Article Source
Active Metadata Management
액티브 메타데이터 플랫폼의 분석
액티브 메타데이터는 가트너 (Gartner)의 최신 카테고리로, 오늘날의 증강 데이터 카탈로그에서 획기적인 도약을 이루었습니다.
개요
메타데이터 관리 분야에 혼란이 일고 있습니다. 가트너는 메타데이터 관리 솔루션 매직 쿼드란트를 없애고 액티브 메타데이터 시장 가이드로 대체했습니다. 차이점이 명확하나요? 이 변화를 통해 가트너는 액티브 메타데이터를 미래를 위한 새로운 카테고리로 선보였습니다.
데이터 생태계의 새로운 카테고리와 마찬가지로 이 발표는 엄청난 흥분과 건강한 회의론, 그리고 수많은 질문을 동반합니다.
- 액티브 메타데이터란 정확히 무엇인가요?
- 강화된 데이터 카탈로그 및 이전에 본 기술과 어떻게 다른가요?
- 액티브 메타데이터 플랫폼은 어떻게 생겼나요?
오늘은 이 추상적인 논의에서 한 걸음 더 나아가 액티브 메타데이터 플랫폼이 어떻게 생겼는지 그림을 그리고, 중요한 구성 요소를 분석하고, 액티브 메타데이터의 실제 사용 사례를 몇 가지 제시하고 싶습니다.
액티브 메타데이터 플랫폼은 어떻게 생겼나요?
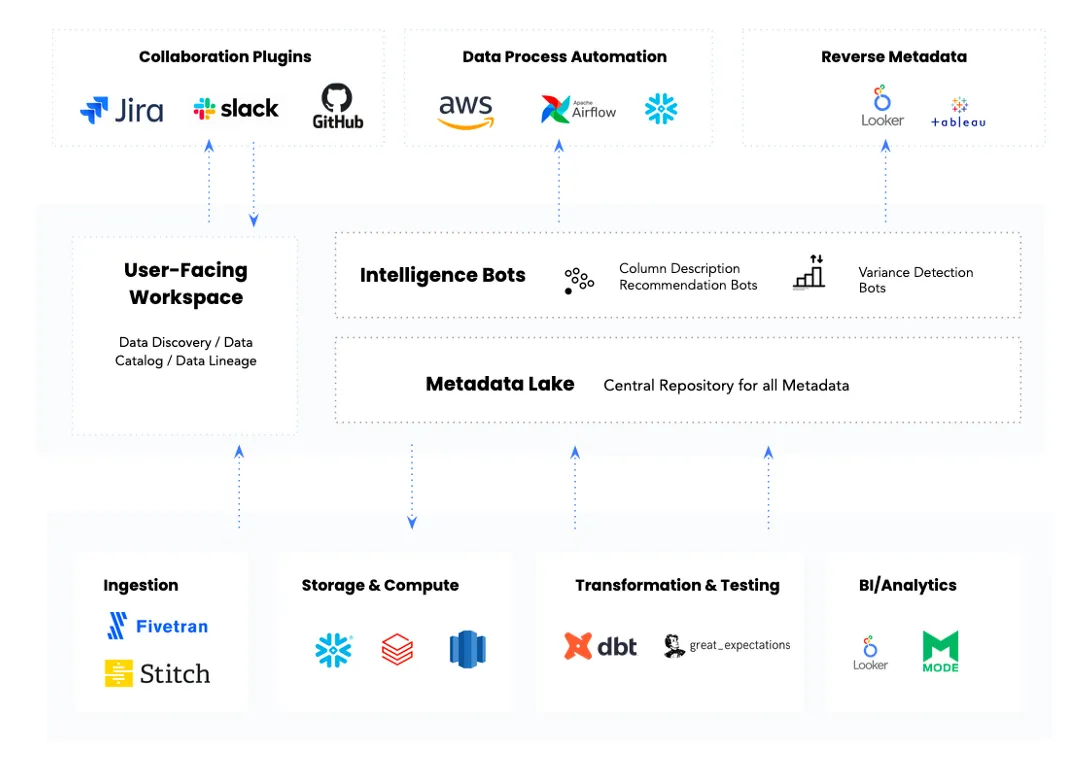 The architecture of an active metadata platform. (Image from Atlan.)
The architecture of an active metadata platform. (Image from Atlan.)
저는 액티브 메타데이터 플랫폼에는 5가지 핵심 구성 요소가 있다고 생각합니다.
- 메타데이터 레이크: 모든 종류의 메타데이터를 저장하는 통합 저장소입니다. 이 저장소는 원시 형태와 처리된 형태 모두 가능하며, 개방형 API를 기반으로 구축되고 지식 그래프로 구동됩니다.
- 프로그래밍 가능 인텔리전스 봇: 팀이 사용자 정의 ML 또는 데이터 과학 알고리즘을 만들어 인텔리전스를 구동할 수 있는 프레임워크입니다.
- 임베디드 협업 플러그인: 공통 메타데이터 레이어에 의해 통합된 일련의 통합으로, 모든 데이터 팀의 일상 워크플로와 데이터 도구를 완벽하게 통합합니다.
- 데이터 프로세스 자동화: 인간의 의사 결정 프로세스를 모방하여 데이터 생태계를 관리하는 워크플로 자동화 봇을 쉽게 구축, 배포, 관리하는 방법입니다.
- 역방향 메타데이터: 사용자가 필요할 때마다 독립형 카탈로그가 아닌 어디 어디서나 관련 메타데이터를 이용할 수 있도록 오케스트레이션하는 기능입니다.
1. 메타데이터 레이크: 중앙 메타데이터 저장소
몇 분기 전, 저는 메타데이터 레이크의 개념에 대해 글을 썼습니다. 이는 모든 종류의 메타데이터를 원시 및 더욱 처리된 형태로 저장하는 통합 저장소이며, 오늘날 우리가 알고 있는 사용 사례와 미래의 사용 사례 모두를 구동하는 데 사용될 수 있습니다.
액티브 메타데이터는 기존의 “수동적인” 기술을 벗어나 적극적으로 메타데이터를 찾고, 풍부하게 하고, 목록을 작성하고 사용하는 전제 위에 구축되어 진정한 행동 지향적인 기술로 만들었습니다.
액티브 메타데이터 플랫폼의 핵심인 메타데이터 레이크는 다음과 같은 두 가지 중요한 특징을 가지고 있습니다.
- 개방형 API 및 인터페이스: 메타데이터 레이크는 단순한 데이터 저장소가 아니라 개방형 API를 통해 쉽게 액세스할 수 있어야 합니다. 이를 통해 현대 데이터 스택의 모든 단계에서 단일 메타데이터 저장소를 간편하게 활용하여 검색, 관찰, 계보와 같은 다양한 사용 사례를 구동할 수 있습니다.
- 지식 그래프로 구동: 메타데이터의 진정한 잠재력은 데이터 자산 간의 모든 연결이 활성화될 때 풀리게 됩니다. Google, Facebook, Uber와 같은 세계 최대 인터넷 회사를 구동하는 지식 그래프 아키텍처는 이러한 메타데이터 연결을 실현시키는 가장 유력한 후보입니다.
2. 프로그래밍 가능 인텔리전스 봇
우리는 메타데이터 자체가 빅 데이터가 되는 세상에 빠르게 접근하고 있으며, 이 메타데이터를 이해하는 것은 현대 데이터 관리 생태계를 만드는 데 중요한 핵심입니다.
메타데이터 인텔리전스는 데이터 라이프사이클의 모든 측면에 영향을 미칠 수 있는 잠재력을 가지고 있습니다. SQL 쿼리 로그를 파싱하여 자동으로 열 수준 계보를 만들 수 있습니다. 개인 식별 정보(PII) 데이터를 자동으로 식별하여 개인 정보를 보호할 수 있습니다. 또한 데이터 이상 및 변칙을 자동으로 감지하여 나쁜 데이터를 미리 잡을 수 있습니다. 최근 몇 년 동안 메타데이터 분야에서는 몇 가지 혁신이 있었으며 “강화된” 데이터 카탈로그가 점점 더 인기를 얻고 있습니다.
하지만 이 모든 열풍 속에서 저는 데이터 관리에 인텔리전스를 적용하는 방법에 대해 아직까지 잘못된 부분이 있다고 생각합니다. 바로 “한 사이즈는 모든 것에 맞지 않는다”는 것입니다.
모든 회사는 독특합니다. 모든 산업은 독특합니다. 각 팀의 데이터는 독특합니다.
최근 데이터 책임자와의 통화에서 그는 데이터 품질 이상을 감지하는 도구에 대해 비판했습니다. “때로는 도구가 스키마 변경 및 품질 문제에 대한 유용한 알림을 보내주지만, 다른 경우에는 무의미한 것에 대해 소리를 내 어 데이터 엔지니어링 팀을 실망시킨다”고 말했습니다.
저는 도구를 비난하지 않습니다. 사실 모든 머신 러닝 알고리즘의 출력은 입력되는 학습 데이터의 함수입니다. 어떤 알고리즘도 마술처럼 맥락을 만들고, 이상을 식별하고, 모든 산업, 모든 회사, 모든 사용 사례에 대해 100% 성공할 수 있는 지능형 데이터 관리 꿈을 이룰 수는 없습니다. 제가 얼마나 원하더라도 완벽한 해결책은 없습니다.
그래서 저는 액티브 메타데이터 플랫폼에서 인텔리전스의 미래는 마술처럼 모든 문제를 해결하는 단일 알고리즘이 아니라 팀이 서로 다른 맥락과 사용 사례에 쉽게 맞춤 설정할 수 있는 프로그래밍 가능 인텔리전스 봇을 만들 수 있는 프레임워크라고 믿습니다.
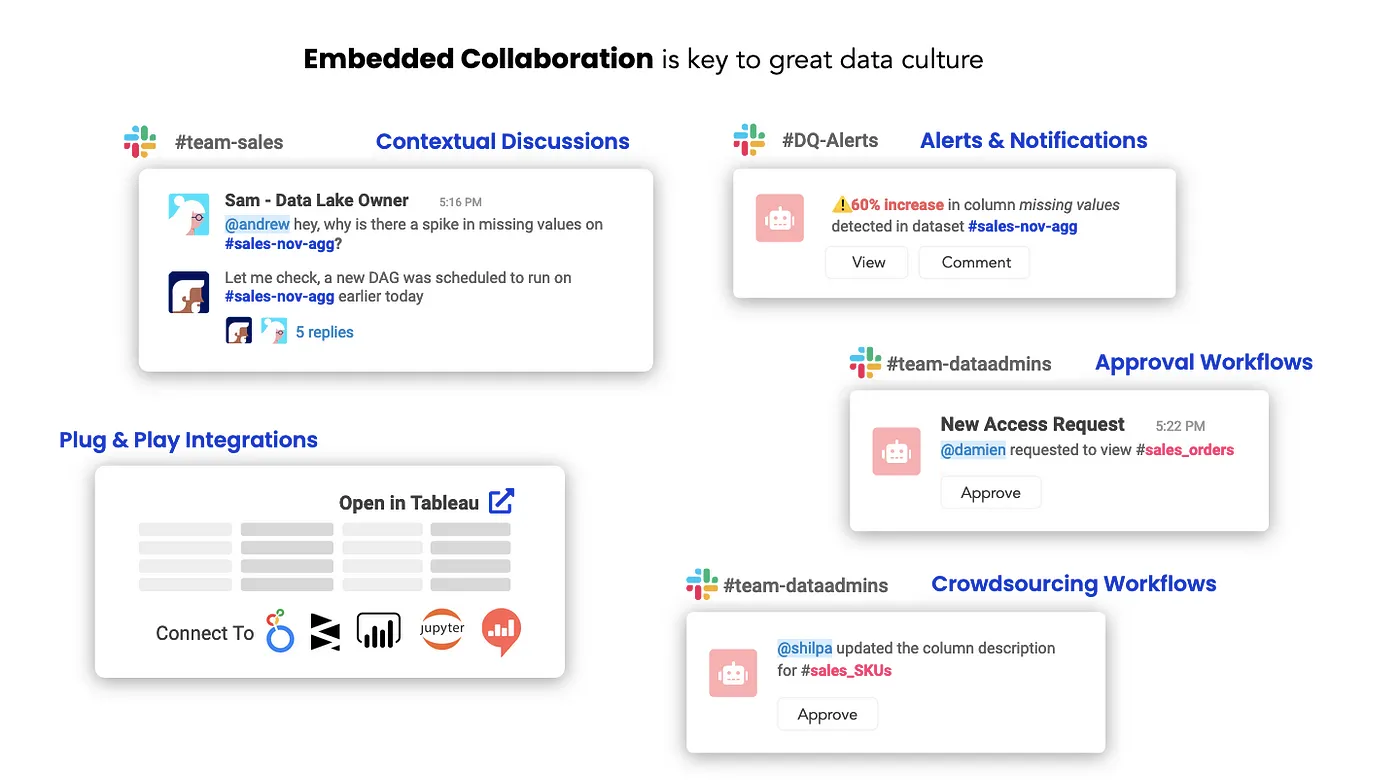 What embedded collaboration could look like.(Image from Atlan.)
What embedded collaboration could look like.(Image from Atlan.)
프로그래밍 가능 인텔리전스 봇의 몇 가지 예시는 다음과 같습니다.
- 보안 및 규정 준수 요구 사항 자동화: 보안 및 규정 준수 요구 사항이 주류가 되면서 회사는 더 많은 규칙을 따라야 합니다. 예를 들면, 의료 데이터의 HIPAA 및 은행의 BCBS 239와 같은 업계별 규칙이나 유럽의 GDPR, 캘리포니아의 CCPA와 같은 지역별 규칙이 있습니다. 봇은 각 회사에 적용되는 규정에 따라 민감한 데이터 열을 식별하고 태그를 지정하는 데 사용할 수 있습니다.
- 데이터 세트의 조직화: 특정 데이터 세트 명명 규칙을 가진 회사는 미리 설정된 규칙에 따라 데이터 생태계를 자동으로 구성, 분류 및 태그 지정하는 봇을 만들 수 있습니다.
- 데이터 품질 관리: 기업은 사전 구축된 관찰 및 데이터 품질 알고리즘을 활용하여 데이터 생태계 및 사용 사례에 맞게 사용자 지정할 수 있습니다.
프로그래밍 가능 인텔리전스의 사용 사례는 무궁무진하며, 앞으로 어떤 일이 펼쳐질지 매우 기대됩니다!
3. 임베디드 협업 플러그인
오늘날 데이터 팀은 그 어느 때보다 다양합니다. 데이터 엔지니어, 분석가, 분석 엔지니어, 데이터 과학자, 제품 관리자, 비즈니스 분석가, 시민 데이터 과학자 등으로 구성되어 있습니다.
이 다양한 데이터 팀은 SQL, Looker, Jupyter부터 Python, Tableau, dbt, R에 이르기까지 다양한 데이터 도구를 사용합니다. 여기에 엄청난 협업 도구 (Slack, JIRA, 이메일 등)를 추가하면 데이터 전문가의 삶은 악몽이 됩니다.
데이터 팀의 근본적인 다양성 때문에 데이터 도구는 각 팀의 일상 워크플로와 완벽하게 통합되도록 설계되어야 합니다.
이것이 임베디드 협업이라는 아이디어가 살아나는 곳입니다. 도구 간의 전환보다는 임베디드 협업은 마찰과 컨텍스트 전환을 줄이며 각 데이터 팀 구성원이 거주하는 곳에서 작업이 이루어집니다.
임베디드 협업의 몇 가지 예시:
- Google 문서처럼 링크를 통해 데이터 자산에 대한 액세스를 요청할 수 있고, 소유자는 Slack에서 요청을 받고 바로 거부하거나 승인할 수 있다면 어떨까요?
- 데이터 자산을 검토하고 문제를 보고해야 할 때, 엔지니어링 팀의 JIRA 워크플로와 완벽하게 통합된 지원 요청을 트리거할 수 있다면 어떨까요?
액티브 메타데이터 플랫폼의 액션 레이어는 마침내 임베디드 협업을 살아나게 할 것입니다. 저는 이 레이어를 현대 데이터 스택을 위한 Zapier로 보고, 공통 메타데이터 레이어에 의해 통합되고 팀이 고유한 워크플로에 맞게 앱을 사용자 정의할 수 있게 합니다.
4. 데이터 프로세스 자동화
몇 년 전, 봇 자동화(RPA)라는 새로운 카테고리의 도구가 기업 세계를 강타했습니다. UiPath의 RPA는 “소프트웨어 로봇을 쉽게 구축, 배포, 관리할 수 있게 하는 소프트웨어 기술로, 이 로봇은 디지털 시스템과 소프트웨어와 상호 작용하는 인간의 행동을 모방합니다.”
데이터 패브릭, 데이터 메쉬, DataOps와 같은 개념이 데이터 플랫폼에 대한 인식 방식에서 주류화됨에 따라 데이터 프로세스 자동화 (DPA) 필요성이 증가할 것입니다. DPA는 워크플로 자동화 봇을 쉽게 구축, 배포, 관리하여 인간의 의사 결정 프로세스나 행동을 모방하고 데이터 생태계를 관리할 수 있게 합니다.
월요일 아침에 대시보드 로딩 속도에 실망을 느껴본 적이 있나요? 더 나쁜 것은 월말 엄청난 AWS 청구서에 놀란 적이 있나요?
액티브 메타데이터 플랫폼을 사용하면 이런 일이 두 번 다시 일어나지 않을 세상을 상상하기 어렵지 않습니다. 진정한 액티브 메타데이터 플랫폼은 리소스 할당 및 작업 관리와 같은 운영을 위한 인접 데이터 관리 도구에 매개변수화된 지침을 권장할 수 있습니다.
예를 들어, BI 도구의 최고 BI 대시보드 사용 시간, 데이터 파이프라인 도구의 과거 데이터 파이프라인 실행 통계, 웨어하우스의 과거 계산 성능과 같은 다양한 출처의 메타데이터를 활용하여 액티브 메타데이터 플랫폼이 Snowflake 웨어하우스 확장을 위한 매개변수만 추천하는 것이 아니라 실제로 DPA를 활용하여 웨어하우스 리소스를 할당하는 세상을 상상할 수 있습니다.
5. 역방향 메타데이터
저는 지난 몇 년간 가장 큰 일 중 하나는 놀라운 사용자 경험이 모든 것을 압도한다고 믿는 진정한 “현대 데이터 스택” 회사와 기업가들의 등장이라고 생각합니다.
예전에는 “가치 포획”에 관한 것이었지만, 새로운 기업가들은 최종 사용자 경험을 우선으로 “가치 창출”에 초점을 맞추고 있습니다. 현대 데이터 스택 회사는 제품 로드맵을 통합하고 더 나은 사용자 경험을 만들기 위해 서로 진정으로 파트너십을 맺는 데 점점 더 관심을 가지고 있습니다.
액티브 메타데이터는 이러한 파트너십을 진정으로 잠금 해제하는 열쇠를 보유하고 있으며, 제가 ‘역방향 메타데이터’가 게임을 바꿀 것이라고 생각하는 부분입니다.
역방향 메타데이터는 메타데이터가 “독립형 데이터 카탈로그”에서 사용 가능하지 않은 것에 관한 것입니다. 대신, 필요할 때마다 어디서나 관련 메타데이터를 최종 사용자에게 제공하여 작업을 더 잘 수행하도록 돕는 것입니다.
예를 들어, Atlan에서 Looker와의 역방향 메타데이터 통합은 Looker 내에서 직접 “컨텍스트”(예: 대시보드 소유자, 지표 정의 및 문서 등)를 보여줍니다.
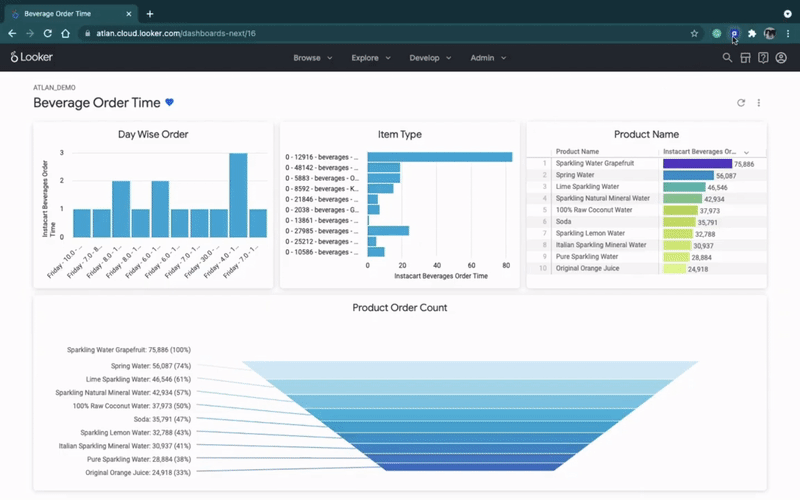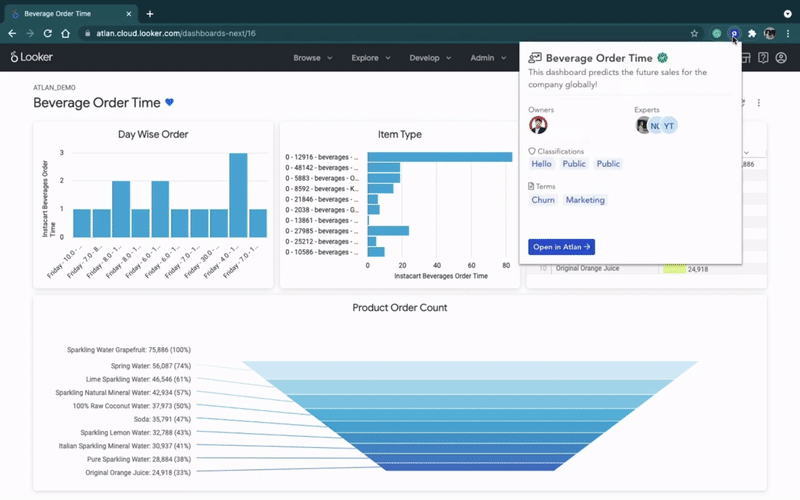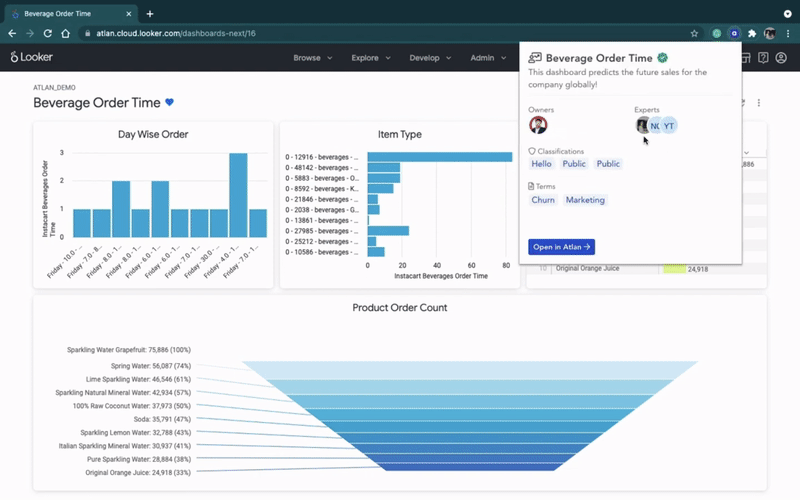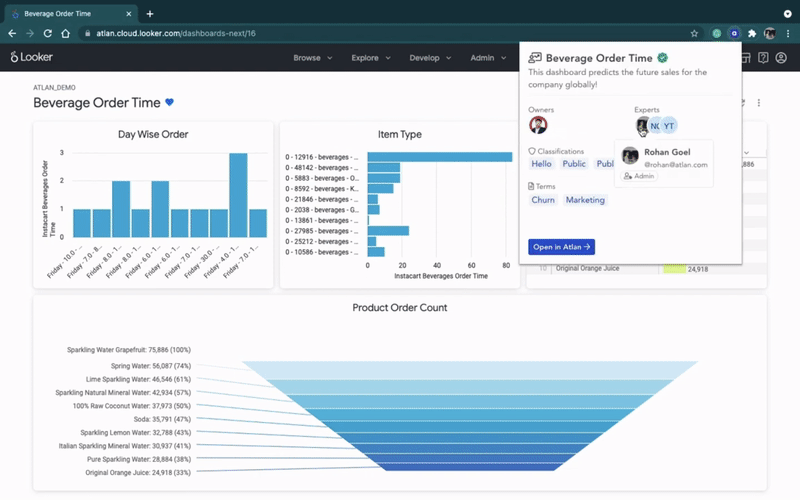 Reverse metadata in Looker. (GIF from Atlan.)
Reverse metadata in Looker. (GIF from Atlan.)
액티브 메타데이터 플랫폼은 현대 데이터 스택 전반에서 유용한 메타데이터를 조율하여 스택의 모든 다양한 도구를 더욱 유용하게 만들 수 있습니다. 이는 도구 간의 맞춤형 통합에 투자하지 않고도 가능합니다.
요약
이 글은 액티브 메타데이터 플랫폼에 대해 설명하고 이 기술이 현대 데이터 스택에 어떻게 영향을 미칠지 분석합니다. 주요 내용은 다음과 같습니다.
- 전통적인 메타데이터 관리 플랫폼은 “수동적”이었지만, 액티브 메타데이터 플랫폼은 메타데이터를 찾고, 풍부하게 하고, 관리하며 사용하는 과정을 적극적으로 활성화합니다.
- 액티브 메타데이터 플랫폼은 5가지 핵심 요소로 구성됩니다.
- 메타데이터 레이크: 모든 종류의 메타데이터를 저장하는 통합 저장소입니다.
- 프로그래밍 가능 인텔리전스 봇: 쉽게 맞춤 설정할 수 있는 인공 지능 알고리즘을 개발하여 데이터 정리, 품질 관리 등 다양한 작업을 자동화합니다.
- 임베디드 협업 플러그인: 서로 다른 데이터 도구를 사용하는 팀 간의 협업을 원활하게 합니다.
- 데이터 프로세스 자동화: 반복적인 작업을 자동화하여 데이터 관리 효율을 높입니다.
- 역방향 메타데이터: 필요한 메타데이터를 사용자가 필요한 곳에서 바로 액세스할 수 있도록 합니다.
- 액티브 메타데이터 플랫폼은 데이터 스택의 모든 도구를 더욱 유용하게 만드는 “메타데이터 어디서나” 옴니채널 경험을 제공합니다.
- 액티브 메타데이터 플랫폼은 5가지 핵심 요소로 구성됩니다.
결론
글쓴이는 액티브 메타데이터가 미래 데이터 생태계의 핵심 요소라고 생각하며, 이 기술이 발전함에 따라 데이터 관리 방식에 혁신적인 변화가 일어날 것으로 예측합니다. 이 글은 액티브 메타데이터 플랫폼이 어떻게 작동하는지, 어떤 혜택을 제공하는지에 대한 이해를 돕고 미래의 가능성을 제시합니다.