Article Source
ML models with ZenML and BentoML
머신러닝 모델을 배포하는 것은 어려울 수 있습니다. 기존 인프라에 모델을 통합하는 방법, ‘온프레미스’ 또는 클라우드에 배포할 것인지, 데이터 프라이버시와 보안과 같은 잠재적인 문제를 처리하는 방법 등 고려해야 할 여러 가지 요소가 있습니다. 또한, 제품 환경에서의 모델 성능은 훈련 중의 성능과 다를 수 있으므로 신중한 모니터링과 테스트가 필요합니다. 예상대로 작동하는지 확인하기 위해 유지보수 및 업데이트 계획을 수립하는 것도 중요합니다. 데이터와 모델 요구사항이 변경될 수 있기 때문입니다.
머신러닝 모델의 배포를 간편하게 만드는 한 가지 방법은 파이프라인을 사용하는 것입니다. 파이프라인은 데이터에 대해 수행되는 일련의 단계로 모델을 훈련하고 배포하는 것을 포함할 수 있습니다. 데이터 전처리, 모델 훈련, 성능 평가와 같은 작업이 이에 포함될 수 있습니다. 파이프라인을 사용하면 배포 과정을 간소화하고 효율적으로 만들 수 있습니다. ZenML 및 BentoML과 같은 도구를 사용하여 파이프라인을 구축하고 관리하며, 머신러닝 모델을 패키지화하고 배포함으로써 프로세스를 더욱 간편하게 만들 수 있습니다.
ZenML 파이프라인과 배포 통합을 사용하면 머신러닝 모델의 배포를 효율적이고 쉽게 진행할 수 있습니다. 머신러닝 모델 서빙 및 배포는 귀사의 훈련된 모델이 실시간으로 예측을 수행하고 비즈니스 결정에 영향을 미칠 수 있도록 하는 중요한 단계입니다. ZenML과 BentoML을 활용하여 ML 모델의 힘을 세계에 발휘할 준비를 하세요!
이 기사에서는 다음과 같은 내용을 배우게 됩니다:
- ZenML과 BentoML을 통합하여 설정하는 방법
- 로컬에서 모델을 훈련하고 배포하기 위한 파이프라인 정의
- 로컬에 배포된 모델을 Sagemaker (클라우드) 엔드포인트로 전환하는 방법
설치
ZenML: 이식 가능하고 제품 수준의 MLOps 파이프라인을 생성하기 위한 확장 가능한 오픈 소스 MLOps 프레임워크입니다. 데이터 과학자, ML 엔지니어 및 MLOps 개발자들이 제품 개발 과정에서 협업할 수 있도록 설계되었습니다. ZenML은 간단하고 유연한 구문을 갖추고 있으며, 클라우드 및 도구에 구애받지 않으며, ML 워크플로우에 맞추어진 인터페이스/추상화를 제공합니다. ZenML은 여러분이 좋아하는 도구들을 한 곳에 모아 여러분의 요구에 맞게 워크플로우를 조정할 수 있도록 합니다.
ZenML은 데이터 중심적이며 클라우드 도구에 구애받지 않도록 하기 위해 세 가지 핵심 개념으로 구성되어 있습니다. 이 개념들은 단계(Steps), 파이프라인(Pipelines), 스택(Stacks)입니다.
파이프라인: 파이프라인은 사용 사례에 맞게 어떤 순서로든 구성된 일련의 단계로 구성됩니다. 이러한 파이프라인과 단계는 Python 데코레이터나 클래스를 사용하여 코드로 정의됩니다.
스택: 스택은 파이프라인이 실행될 때 기반 인프라와 실행 방법에 대한 구성입니다. 예를 들어, 사용하는 스택을 변경함으로써 파이프라인을 로컬에서 실행할지 클라우드에서 실행할지 선택할 수 있습니다.
아래에서 이러한 개념들에 대해 더 자세히 알아보겠습니다. 그러나 먼저 ZenML을 설치해 보겠습니다. 필요한 작업은 단 한 줄입니다:
pip install zenml["server"]
# ZenML comes with a dashboard that we can lunch using:
zenml up
BentoML: 머신러닝 모델 서빙을 위한 오픈 소스 프레임워크입니다. 이를 사용하여 모델을 로컬 환경, 클라우드 환경 또는 Kubernetes 클러스터에 서빙하고 배포할 수 있습니다. BentoML은 조직 내에서 모델을 제품 환경에 배포하는 방식을 표준화하여 관리와 유지보수를 더욱 간편하게 만들어 줍니다.
BentoML을 설치하기 위해 우리는 ZenML의 integration CLI 명령어를 사용합니다. 이 명령어는 이 작업을 자동으로 처리해 줍니다.
zenml integration install bentoml
이제 두 도구를 모두 설치했으므로 파이프라인을 실행할 ZenML 스택을 생성하려고 합니다. ZenML에서 스택은 여러 개의 스택 구성 요소로 구성되며 다음과 같이 구성할 수 있습니다:
zenml model-deployer register bentoml_deployer --flavor=bentoml
zenml stack register local_bentoml_stack \
-a default \ # refers to the artifact-store stack component
-o default \ # refers to the orchestrator stack component
-d bentoml_deployer \ # refers to the model-deployer stack component
--set # sets the stack as the active stack
ZenML과 BentoML을 사용하여 모델을 배포하는 방법을 이해하기 위해 fashion-mnist 데이터셋에서 분류기를 훈련하는 데 PyTorch를 사용합니다.
전체 예제는 ZenML의 핵심 저장소에서 찾을 수 있습니다. 여기
스택 구성 요소, 통합 및 일반적인 ZenML에 대한 자세한 정보는 문서에서 찾을 수 있습니다. 여기
트레이닝 배포 파이프라인
이를 더욱 이해하기 쉽고 깔끔하게 만들기 위해 코드를 두 개의 다른 파이프라인으로 분리할 것입니다. 첫 번째 파이프라인은 훈련 파이프라인으로, 다음과 같이 6단계로 구성됩니다:
- Fashion-MNIST 데이터셋 로드: 이 단계에서는 Fashion-MNIST 데이터셋을 로드합니다. Fashion-MNIST는 이미지 분류 모델을 훈련하는 데 사용되는 인기 있는 예제 데이터셋입니다.
- 분류기 훈련: 이 단계에서는 선택한 머신러닝 알고리즘을 사용하여 Fashion-MNIST 데이터셋에서 분류기를 훈련합니다. 단순한 모델인 로지스틱 회귀부터 합성곱 신경망 (CNN)과 같은 더 복잡한 모델까지 사용할 수 있습니다.
- 평가자: 분류기를 훈련한 후, 평가자 단계를 사용하여 모델의 성능을 보유한 테스트 세트에서 평가합니다. 이를 통해 모델의 정확도, 정밀도 및 기타 메트릭을 평가하고 배포 준비 여부를 결정할 수 있습니다.
- 배포 트리거: 배포 트리거 단계는 모델을 언제와 어떻게 배포할지를 지정하는 데 사용됩니다. 이 단계를 사용하면 모델이 배포되기 전에 충족해야 할 테스트 세트에서의 모델 성능과 같은 특정 조건을 설정할 수 있습니다.
- Bento 빌더: bento_builder 단계는 훈련된 모델을 변환하고 패키징하여 쉽게 배포하고 제공할 수 있는 형식으로 변환합니다. 이 단계는 훈련된 모델을 로컬 머신이나 클라우드와 같은 다양한 환경에 쉽게 공유하고 배포할 수 있도록 해줍니다.
- 배포자: 배포자 단계는 이전 단계에서 패키징된 모델을 가져와 로컬 서버에 배포합니다.
이 파이프라인은 다음과 같이 정의할 수 있습니다:
@pipeline(enable_cache=False, settings={"docker": docker_settings})
def training_fashion_mnist(
importer,
trainer,
evaluator,
deployment_trigger,
bento_builder,
deployer,
):
"""Link all the steps and artifacts together"""
train_dataloader, test_dataloader = importer()
model = trainer(train_dataloader)
accuracy = evaluator(test_dataloader=test_dataloader, model=model)
decision = deployment_trigger(accuracy=accuracy)
bento = bento_builder(model=model)
deployer(deploy_decision=decision, bento=bento)
그런 다음 각 단계는 개별적으로 정의될 수 있습니다. 예를 들어 trainer 단계가 어떻게 정의되는지 살펴보겠습니다:
import torch
from torch import nn
from torch.utils.data import DataLoader
from neuralnetwork import NeuralNetwork
from zenml.steps import step
@step(enable_cache=True)
def trainer(train_dataloader: DataLoader) -> nn.Module:
"""Trains on the train dataloader"""
model = NeuralNetwork().to(DEVICE)
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
size = len(train_dataloader.dataset)
model.train()
for batch, (X, y) in enumerate(train_dataloader):
X, y = X.to(DEVICE), y.to(DEVICE)
# Compute prediction error
pred = model(X)
loss = loss_fn(pred, y)
# Backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch % 100 == 0:
loss, current = loss.item(), batch * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
return model
모델이 훈련된 후, 다음 단계는 bento_builder 단계입니다. 이 단계는 BentoML과 함께 모델을 배포하기 위해 준비하는 것을 더 쉽게 해주는 내장된 ZenML 단계입니다. 이 단계는 Bento를 빌드합니다. Bento는 모델, 요구사항 및 사용자 정의 전처리 및 후처리 코드를 하나의 파일로 패키징하여 모델을 어디에서든 배포할 수 있도록 합니다. bento_builder 단계는 다음과 같이 참조할 수 있습니다:
from zenml.integrations.bentoml.steps import (
BentoMLBuilderParameters,
bento_builder_step,
)
bento_builder = bento_builder_step(
params=BentoMLBuilderParameters(
model_name=MODEL_NAME,
model_type="pytorch",
service="service.py:svc",
labels={
"framework": "pytorch",
"dataset": "mnist",
"zenml_version": "0.21.1",
},
exclude=["data"],
python={
"packages": ["zenml", "torch", "torchvision"],
},
)
)
이 단계는 훈련된 모델을 가져와 배포에 사용할 수 있는 Bento 아티팩트를 생성합니다. 이 단계는 훈련된 모델을 쉽게 공유하고 다양한 환경에 배포할 수 있도록 해줍니다.
파이프라인의 마지막 단계는 배포 단계입니다. 이 단계는 훈련된 모델을 배포하기 위해 필요한 모든 것을 포함하는 Bento라는 패키지 파일을 배포합니다. 배포 단계는 또한 내장된 ZenML 단계로, 모델을 로컬 머신에 배포하기 위해 쉽게 참조할 수 있습니다:
from zenml.integrations.bentoml.steps import (
BentoMLDeployerParameters,
bentoml_model_deployer_step,
)
bentoml_model_deployer = bentoml_model_deployer_step(
params=BentoMLDeployerParameters(
model_name=MODEL_NAME,
port=3001,
production=False,
)
)
모든 이러한 단계와 파이프라인을 정의한 후에는 파이프라인을 실행할 수 있습니다. 이를 통해 다음과 같은 결과를 얻을 수 있습니다:
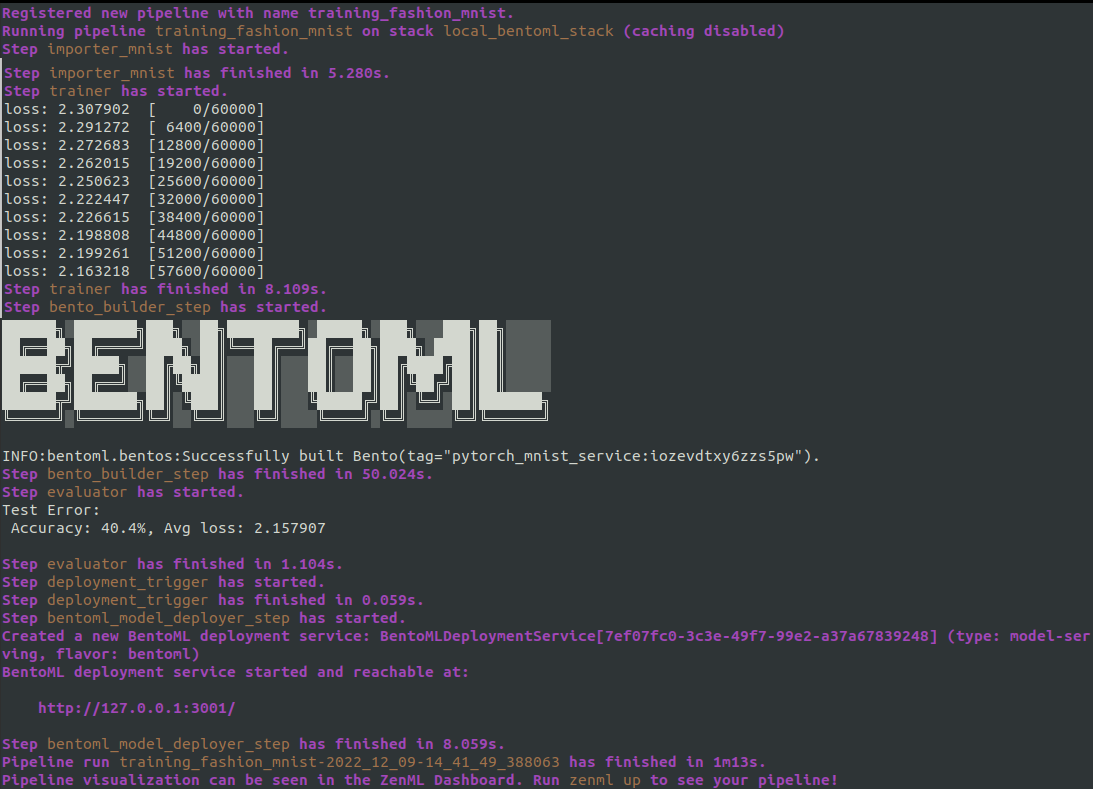
ZenML 대시보드에서는 파이프라인 DAG를 볼 수 있습니다.
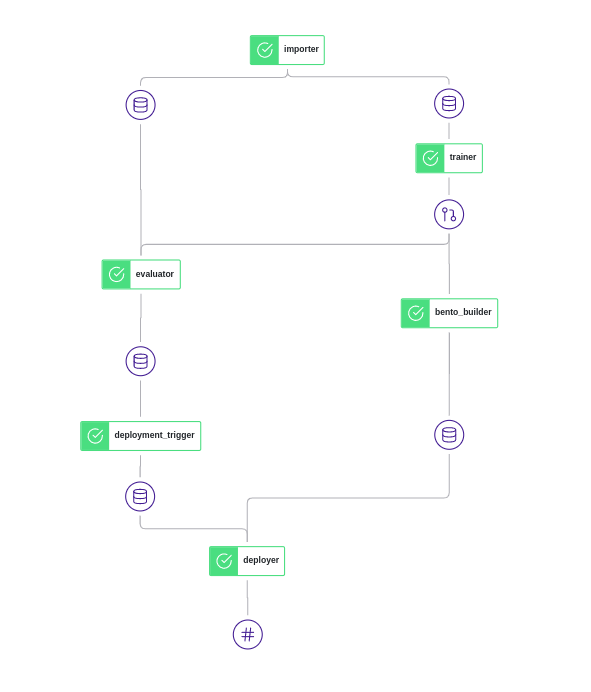
Swagger UI에서는 배포된 Bento에 대한 자세한 내용을 볼 수 있습니다.
로컬에서 클라우드로:
모델 서버가 로컬에서 배포되고 테스트되면, 클라우드 공급자에 bentoctl이라는 명령줄 인터페이스 (CLI) 도구를 사용하여 배포할 수 있습니다. Bentoctl은 클라우드 공급자에서 BentoML 배포를 관리하기 위한 도구로, 현재 AWS, GCP, Azure를 지원하며, 해당 공급자의 계정 및 해당 CLI 도구, Docker 및 Terraform이 설치된 상태여야 합니다.
bentoctl을 사용하려면 다음 명령을 사용하여 먼저 설치해야 합니다:
pip install bentoctl
이 예제에서는 ZenML을 사용하여 구축한 BentoML 모델을 AWS Sagemaker에 배포할 것입니다. 이를 위해 먼저 필요한 종속성을 설치해야 합니다:
zenml integration install aws s3
bentoctl operator install aws-sagemaker
이러한 종속성이 설치되면 다음 명령을 실행하여 BentoML 배포를 초기화할 수 있습니다:
bentoctl init
다음으로, 훈련 파이프라인에서 구축한 BentoML 모델을 사용하여 Docker 이미지를 빌드할 것입니다. 다음 명령을 사용하여 이 작업을 수행할 수 있습니다:
bentoctl build -b $BENTO_TAG -f $DEPLOYMENT_CONFIG_FILE
마지막으로, apply 명령을 실행하여 모델을 AWS Sagemaker에 배포할 수 있습니다:
bentoctl apply
이 예제의 전체 코드는 GitHub에서 확인할 수 있습니다.
결론적으로, 머신러닝 모델을 훈련하고 배포하는 것은 복잡하고 시간이 많이 소요되는 과정일 수 있습니다. ZenML 파이프라인과 BentoML 통합을 사용함으로써 이 과정을 간소화하고 모델을 로컬 및 클라우드에 쉽게 배포할 수 있었습니다. 이를 통해 우리는 모델을 빠르고 쉽게 테스트하고 배포할 수 있었으며, 소중한 시간과 자원을 절약할 수 있었습니다. 전반적으로 ZenML과 BentoML의 사용은 머신러닝 워크플로우에서 가치 있는 도구로 증명되었습니다.