Impedance Mismatch: 객체-관계 불일치
관계형 데이터베이스는 장점이 많지만 완벽하지는 않으며, 초창기부터 많은 불만이 있었다.
애플리케이션 개발자에게 가장 큰 불만은 객체-관계 불일치, 즉 관계형 모델과 메모리 내 데이터 구조 간 차이였다. 관계형 데이터 모델에서는 테이블과 행, 즉 관계와 튜플로 데이터를 구조화한다. 관계형 모델에서 튜플은 이름-값 쌍의 집합이고 관계는 튜플의 집합이다(튜플의 관계형 정의는 튜플을 값들의 나열로 정의하는 수학이나 다른 프로그래밍 언어에서의 튜플 데이터 타입과는 조금 다르다). SQL에서 모든 연산은 관계를 소비하고 반환하는데, 모든 것이 수학적으로 우아한 관계 대수로 설명된다.
관계에 대한 이런 기반은 어느 정도의 우아함과 단순함을 제공하지만 제약도 생긴다. 특히 관계형 튜플 안의 값은 단순해야 하며, 중첩된 레코드나 리스트 등 다른 구조를 포함할 수 없다. 메모리 내 데이터 구조에서는 이런 제약이 없어 관계보다 훨씬 복잡한 구조를 사용할 수 있다. 그 결과 복잡한 메모리 내 데이터 구조를 데이터베이스에 저장하려면 먼저 관계형 표현으로 변환해야 한다.
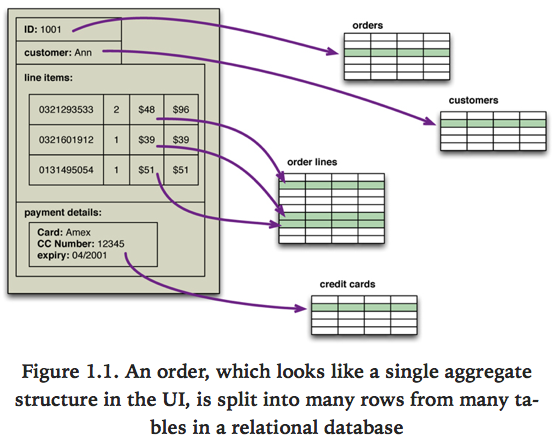
객체-관계 불일치는 애플리케이션 개발자에게 가장 큰 불만이었고, 1990년대에는 많은 사람이 관계형 데이터베이스가 메모리 내 데이터 구조를 그대로 디스크에 저장하는 새로운 데이터베이스로 대체되리라 믿었다. 이때는 객체 지향 프로그래밍 언어가 성장하던 시기였고, 이와 함께 객체 지향 데이터베이스가 등장 했는데, 둘 다 새 천년의 소프트웨어 개발에 지배적 환경이 될 것으로 보였다.
그러나 객체 지향 언어는 성공해 프로그래밍 주류가 된 반면, 객체 지향 데이터베이스는 세상에서 잊혀졌다. 관계형 데이터베이스는 통합 방법으로서의 역할 강조, 데이터 조작을 위한 표준 언어(SQL) 지원, 애플리케이션 개발자와 데이터베이스 관리자 직종 분리 심화 등의 요인에 힘입어 이 도전을 이겨냈다.
잘 알려진 매핑 패턴을 구현한 하이버네이트(Hibernate)나 아이바티스(iBATIS)은 같은 객체-관계 매핑 프레임워크가 널리 사용되면서 객체-관계 불일치는 완화되었지만, 매핑 문제는 여전히 논쟁거리다. 객체-관계 매핑 프레임워크로 지겨운 작업은 많이 줄었지만, 데이터베이스나 쿼리 성능 같은 것을 지나치게 무시하면 다른 문제가 생길 수 있다.
관계형 데이터베이스는 2000년대에도 엔터프라이즈 컴퓨팅 분야를 계속 지배했지만, 바로 이 시기 지배에 틈새가 생기기 시작했다.
References
[1] Pramod J. Sadalage, Martin Fowler, NoSQL Distilled, A Brief Guide to the Emerging World of Polyglot Persistence, Pearson Education, Inc, 2012.