이는 것을 확인할 수 있다. 80년대 중반 15초면 다 읽을 수 있던 것을 지금은 직렬 읽기만 해도 5,000초가 걸리고, 랜덤 읽기인 경우에는 약 58일이라는 엄청난 시간이 요구한다.
이에 따라 연구자들은 기존의 HDD를 대체하기 위해 SSD를 연구해 왔고, SSD는 이제 울트라북을 포함한 여러 PC에 널리 이용되고 있다. 하지만, 데이터센터 스케일에서도 SSD를 적용할 수 있을까? 스탠포드대의 연구자들은 램클라우드라는 프로젝트를 통해 SSD나 디스크보다 이제는 DRAM을 주요 저장공간으로 활용해야 한다고 역설한다. 이들은 인터넷 스케일 서비스의 제공에 있어 HDD를 전혀 이용하지 않고, 수백, 수천대의 노드 컴퓨터들을 연결하여 이들의 메인 메모리들에 모든 데이터를 저장, 관리하는 것을 목표로 한다.
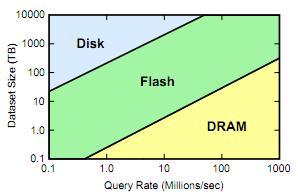
이러한 목표를 제시한 근거에는 여러가지가 있지만, 우선 위 표를 다시 보면 짐 그레이의 5분의 규칙에 따라 5분 이내 재참조될 데이터는 메모리에 올려두었던 것이 이제는 30시간 내에 재참조되는 데이터이라면, 메모리에 올려두는 것이 더 낫다라는 결과를 얻게 되었다는 점이다. 즉, 현재는 가급적이면 모든 데이터를 메모리에 올려두는 것이 효과적이라는 것이다. 사실 이러한 현실은 이전의 Jim Gray의 예측과도 일치한다. 그는 예전에 ”Memory becomes disk, disk becomes tape, and tape is dead.”라 언급하였다. 즉, 이제는 메모리를 이전의 디스크가 점유했던 주요 저장소로서 활용하고 디스크는 백업과 아카이빙을 위한 용도로 쓰자는 것이다. (사실 테입이 완전히 사라진 것은 아니다. 아직 테입은 여러 데이터 센터에서 데이터 백업의 마지막 보루로 사용되고 있다.) 메모리를 디스크처럼 쓰는 경우 가질 수 있는 많은 장점이 있다. 우선 접근지연시간(latency)가 현격하게 줄어든다. 현재의 데이터 센터를 통한 인터넷 서비스들은 인터넷-스케일이라는 규모가 큰 request들을 처리하는 것을 목적으로 한다. 때문에, 단일 노드로 구성되지 않고 데이터 센터에 많은 노드들을 네트워크로 연결하고 이를 통해 부하를 분산하는 분산 시스템이라는 특징을 가진다. 또한, 웹 서비스와 해당 서비스가 처리/제공하는 데이터가 서로 다른 노드에 위치하는 구조로 인해 접근지연시간이 단일 시스템 구조보다 느리다. 메모리를 디스크처럼 쓰는 경우 이러한 환경에서도 접근지연시간을 마이크로 세컨드 단위로 줄일 수 있다. SSD를 디스크 대신 쓰는 경우에도 접근지연시간을 크게 줄일 수 있을 것이다. 하지만 저자들은 SSD의 접근지연시간은 디스크에 비해 훨씬 빠르지만, 그렇다하더라도 SSD보다 DRAM의 접근 지연시간 특히 쓰기지연시간이 훨씬 빠르므로 DRAM이 보다 경쟁성이 있다고 저자들은 얘기한다. 아래 그림은 디스크 드라이브, 플래시 메모리오 메모리의 특징을 그림으로 도식화한 것이다. 그림에서 보면 가장 덜 빈번하고, 한번에 요구되는 데이터 량이 큰 경우에는 디스크가 가장 경쟁력이 있고, 작은 크기의 데이터에 대한 매우 빈번한 질의에 대해서는 DRAM이 경쟁력이 있다. 그리고, 이들간의 경계는 시간이 지남에 따라 위쪽으로 이동하는 경향을 보인다. 이러한 경계의 이동은 DRAM의 경쟁력이 갈수록 커짐을 의미한다.
낮은 접근지연시간은 또한 온라인 트랜잭션 처리 비용을 줄이는데 큰 도움을 준다. 예를 들어 일관성을 보장하는데 드는 비용, 즉 특정시간에 동시 수행되는 트랜잭션의 수(overlapping transactions)를 O라고 할 때 이는 새 트랜잭션의 도착비율(arrival rate) R과 각 트랜잭션의 운용기간(duration) D의 곱으로 간략히 표현할 수 있다. O ~ R*D . 동시 수행되어야 할 트랜잭션의 수가 많을 수록 그만큼 트랜잭션들의 일관성을 보장하기위한 비용은 더 높아질 것이다. R 즉 새 트랜잭션의 도착 비율은 시스템의 스케일이 커가면서 계속 커지게 된다. 하지만, D 각 트랜잭션의 운용기간은 접근지연시간이 낮아짐에 따라 크게 개선되며 따라서 동시수행되는 트랜잭션 수를 줄어줄 수 있다. 사실 이러한 아이디어는 이전부터 메모리 상주형 DBMS(memory-resident DBMS 또는 in-memory DBMS)라는 형태로 구현되어 왔다. 하지만, 메모리 상주형 DBMS가 단일 또는 몇개의 노드를 이용하는 것에 국한되었던 것에 비해 램클라우드는 최소 수백대의 노드들의 메모리를 하나의 virtual storage로 보고 여기에 데이터를 저장시킨다는 점이 차이가 있다.
그렇다면 디스크 전체를 메모리로 대체하는 경우 그 비용은 어떨까? 비현실적이지는 않을까? 여기에 저자들이 조사한 간단한 통계정보가 있다.
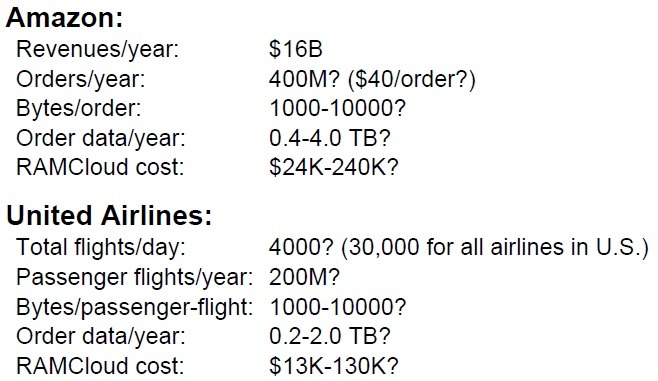
2009년 당시 Amazon과 UA에서의 데이터량과 그당시의 메모리 가격을 가지고 해당 데이터를 모두 메모리에 얹기 위해서 소요되는 비용을 계산해 보았더니, Amazon의 경우 적게는 2.4만불에서 24만불 정도가 소요될 거라 한다. UA의 데이터는 그보다 더 작을 것이라 한다. 즉, 메모리는 HDD나 SSD에 비해 빠를 뿐더러 I/O집중인 작업에 보다 싸면서 효과적일 수 있다는 것이다.
그렇다면 메모리 캐싱하고 이 램클라우드하고는 어떻게 틀린가? 인터넷 규모의 서비스를 제공하는 ISP들은 Memcached와 같은 분산 메모리 캐싱을 지원을 한다. 2009년 페이스북은 약 4,000개의 MySQL 서버를 이용해서 데이터 요청을 분산하였다 한다. 작업부하의 분산은 페이스북 자체의 코드로 이루어졌다고 한다. 그러다 이또한 바로 한계에 봉착해서 2,000개의 memcached 를 투입하였다고 한다. 사실 램클라우드는 인터넷 규모의 서비스 제공에 있어 확장성(scalability)을 제공하기 위해 분산 메모리 구조를 지원한다는 점이서는 memcached와 같은 기존 분산 캐싱 기술들과 크게 유사해 보인다. 차이점은 램클라우드는 캐싱이 아닌 아예 데이터를 통채로 메모리에 올리겠다는 것이다. 페이스북 사례와 같은 경우에는 캐쉬된 데이터와 MySQL에 저장된 실 데이터 간의 불일치에 따른 일관성 유지에 따른 관리의 복잡성이 대두될 수 있다. 또한, 데이터가 캐슁되지 않은 경우에는 결국에는 디스크 접근을 필요로 한다. 데이터 접근의 분데이터가 메모리에 캐싱되어 있다면 메모리 접근지연시간을 보장할 수있지만 만약 해당 데이터가 메모리에 캐싱되어 있지 않으면, 디스크에 접근을 하면서 그만큼 접근지연시간이 늦어질 것이라는 점 때문이다.
단일 사이트에서 동작하도록 설계된 DBMS의 제한된 확장성의 문제는 여러 곳에서 이미 지적된 바 있다. 이러한 문제를 해결하기 위한 현재의대표적인 기술은 NoSQL이라 볼 수 있다. 하지만 NoSQL은 확장성을 위해 기존의 DBMS가 가졌던 주요한 기능, 관계형 모델 대신 단순한 key-value model과 제한된 일관성 지원 정책 등의 한계를 또한 갖는다. 그리고 이들 또한 대부분 디스크에 기반한 저장소를 기준으로 설계되어 있으며, 관계형 DBMS만큼 범용적이지도, 호환적이지도 않다라고 저자들은 언급한다.
RAMCloud는 이러한 문제들을 해결하면서, 보다 큰 확장성과, 더짧은 접근지연시간을 제공하는 범용의 저장 시스템을 제공하기 위해 고안되었다.
하지만, 이렇게 모든 데이터를 메모리에 올려놓았을때 문제점은 메모리 자체의 휘발성에 따라 장애 시 데이터가 유실될 수 있다는 점이다. 이에 대한 해결책은 크게 다른 데이터 노드에의 메모리에 데이터를 복제해 두거나 디스크에의 로깅을 생각해 볼 수 있다.
데이터들을 복제해서 모두 메모리에 두는 방식은 synchronous I/O를 가지고도 고성능을 보장할 수 있는 장점이 있지만, 상대적으로 비싼 DRAM이라는 저장장치의 공간을 크게 낭비하게 된다. 반대로, 데이터의 복제나 로그를 디스크에 위치시키는 것은 디스크의 접근지연시간에 따른 비효율성을 피할 수 없다. 때문에 이들은 메모리에의 로그 복제와, 메모리에서 디스크로의 비동기적인 data flushing을 통해 이 문제를 해결하려고 하고 있다.
아래 그림은 초기에 저자들이 생각하는 내고장성을 지원하기 위한 방법을 도식화한것이다. 데이터에 대한 쓰기 연산은 마스터 노드의 메모리 상에서 바로 처리하고, 그에 따른 로그 엔트리들은 다른 노드들의 메모리에 임시적으로 위치시킨다. 그리고, 비동기적으로 각 노드의 메모리에 저장된 로그 데이터를 디스크에 기록한다.
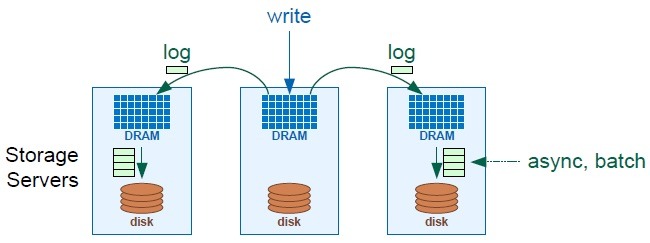
하지만, 아직 어떠한 방식으로 장애에 대한 내고장성을 지원하는지에 대해서는 구체적으로 연구결과를 내놓았다고 보기 어렵다. 아직까지는 이 연구는 실제 적용된 시스템이라기 보다는 일종의 비전에 가깝다. 하지만, 기술의 트렌드는 저자들이 생각하는데로 변화해 나갈것이라 생각된다.
RamCloud에 대한 간단한 소개와 그들의 프로젝트 홈페이지는 아래와 같다.
[https://ramcloud.stanford.edu/wiki/display/ramcloud/Home](https://ramcloud.atlassian.net/wiki/display/RAM/RAMCloud)
References
-
The 5 minute rule for trading memory for disc accesses and the 10 byte rule for trading memory for CPU time, ACM SIGMOD Record, 1987
-
The five-minute rule ten years later, and other computer storage rules of thumb, ACM SIGMOD Record, 1997
-
The five-minute rule 20 years later (and how flash memory changes the rules), ACM Queue, 2008
-
MapReduce 정보과학회 SIGDB 워크샵 발표 자료. (1) 2012/07/09
-
Hadoop에서 네트워크가 성능에 미치는 영향. (1) 2012/06/11
-
램클라우드(RAMCloud) (0) 2012/01/17
-
MapReduce 소개 자료 (0) 2012/01/06
-
M. Stonebraker from “My Top 10 Assertions about Data Warehouses” (0) 2011/07/09
-
MapReduce: 단순하지만 유용한 병렬 데이터 처리 기법 -2부 (0) 2011/06/06