When you are processing large volumes of data, a large proportion of the data may be considered to be irrelevant to your analysis. For example, you may only be interested in infrequent, unusual occurrences within the data streams.
In this case, a Streams Application can be used to filter the data, reducing it to the items of significance. The application might analyze the data stream, identify the elements of interest, and create a new stream of data from the significant items. With this new stream, a reduced number of these valuable parts will be processed by the remainder of the Streams Application.
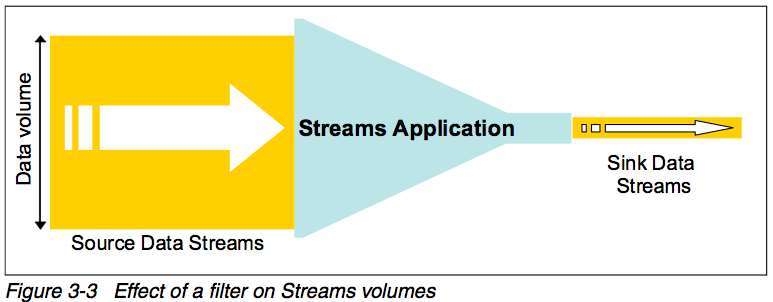
Figure 3-3 shows the principle of the Filter pattern. The application reduces the volume of data so that the output is more manageable.
###Example In financial services, you might be interested in price changes for stocks in your stock portfolio. You can consume a feed of data from the stock market and use a filter to reduce this feed down to only the stocks of interest to you.
In a health care situation, a large volume of readings will be generated from medical sensors. These will usually stay within an expected range, but when they fall outside this range, an alert needs to be raised. A filter can be used to detect the dangerous sensor readings.
###Stereotype A simple implementation of the Filter design pattern illustrating value identification and extraction is shown in Figure 3-4. In this illustration, a Source Operator reads in the data stream and a Functor Operator is used to determine the Tuples of interest and only passes these on to the Sink Operator, which sends theses to the relevant recipients.

####Stereotype walkthrough Here are brief descriptions of the steps involved in the stereotype:
- A Source Operator reads in the data stream from the
input.datfile, creating the unfilteredInput stream. - A Functor Operator processes the unfilteredInput stream and determines the Tuples of interest, in this case those strings that are greater than the string
Interesting Data. The output stream from the Functor is the FilteredOutput stream and only contains the Tuples of interest. - A Sink Operator takes the FilteredOutput stream and outputs the data to a file named
output.dat;this data will be used by relevant recipients.
###Variations There might be variations in the process, but they may be handled by the following types of options:
- The filtering logic offered by the standard Functor Operator can be extended by adding user defined logic, allowing the maintenance of state variables and the use of control logic (such as loops and if-else conditions).
- For more complex analysis, the Functor Operator may be expanded into multiple Operators, processing the stream in multiple serial or parallel steps.
Some sample code that illustrates how that implementation might be supported is shown in Example 3-1.
Example 3-1
===========
[Application]
Filter
[Program]
stream UnfilteredInput (schemafor(Schema))
:= Source ()
["file:///input.dat", csvformat, nodelays]
{}
stream FilteredOutput (schemafor(Schema))
:= Functor (UnfilteredInput)
[field = "Interesting Data"]
{}
Nil := Sink (FilteredOutput)
["file:///output.dat", csvformat, nodelays]
{}
###Suggestions When processing high volume streams, you should consider filtering the streams to reduce their volumes as soon as possible after they are ingested. This can reduce the total processing workload of the Application, allowing a higher volume of throughput, with lower latency and potentially using less hardware.
Figure 3-5 shows two contrasting filtering approaches. The top diagram shows a Streams Application that filters the Source streams early on in its processing and the bottom diagram shows a Streams Application that filters the Source streams later on in its processing.
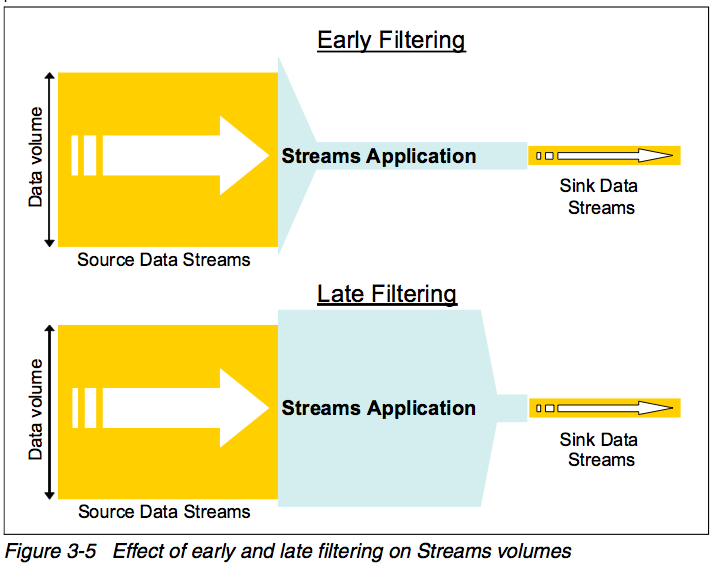
In these figures, the area depicted as the Streams Application is proportional to the amount of processing that the application needs to perform. In the early filtering case, most of the Streams Application only has a small number of data Tuples to process, so the shaded area is relatively small. In the late filtering case, most of the Streams Application has a large number of data Tuples to process, so that area is far larger, indicating a greater processing workload for the application.
###References
[1] Chuck Ballard et. al, IBM InfoSphere Streams: Harnessing Data in Motion, IBM Redbooks, pp.88, September 2010.