Related Web Sites
Parallel Computing
Parallel computing is a form of computation in which many calculations are carried out simultaneously,[1] operating on the principle that large problems can often be divided into smaller ones, which are then solved concurrently (“in parallel”). There are several different forms of parallel computing: bit-level, instruction level, data, and task parallelism. Parallelism has been employed for many years, mainly in high-performance computing, but interest in it has grown lately due to the physical constraints preventing frequency scaling.[2] As power consumption (and consequently heat generation) by computers has become a concern in recent years,[3] parallel computing has become the dominant paradigm in computer architecture, mainly in the form of multi-core processors.[4]
Parallel computers can be roughly classified according to the level at which the hardware supports parallelism, with multi-core and multi-processor computers having multiple processing elements within a single machine, while clusters, MPPs, and grids use multiple computers to work on the same task. Specialized parallel computer architectures are sometimes used alongside traditional processors, for accelerating specific tasks.
Parallel computer programs are more difficult to write than sequential ones,[5] because concurrency introduces several new classes of potential software bugs, of which race conditions are the most common. Communication and synchronization between the different subtasks are typically some of the greatest obstacles to getting good parallel program performance.
The maximum possible speed-up of a single program as a result of parallelization is known as Amdahl’s law.
Background
Traditionally, computer software has been written for serial computation. To solve a problem, an algorithm is constructed and implemented as a serial stream of instructions. These instructions are executed on a central processing unit on one computer. Only one instruction may execute at a time—after that instruction is finished, the next is executed.[6]
Parallel computing, on the other hand, uses multiple processing elements simultaneously to solve a problem. This is accomplished by breaking the problem into independent parts so that each processing element can execute its part of the algorithm simultaneously with the others. The processing elements can be diverse and include resources such as a single computer with multiple processors, several networked computers, specialized hardware, or any combination of the above.[6]
Frequency scaling was the dominant reason for improvements in computer performance from the mid-1980s until 2004. The runtime of a program is equal to the number of instructions multiplied by the average time per instruction. Maintaining everything else constant, increasing the clock frequency decreases the average time it takes to execute an instruction. An increase in frequency thus decreases runtime for all compute-bound programs.[7]
However, power consumption by a chip is given by the equation P = C × V2 × F, where P is power, C is the capacitance being switched per clock cycle (proportional to the number of transistors whose inputs change), V is voltage, and F is the processor frequency (cycles per second).[8] Increases in frequency increase the amount of power used in a processor. Increasing processor power consumption led ultimately to Intel’s May 2004 cancellation of its Tejas and Jayhawk processors, which is generally cited as the end of frequency scaling as the dominant computer architecture paradigm.[9]
Moore’s Law is the empirical observation that transistor density in a microprocessor doubles every 18 to 24 months.[10] Despite power consumption issues, and repeated predictions of its end, Moore’s law is still in effect. With the end of frequency scaling, these additional transistors (which are no longer used for frequency scaling) can be used to add extra hardware for parallel computing.
Amdahl’s law and Gustafson’s law

A graphical representation of Amdahl’s law. The speed-up of a program from parallelization is limited by how much of the program can be parallelized. For example, if 90% of the program can be parallelized, the theoretical maximum speed-up using parallel computing would be 10x no matter how many processors are used.
Optimally, the speed-up from parallelization would be linear—doubling the number of processing elements should halve the runtime, and doubling it a second time should again halve the runtime. However, very few parallel algorithms achieve optimal speed-up. Most of them have a near-linear speed-up for small numbers of processing elements, which flattens out into a constant value for large numbers of processing elements.
The potential speed-up of an algorithm on a parallel computing platform
is given by Amdahl’s law,
originally formulated by Gene Amdahl
in the 1960s.[11] It states that a small portion of
the program which cannot be parallelized will limit the overall speed-up
available from parallelization. A program solving a large mathematical
or engineering problem will typically consist of several parallelizable
parts and several non-parallelizable (sequential) parts. If
 is the fraction of running time a program spends on non-parallelizable
parts, then:
is the fraction of running time a program spends on non-parallelizable
parts, then:

is the maximum speed-up with parallelization of the program. If the
sequential portion of a program accounts for 10% of the runtime
( ),
we can get no more than a 10× speed-up, regardless of how many
processors are added. This puts an upper limit on the usefulness of
adding more parallel execution units. ”When a task cannot be partitioned
because of sequential constraints, the application of more effort has no
effect on the schedule. The bearing of a child takes nine months, no
matter how many women are assigned.”[12]
),
we can get no more than a 10× speed-up, regardless of how many
processors are added. This puts an upper limit on the usefulness of
adding more parallel execution units. ”When a task cannot be partitioned
because of sequential constraints, the application of more effort has no
effect on the schedule. The bearing of a child takes nine months, no
matter how many women are assigned.”[12]
Gustafson’s law is another
law in computing, closely related to Amdahl’s
law.[13] It states that the speedup with
 processors is
processors is

Assume that a task has two independent parts, A and B. B takes roughly 25% of the time of the whole computation. With effort, a programmer may be able to make this part five times faster, but this only reduces the time for the whole computation by a little. In contrast, one may need to perform less work to make part A twice as fast. This will make the computation much faster than by optimizing part B, even though B got a greater speed-up (5× versus 2×).

Both Amdahl’s law and Gustafson’s law assume that the running time of the sequential portion of the program is independent of the number of processors. Amdahl’s law assumes that the entire problem is of fixed size so that the total amount of work to be done in parallel is also independent of the number of processors, whereas Gustafson’s law assumes that the total amount of work to be done in parallel varies linearly with the number of processors.
Dependencies
Understanding data dependencies is fundamental in implementing parallel algorithms. No program can run more quickly than the longest chain of dependent calculations (known as the critical path), since calculations that depend upon prior calculations in the chain must be executed in order. However, most algorithms do not consist of just a long chain of dependent calculations; there are usually opportunities to execute independent calculations in parallel.
Let P~i~ and P~j~ be two program segments. Bernstein’s conditions[14] describe when the two are independent and can be executed in parallel. For P~i~, let I~i~ be all of the input variables and O~i~ the output variables, and likewise for P~j~. P ~i~ and P~j~ are independent if they satisfy



Violation of the first condition introduces a flow dependency, corresponding to the first segment producing a result used by the second segment. The second condition represents an anti-dependency, when the second segment (P~j~) produces a variable needed by the first segment (P~i~). The third and final condition represents an output dependency: When two segments write to the same location, the result comes from the logically last executed segment.[15]
Consider the following functions, which demonstrate several kinds of dependencies:
1: function Dep(a, b)
2: c := a·b
3: d := 3·c
4: end function
Operation 3 in Dep(a, b) cannot be executed before (or even in parallel with) operation 2, because operation 3 uses a result from operation 2. It violates condition 1, and thus introduces a flow dependency.
1: function NoDep(a, b)
2: c := a·b
3: d := 3·b
4: e := a+b
5: end function
In this example, there are no dependencies between the instructions, so they can all be run in parallel.
Bernstein’s conditions do not allow memory to be shared between different processes. For that, some means of enforcing an ordering between accesses is necessary, such as semaphores, barriers or some other synchronization method.
Race conditions, mutual exclusion, synchronization, and parallel slowdown
Subtasks in a parallel program are often called threads. Some parallel computer architectures use smaller, lightweight versions of threads known as fibers, while others use bigger versions known as processes. However, “threads” is generally accepted as a generic term for subtasks. Threads will often need to update some variable that is shared between them. The instructions between the two programs may be interleaved in any order. For example, consider the following program:
Thread A Thread B 1A: Read variable V 1B: Read variable V 2A: Add 1 to variable V 2B: Add 1 to variable V 3A: Write back to variable V 3B: Write back to variable V —————————— ——————————
If instruction 1B is executed between 1A and 3A, or if instruction 1A is executed between 1B and 3B, the program will produce incorrect data. This is known as a race condition. The programmer must use a lock to provide mutual exclusion. A lock is a programming language construct that allows one thread to take control of a variable and prevent other threads from reading or writing it, until that variable is unlocked. The thread holding the lock is free to execute its critical section (the section of a program that requires exclusive access to some variable), and to unlock the data when it is finished. Therefore, to guarantee correct program execution, the above program can be rewritten to use locks:
Thread A Thread B 1A: Lock variable V 1B: Lock variable V 2A: Read variable V 2B: Read variable V 3A: Add 1 to variable V 3B: Add 1 to variable V 4A: Write back to variable V 4B: Write back to variable V 5A: Unlock variable V 5B: Unlock variable V —————————— ——————————
One thread will successfully lock variable V, while the other thread will be locked out—unable to proceed until V is unlocked again. This guarantees correct execution of the program. Locks, while necessary to ensure correct program execution, can greatly slow a program.
Locking multiple variables using non-atomic locks introduces the possibility of program deadlock. An atomic lock locks multiple variables all at once. If it cannot lock all of them, it does not lock any of them. If two threads each need to lock the same two variables using non-atomic locks, it is possible that one thread will lock one of them and the second thread will lock the second variable. In such a case, neither thread can complete, and deadlock results.
Many parallel programs require that their subtasks act in synchrony. This requires the use of a barrier. Barriers are typically implemented using a software lock. One class of algorithms, known as lock-free and wait-free algorithms, altogether avoids the use of locks and barriers. However, this approach is generally difficult to implement and requires correctly designed data structures.
Not all parallelization results in speed-up. Generally, as a task is split up into more and more threads, those threads spend an ever-increasing portion of their time communicating with each other. Eventually, the overhead from communication dominates the time spent solving the problem, and further parallelization (that is, splitting the workload over even more threads) increases rather than decreases the amount of time required to finish. This is known as parallel slowdown.
Fine-grained, coarse-grained, and embarrassing parallelism
Applications are often classified according to how often their subtasks need to synchronize or communicate with each other. An application exhibits fine-grained parallelism if its subtasks must communicate many times per second; it exhibits coarse-grained parallelism if they do not communicate many times per second, and it is embarrassingly parallel if they rarely or never have to communicate. Embarrassingly parallel applications are considered the easiest to parallelize.
Consistency models
Main article: Consistency model
Parallel programming languages and parallel computers must have a consistency model (also known as a memory model). The consistency model defines rules for how operations on computer memory occur and how results are produced.
One of the first consistency models was Leslie Lamport’s sequential consistency model. Sequential consistency is the property of a parallel program that its parallel execution produces the same results as a sequential program. Specifically, a program is sequentially consistent if “… the results of any execution is the same as if the operations of all the processors were executed in some sequential order, and the operations of each individual processor appear in this sequence in the order specified by its program”.[16]
Software transactional memory is a common type of consistency model. Software transactional memory borrows from database theory the concept of atomic transactions and applies them to memory accesses.
Mathematically, these models can be represented in several ways. Petri nets, which were introduced in Carl Adam Petri’s 1962 doctoral thesis, were an early attempt to codify the rules of consistency models. Dataflow theory later built upon these, and Dataflow architectures were created to physically implement the ideas of dataflow theory. Beginning in the late 1970s, process calculi such as Calculus of Communicating Systems and Communicating Sequential Processes were developed to permit algebraic reasoning about systems composed of interacting components. More recent additions to the process calculus family, such as the π-calculus, have added the capability for reasoning about dynamic topologies. Logics such as Lamport’s TLA+, and mathematical models such as traces and Actor event diagrams, have also been developed to describe the behavior of concurrent systems.
Flynn’s taxonomy
Michael J. Flynn created one of the earliest classification systems for parallel (and sequential) computers and programs, now known as Flynn’s taxonomy. Flynn classified programs and computers by whether they were operating using a single set or multiple sets of instructions, and whether or not those instructions were using a single set or multiple sets of data.
Flynn’s taxonomy <table class=”wikitable” style=”float: right; margin: 0 0 1em 1em; text-align: bordercolor=”#000000” border=”1” center;”>
</table>
The single-instruction-single-data (SISD) classification is equivalent to an entirely sequential program. The single-instruction-multiple-data (SIMD) classification is analogous to doing the same operation repeatedly over a large data set. This is commonly done in signal processing applications. Multiple-instruction-single-data (MISD) is a rarely used classification. While computer architectures to deal with this were devised (such as systolic arrays), few applications that fit this class materialized. Multiple-instruction-multiple-data (MIMD) programs are by far the most common type of parallel programs.
Visually, these four architectures are shown below where each “PU” is a central processing unit:
<table class=”wikitable”bordercolor=”#000000” border=”1”>
 </a>
</a>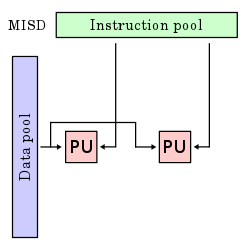 </a>
</a>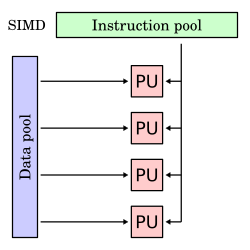 </a>
</a>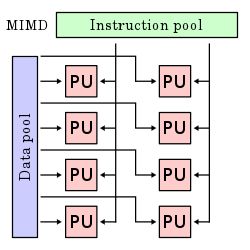 </a>
</a></table>
According to David A. Patterson and John L. Hennessy, “Some machines are hybrids of these categories, of course, but this classic model has survived because it is simple, easy to understand, and gives a good first approximation. It is also—perhaps because of its understandability—the most widely used scheme.”[17]
Types of parallelism
Bit-level parallelism
Main article: Bit-level parallelism
From the advent of very-large-scale integration (VLSI) computer-chip fabrication technology in the 1970s until about 1986, speed-up in computer architecture was driven by doubling computer word size—the amount of information the processor can manipulate per cycle.[18] Increasing the word size reduces the number of instructions the processor must execute to perform an operation on variables whose sizes are greater than the length of the word. For example, where an 8-bit processor must add two 16-bit integers, the processor must first add the 8 lower-order bits from each integer using the standard addition instruction, then add the 8 higher-order bits using an add-with-carry instruction and the carry bit from the lower order addition; thus, an 8-bit processor requires two instructions to complete a single operation, where a 16-bit processor would be able to complete the operation with a single instruction.
Historically, 4-bit microprocessors were replaced with 8-bit, then 16-bit, then 32-bit microprocessors. This trend generally came to an end with the introduction of 32-bit processors, which has been a standard in general-purpose computing for two decades. Not until recently (c. 2003–2004), with the advent of x86-64 architectures, have 64-bit processors become commonplace.
Instruction-level parallelism
Main article: Instruction level parallelism

A canonical five-stage pipeline in a RISC machine (IF = Instruction Fetch, ID = Instruction Decode, EX = Execute, MEM = Memory access, WB = Register write back)
A computer program, is in essence, a stream of instructions executed by a processor. These instructions can be re-ordered and combined into groups which are then executed in parallel without changing the result of the program. This is known as instruction-level parallelism. Advances in instruction-level parallelism dominated computer architecture from the mid-1980s until the mid-1990s.[19]
Modern processors have multi-stage instruction pipelines. Each stage in the pipeline corresponds to a different action the processor performs on that instruction in that stage; a processor with an N-stage pipeline can have up to N different instructions at different stages of completion. The canonical example of a pipelined processor is a RISC processor, with five stages: instruction fetch, decode, execute, memory access, and write back. The Pentium 4 processor had a 35-stage pipeline.[20]

A five-stage pipelined superscalar processor, capable of issuing two instructions per cycle. It can have two instructions in each stage of the pipeline, for a total of up to 10 instructions (shown in green) being simultaneously executed.
In addition to instruction-level parallelism from pipelining, some processors can issue more than one instruction at a time. These are known as superscalar processors. Instructions can be grouped together only if there is no data dependency between them. Scoreboarding and the Tomasulo algorithm (which is similar to scoreboarding but makes use of register renaming) are two of the most common techniques for implementing out-of-order execution and instruction-level parallelism.
Task parallelism
Main article: Task parallelism
Task parallelism is the characteristic of a parallel program that “entirely different calculations can be performed on either the same or different sets of data”.[21] This contrasts with data parallelism, where the same calculation is performed on the same or different sets of data. Task parallelism does not usually scale with the size of a problem.[22]
Hardware
Memory and communication
Main memory in a parallel computer is either shared memory (shared between all processing elements in a single address space), or distributed memory (in which each processing element has its own local address space).[23] Distributed memory refers to the fact that the memory is logically distributed, but often implies that it is physically distributed as well. Distributed shared memory and memory virtualization combine the two approaches, where the processing element has its own local memory and access to the memory on non-local processors. Accesses to local memory are typically faster than accesses to non-local memory.

A logical view of a Non-Uniform Memory Access (NUMA) architecture. Processors in one directory can access that directory’s memory with less latency than they can access memory in the other directory’s memory.
Computer architectures in which each element of main memory can be accessed with equal latency and bandwidth are known as Uniform Memory Access (UMA) systems. Typically, that can be achieved only by a shared memory system, in which the memory is not physically distributed. A system that does not have this property is known as a Non-Uniform Memory Access (NUMA) architecture. Distributed memory systems have non-uniform memory access.
Computer systems make use of caches—small, fast memories located close to the processor which store temporary copies of memory values (nearby in both the physical and logical sense). Parallel computer systems have difficulties with caches that may store the same value in more than one location, with the possibility of incorrect program execution. These computers require a cache coherency system, which keeps track of cached values and strategically purges them, thus ensuring correct program execution. Bus snooping is one of the most common methods for keeping track of which values are being accessed (and thus should be purged). Designing large, high-performance cache coherence systems is a very difficult problem in computer architecture. As a result, shared-memory computer architectures do not scale as well as distributed memory systems do.[23]
Processor–processor and processor–memory communication can be implemented in hardware in several ways, including via shared (either multiported or multiplexed) memory, a crossbar switch, a shared bus or an interconnect network of a myriad of topologies including star, ring, tree, hypercube, fat hypercube (a hypercube with more than one processor at a node), or n-dimensional mesh.
Parallel computers based on interconnect networks need to have some kind of routing to enable the passing of messages between nodes that are not directly connected. The medium used for communication between the processors is likely to be hierarchical in large multiprocessor machines.
Classes of parallel computers
Parallel computers can be roughly classified according to the level at which the hardware supports parallelism. This classification is broadly analogous to the distance between basic computing nodes. These are not mutually exclusive; for example, clusters of symmetric multiprocessors are relatively common.
Multicore computing
Main article: Multi-core (computing)
A multicore processor is a processor that includes multiple execution units (“cores”) on the same chip. These processors differ from superscalar processors, which can issue multiple instructions per cycle from one instruction stream (thread); in contrast, a multicore processor can issue multiple instructions per cycle from multiple instruction streams. IBM’s Cell microprocessor, designed for use in the Sony PlayStation 3, is another prominent multicore processor.
Each core in a multicore processor can potentially be superscalar as well—that is, on every cycle, each core can issue multiple instructions from one instruction stream. Simultaneous multithreading (of which Intel’s HyperThreading is the best known) was an early form of pseudo-multicoreism. A processor capable of simultaneous multithreading has only one execution unit (“core”), but when that execution unit is idling (such as during a cache miss), it uses that execution unit to process a second thread.
Symmetric multiprocessing
Main article: Symmetric multiprocessing
A symmetric multiprocessor (SMP) is a computer system with multiple identical processors that share memory and connect via a bus.[24] Bus contention prevents bus architectures from scaling. As a result, SMPs generally do not comprise more than 32 processors.[25] “Because of the small size of the processors and the significant reduction in the requirements for bus bandwidth achieved by large caches, such symmetric multiprocessors are extremely cost-effective, provided that a sufficient amount of memory bandwidth exists.”[24]
Distributed computing
Main article: Distributed computing
A distributed computer (also known as a distributed memory multiprocessor) is a distributed memory computer system in which the processing elements are connected by a network. Distributed computers are highly scalable.
Cluster computing
Main article: Computer cluster

A cluster is a group of loosely coupled computers that work together closely, so that in some respects they can be regarded as a single computer.[26] Clusters are composed of multiple standalone machines connected by a network. While machines in a cluster do not have to be symmetric, load balancing is more difficult if they are not. The most common type of cluster is the Beowulf cluster, which is a cluster implemented on multiple identical commercial off-the-shelf computers connected with a TCP/IP Ethernet local area network.[27] Beowulf technology was originally developed by Thomas Sterling and Donald Becker. The vast majority of the TOP500 supercomputers are clusters.[28]
Massive parallel processing
Main article: Massively parallel (computing)
A massively parallel processor (MPP) is a single computer with many networked processors. MPPs have many of the same characteristics as clusters, but MPPs have specialized interconnect networks (whereas clusters use commodity hardware for networking). MPPs also tend to be larger than clusters, typically having “far more” than 100 processors.[29] In a MPP, “each CPU contains its own memory and copy of the operating system and application. Each subsystem communicates with the others via a high-speed interconnect.”[30]

A cabinet from Blue Gene/L, ranked as the fourth fastest supercomputer in the world according to the 11/2008 TOP500 rankings. Blue Gene/L is a massively parallel processor.
Blue Gene/L, the fifth fastest supercomputer in the world according to the June 2009 TOP500 ranking, is a MPP.
Grid computing
Main article: Distributed computing
Distributed computing is the most distributed form of parallel computing. It makes use of computers communicating over the Internet to work on a given problem. Because of the low bandwidth and extremely high latency available on the Internet, distributed computing typically deals only with embarrassingly parallel problems. Many distributed computing applications have been created, of which SETI@home and Folding@home are the best-known examples.[31]
Most grid computing applications use middleware, software that sits between the operating system and the application to manage network resources and standardize the software interface. The most common distributed computing middleware is the Berkeley Open Infrastructure for Network Computing (BOINC). Often, distributed computing software makes use of “spare cycles”, performing computations at times when a computer is idling.
Specialized parallel computers
Within parallel computing, there are specialized parallel devices that remain niche areas of interest. While not domain-specific, they tend to be applicable to only a few classes of parallel problems.
Reconfigurable computing with field-programmable gate arrays
Reconfigurable computing is the use of a field-programmable gate array (FPGA) as a co-processor to a general-purpose computer. An FPGA is, in essence, a computer chip that can rewire itself for a given task.
FPGAs can be programmed with hardware description languages such as VHDL or Verilog. However, programming in these languages can be tedious. Several vendors have created C to HDL languages that attempt to emulate the syntax and semantics of the C programming language, with which most programmers are familiar. The best known C to HDL languages are Mitrion-C, Impulse C, DIME-C, and Handel-C. Specific subsets of SystemC based on C++ can also be used for this purpose.
AMD’s decision to open its HyperTransport technology to third-party vendors has become the enabling technology for high-performance reconfigurable computing.[32] According to Michael R. D’Amour, Chief Operating Officer of DRC Computer Corporation, “when we first walked into AMD, they called us ‘the socket stealers.’ Now they call us their partners.”[32]
General-purpose computing on graphics processing units (GPGPU)
Main article: GPGPU

Nvidia’s Tesla GPGPU card
General-purpose computing on graphics processing units (GPGPU) is a fairly recent trend in computer engineering research. GPUs are co-processors that have been heavily optimized for computer graphics processing.[33] Computer graphics processing is a field dominated by data parallel operations—particularly linear algebra matrix operations.
In the early days, GPGPU programs used the normal graphics APIs for executing programs. However, several new programming languages and platforms have been built to do general purpose computation on GPUs with both Nvidia and AMD releasing programming environments with CUDA and Stream SDK respectively. Other GPU programming languages include BrookGPU, PeakStream, and RapidMind. Nvidia has also released specific products for computation in their Tesla series. The technology consortium Khronos Group has released the OpenCL specification, which is a framework for writing programs that execute across platforms consisting of CPUs and GPUs. AMD, Apple, Intel, Nvidia and others are supporting OpenCL.
Application-specific integrated circuits
Main article: Application-specific integrated circuit
Several application-specific integrated circuit (ASIC) approaches have been devised for dealing with parallel applications.[34][35][36]
Because an ASIC is (by definition) specific to a given application, it can be fully optimized for that application. As a result, for a given application, an ASIC tends to outperform a general-purpose computer. However, ASICs are created by X-ray lithography. This process requires a mask, which can be extremely expensive. A single mask can cost over a million US dollars.[37] (The smaller the transistors required for the chip, the more expensive the mask will be.) Meanwhile, performance increases in general-purpose computing over time (as described by Moore’s Law) tend to wipe out these gains in only one or two chip generations.[32] High initial cost, and the tendency to be overtaken by Moore’s-law-driven general-purpose computing, has rendered ASICs unfeasible for most parallel computing applications. However, some have been built. One example is the peta-flop RIKEN MDGRAPE-3 machine which uses custom ASICs for molecular dynamics simulation.
Vector processors
Main article: Vector processor

The Cray-1 is the most famous vector processor.
A vector processor is a CPU or computer system that can execute the same instruction on large sets of data. “Vector processors have high-level operations that work on linear arrays of numbers or vectors. An example vector operation is A = B × C, where A, B, and C are each 64-element vectors of 64-bit floating-point numbers.”[38] They are closely related to Flynn’s SIMD classification.[38]
Cray computers became famous for their vector-processing computers in the 1970s and 1980s. However, vector processors—both as CPUs and as full computer systems—have generally disappeared. Modern processor instruction sets do include some vector processing instructions, such as with AltiVec and Streaming SIMD Extensions (SSE).
Software
Parallel programming languages
Main article: List of concurrent and parallel programming languages
Concurrent programming languages, libraries, APIs, and parallel programming models (such as Algorithmic Skeletons) have been created for programming parallel computers. These can generally be divided into classes based on the assumptions they make about the underlying memory architecture—shared memory, distributed memory, or shared distributed memory. Shared memory programming languages communicate by manipulating shared memory variables. Distributed memory uses message passing. POSIX Threads and OpenMP are two of most widely used shared memory APIs, whereas Message Passing Interface (MPI) is the most widely used message-passing system API.[39] One concept used in programming parallel programs is the future concept, where one part of a program promises to deliver a required datum to another part of a program at some future time.
CAPS entreprise and Pathscale are also coordinating their effort to make HMPP (Hybrid Multicore Parallel Programming) directives an Open Standard called OpenHMPP. The OpenHMPP directive-based programming model offers a syntax to efficiently offload computations on hardware accelerators and to optimize data movement to/from the hardware memory. OpenHMPP directives describe remote procedure call (RPC) on an accelerator device (e.g. GPU) or more generally a set of cores. The directives annotate C or Fortran codes to describe two sets of functionalities: the offloading of procedures (denoted codelets) onto a remote device and the optimization of data transfers between the CPU main memory and the accelerator memory.
One of the hottest older languages that is recently being extended from embedded mobile and telephony to more general concurrent challenges and projects is Erlang (programming language). See the wiki article for numerous references on these applications.
Automatic parallelization
Main article: Automatic parallelization
Automatic parallelization of a sequential program by a compiler is the holy grail of parallel computing. Despite decades of work by compiler researchers, automatic parallelization has had only limited success.[40]
Mainstream parallel programming languages remain either explicitly parallel or (at best) partially implicit, in which a programmer gives the compiler directives for parallelization. A few fully implicit parallel programming languages exist—SISAL, Parallel Haskell, System C (for FPGAs), Mitrion-C, VHDL, and Verilog.
Application checkpointing
Main article: Application checkpointing
As a computer system grows in complexity, the mean time between failures usually decreases. Application checkpointing is a technique whereby the computer system takes a “snapshot” of the application — a record of all current resource allocations and variable states, akin to a core dump; this information can be used to restore the program if the computer should fail. Application checkpointing means that the program has to restart from only its last checkpoint rather than the beginning. While checkpointing provides benefits in a variety of situations, it is especially useful in highly parallel systems with a large number of processors used in high performance computing.[41]
Algorithmic methods
As parallel computers become larger and faster, it becomes feasible to solve problems that previously took too long to run. Parallel computing is used in a wide range of fields, from bioinformatics (protein folding and sequence analysis) to economics (mathematical finance). Common types of problems found in parallel computing applications are:[42]
- Dense linear algebra
- Sparse linear algebra
- Spectral methods (such as Cooley–Tukey fast Fourier transform)
- n-body problems (such as Barnes–Hut simulation)
- Structured grid problems (such as Lattice Boltzmann methods)
- Unstructured grid problems (such as found in finite element analysis)
- Monte Carlo simulation
- Combinational logic (such as brute-force cryptographic techniques)
- Graph traversal (such as sorting algorithms)
- Dynamic programming
- Branch and bound methods
- Graphical models (such as detecting hidden Markov models and constructing Bayesian networks)
- Finite-state machine simulation
Fault-tolerance
Further information: Fault-tolerant computer system
Parallel computing can also be applied to the design of fault-tolerant computer systems, particularly via lockstep systems performing the same operation in parallel. This provides redundancy in case one component should fail, and also allows automatic error detection and error correction if the results differ.
History
Main article: History of computing

ILLIAC IV, “perhaps the most infamous of Supercomputers”[43]
The origins of true (MIMD) parallelism go back to Federico Luigi, Conte Menabrea and his “Sketch of the Analytic Engine Invented by Charles Babbage”.[44][45] IBM introduced the 704 in 1954, through a project in which Gene Amdahl was one of the principal architects. It became the first commercially available computer to use fully automatic floating point arithmetic commands.[46]
In April 1958, S. Gill (Ferranti) discussed parallel programming and the need for branching and waiting.[47] Also in 1958, IBM researchers John Cocke and Daniel Slotnick discussed the use of parallelism in numerical calculations for the first time.[48] Burroughs Corporation introduced the D825 in 1962, a four-processor computer that accessed up to 16 memory modules through a crossbar switch.[49] In 1967, Amdahl and Slotnick published a debate about the feasibility of parallel processing at American Federation of Information Processing Societies Conference.[48] It was during this debate that Amdahl’s Law was coined to define the limit of speed-up due to parallelism.
In 1969, US company Honeywell introduced its first Multics system, a symmetric multiprocessor system capable of running up to eight processors in parallel.[48] C.mmp, a 1970s multi-processor project at Carnegie Mellon University, was “among the first multiprocessors with more than a few processors”.[45] “The first bus-connected multi-processor with snooping caches was the Synapse N+1 in 1984.”[45]
SIMD parallel computers can be traced back to the 1970s. The motivation behind early SIMD computers was to amortize the gate delay of the processor’s control unit over multiple instructions.[50] In 1964, Slotnick had proposed building a massively parallel computer for the Lawrence Livermore National Laboratory.[48] His design was funded by the US Air Force, which was the earliest SIMD parallel-computing effort, ILLIAC IV.[48] The key to its design was a fairly high parallelism, with up to 256 processors, which allowed the machine to work on large datasets in what would later be known as vector processing. However, ILLIAC IV was called “the most infamous of Supercomputers”, because the project was only one fourth completed, but took 11 years and cost almost four times the original estimate.[43] When it was finally ready to run its first real application in 1976, it was outperformed by existing commercial supercomputers such as the Cray-1.
See also
- List of important publications in concurrent, parallel, and distributed computing
- List of distributed computing conferences
- Concurrency (computer science)
- Synchronous programming
- Content Addressable Parallel Processor
- Transputer
References
- Gottlieb, Allan; Almasi, George S. (1989). Highly parallel computing. Redwood City, Calif.: Benjamin/Cummings. ISBN 0-8053-0177-1. Cite uses deprecated parameters (help)
- S.V. Adve et al. (November 2008). “Parallel Computing Research at Illinois: The UPCRC Agenda” (PDF). Parallel@Illinois, University of Illinois at Urbana-Champaign. “The main techniques for these performance benefits – increased clock frequency and smarter but increasingly complex architectures – are now hitting the so-called power wall. The computer industry has accepted that future performance increases must largely come from increasing the number of processors (or cores) on a die, rather than making a single core go faster.”
- Asanovic et al. Old [conventional wisdom]: Power is free, but transistors are expensive. New [conventional wisdom] is [that] power is expensive, but transistors are “free”.
- View-Power_4-0 Asanovic, Krste et al. (December 18, 2006). “The Landscape of Parallel Computing Research: A View from Berkeley” (PDF). University of California, Berkeley. Technical Report No. UCB/EECS-2006-183. “Old [conventional wisdom]: Increasing clock frequency is the primary method of improving processor performance. New [conventional wisdom]: Increasing parallelism is the primary method of improving processor performance … Even representatives from Intel, a company generally associated with the ‘higher clock-speed is better’ position, warned that traditional approaches to maximizing performance through maximizing clock speed have been pushed to their limit.”
- Hennessy, John L.; Patterson, David A., Larus, James R. (1999). Computer organization and design : the hardware/software interface (2. ed., 3rd print. ed.). San Francisco: Kaufmann. ISBN 1-55860-428-6. Cite uses deprecated parameters (help)
- Barney, Blaise. “Introduction to Parallel Computing”. Lawrence Livermore National Laboratory. Retrieved 2007-11-09.
- Hennessy, John L.; Patterson, David A. (2002). Computer architecture / a quantitative approach. (3rd ed.). San Francisco, Calif.: International Thomson. p. 43. ISBN 1-55860-724-2. Cite uses deprecated parameters (help)
- Rabaey, Jan M. (1996). Digital integrated circuits : a design perspective. Upper Saddle River, N.J.: Prentice-Hall. p. 235. ISBN 0-13-178609-1.
- Flynn, Laurie J. (8 May 2004). “Intel Halts Development Of 2 New Microprocessors”. New York Times. Retrieved 5 June 2012.
- Moore1965paper_10-0 Moore, Gordon E. (1965). “Cramming more components onto integrated circuits” (PDF). Electronics Magazine. p. 4. Retrieved 2006-11-11.
- Amdahl, Gene M. (1967). “Validity of the single processor approach to achieving large scale computing capabilities”. Proceeding AFIPS ‘67 (Spring) Proceedings of the April 18–20, 1967, spring joint computer conference: 483–485. doi:10.1145/1465482.1465560.
- Brooks, Frederick P. (1996). The mythical man month essays on software engineering (Anniversary ed., repr. with corr., 5. [Dr.] ed.). Reading, Mass. [u.a.]: Addison-Wesley. ISBN 0-201-83595-9.
- Gustafson, John L. (May 1988). “Reevaluating Amdahl’s law”. Communications of the ACM 31 (5): 532–533. doi:10.1145/42411.42415.
- Bernstein, A. J. (1 October 1966). “Analysis of Programs for Parallel Processing”. IEEE Transactions on Electronic Computers. EC-15 (5): 757–763. doi:10.1109/PGEC.1966.264565.
- Roosta, Seyed H. (2000). Parallel processing and parallel algorithms : theory and computation. New York, NY [u.a.]: Springer. p. 114. ISBN 0-387-98716-9.
- Lamport, Leslie (1 September 1979). “How to Make a Multiprocessor Computer That Correctly Executes Multiprocess Programs”. IEEE Transactions on Computers C–28 (9): 690–691. doi:10.1109/TC.1979.1675439.
- Patterson and Hennessy, p. 748.
- Singh, David Culler ; J.P. (1997). Parallel computer architecture ([Nachdr.] ed.). San Francisco: Morgan Kaufmann Publ. p. 15. ISBN 1-55860-343-3.
- Culler et al. p. 15.
- Patt, Yale (April 2004). “The Microprocessor Ten Years From Now: What Are The Challenges, How Do We Meet Them? (wmv). Distinguished Lecturer talk at Carnegie Mellon University. Retrieved on November 7, 2007.
- Culler124_21-0 Culler et al. p. 124.
- Culler125_22-0 Culler et al. p. 125.
- Patterson and Hennessy, p. 713.
- Hennessy and Patterson, p. 549.
- Patterson and Hennessy, p. 714.
- What is clustering?](http://www.webopedia.com/TERM/c/clustering.html) Webopedia computer dictionary. Retrieved on November 7, 2007.
- Beowulf definition. PC Magazine. Retrieved on November 7, 2007.
- Architecture share for 06/2007. TOP500 Supercomputing Sites. Clusters make up 74.60% of the machines on the list. Retrieved on November 7, 2007.
- Hennessy and Patterson, p. 537.
- MPP Definition. PC Magazine. Retrieved on November 7, 2007.
- Kirkpatrick, Scott (2003). “COMPUTER SCIENCE: Rough Times Ahead”. Science 299 (5607): 668–669. doi:10.1126/science.1081623. PMID 12560537.
- D’Amour, Michael R., Chief Operating Officer, DRC Computer Corporation. “Standard Reconfigurable Computing”. Invited speaker at the University of Delaware, February 28, 2007.
- Boggan, Sha’Kia and Daniel M. Pressel (August 2007). GPUs: An Emerging Platform for General-Purpose Computation (PDF). ARL-SR-154, U.S. Army Research Lab. Retrieved on November 7, 2007.
- Maslennikov, Oleg (2002). “Systematic Generation of Executing Programs for Processor Elements in Parallel ASIC or FPGA-Based Systems and Their Transformation into VHDL-Descriptions of Processor Element Control Units”. Lecture Notes in Computer Science, 2328/2002: p. 272.
- Shimokawa, Y.; Y. Fuwa and N. Aramaki (18-21
Nov 1991). “A parallel ASIC VLSI neurocomputer for a large number
of neurons and billion connections per second
speed”.
International Joint Conference on Neural Networks 3:
2162–2167.
doi:10.1109/IJCNN.1991.170708.
ISBN 0-7803-0227-3.
Cite uses deprecated parameters
(help);
Check date values in:
|date=(help) - Acken, Kevin P.; Irwin, Mary Jane; Owens, Robert M. (1 January 1998). The Journal of VLSI Signal Processing 19 (2): 97–113. doi:10.1023/A:1008005616596. Cite uses deprecated parameters (help)
- Kahng, Andrew B. (June 21, 2004) “Scoping the Problem of DFM in the Semiconductor Industry.” University of California, San Diego. “Future design for manufacturing (DFM) technology must reduce design [non-recoverable expenditure] cost and directly address manufacturing [non-recoverable expenditures] – the cost of a mask set and probe card – which is well over $1 million at the 90 nm technology node and creates a significant damper on semiconductor-based innovation.”
- Patterson and Hennessy, p. 751.
- The Sidney Fernbach Award given to MPI inventor Bill Gropp refers to MPI as “the dominant HPC communications interface”
- Shen, John Paul; Mikko H. Lipasti (2004). Modern processor design : fundamentals of superscalar processors (1st ed.). Dubuque, Iowa: McGraw-Hill. p. 561. ISBN 0-07-057064-7. “However, the holy grail of such research – automated parallelization of serial programs – has yet to materialize. While automated parallelization of certain classes of algorithms has been demonstrated, such success has largely been limited to scientific and numeric applications with predictable flow control (e.g., nested loop structures with statically determined iteration counts) and statically analyzable memory access patterns. (e.g., walks over large multidimensional arrays of float-point data).” Cite uses deprecated parameters (help)
- Encyclopedia of Parallel Computing, Volume 4 by David Padua 2011 ISBN 0387097651 page 265
- Asanovic, Krste, et al. (December 18, 2006). The Landscape of Parallel Computing Research: A View from Berkeley (PDF). University of California, Berkeley. Technical Report No. UCB/EECS-2006-183. See table on pages 17–19.
- Patterson and Hennessy, pp. 749–50: “Although successful in pushing several technologies useful in later projects, the ILLIAC IV failed as a computer. Costs escalated from the $8 million estimated in 1966 to $31 million by 1972, despite the construction of only a quarter of the planned machine … It was perhaps the most infamous of supercomputers. The project started in 1965 and ran its first real application in 1976.”
- Menabrea, L. F. (1842). Sketch of the Analytic Engine Invented by Charles Babbage. Bibliothèque Universelle de Genève. Retrieved on November 7, 2007.
- Patterson and Hennessy, p. 753.
- da Cruz, Frank (2003). “Columbia University Computing History: The IBM 704”. Columbia University. Retrieved 2008-01-08.
- Parallel Programming, S. Gill, The Computer Journal Vol. 1 #1, pp2-10, British Computer Society, April 1958.
- Wilson, Gregory V (1994). “The History of the Development of Parallel Computing”. Virginia Tech/Norfolk State University, Interactive Learning with a Digital Library in Computer Science. Retrieved 2008-01-08.
- Anthes, Gry (November 19, 2001). “The Power of Parallelism”. Computerworld. Retrieved 2008-01-08.
- Patterson and Hennessy, p. 749.
Further reading
- Rodriguez, C.; Villagra, M.; Baran, B. (29 August 2008).
“Asynchronous team algorithms for Boolean
Satisfiability”.
*Bio-Inspired Models of Network, Information and Computing Systems,
- Bionetics 2007. 2nd*: 66–69. doi:10.1109/BIMNICS.2007.4610083.
External links
Listen to this article (info/dl)
Sorry, your browser either has JavaScript disabled or does not have any
supported player.
You can download the
clip
or download a
player
to play the clip in your browser.
![]()
This audio file was created from a revision of the “Parallel computing” article dated 2013-08-21, and does not reflect subsequent edits to the article. (Audio help)
![]()
![]() Wikibooks has a book on the topic of: Distributed Systems
——————————————————————————————————————————— ————————————————————————————————————————————————
Wikibooks has a book on the topic of: Distributed Systems
——————————————————————————————————————————— ————————————————————————————————————————————————
- Go Parallel: Translating Multicore Power into Application Performance
- Parallel computing on the Open Directory Project
- Lawrence Livermore National Laboratory: Introduction to Parallel Computing
- Comparing programmability of Open MP and pthreads
- What makes parallel programming hard?
- Designing and Building Parallel Programs, by Ian Foster
- Internet Parallel Computing Archive
- Parallel processing topic area at IEEE Distributed Computing Online
- Parallel Computing Works Free On-line Book
- Frontiers of Supercomputing Free On-line Book Covering topics like algorithms and industrial applications
- Universal Parallel Computing Research Center
- Course in Parallel Programming at Columbia University (in collaboration with IBM T.J Watson X10 project)
- Parallel and distributed Grobner bases computation in JAS
- Course in Parallel Computing at University of Wisconsin-Madison
- v
- t
- e
Parallel computing
General
Levels
Theory
Elements
Coordination
- Multiprocessing
- Memory coherency
- Cache coherency
- Cache invalidation
- Barrier
- Synchronization
- Application checkpointing
- Ateji PX
- POSIX Threads
- OpenMP
- OpenHMPP
- OpenACC
- PVM
- MPI
- UPC
- TBB
- Boost.Thread
- Global Arrays
- Charm++
- Cilk/Cilk Plus
- Coarray Fortran
- OpenCL
- CUDA
- Dryad
- C++ AMP
- PLINQ
- TPL
Problems
- Embarrassingly parallel
- Software lockout
- Scalability
- Race condition
- Deadlock
- Livelock
- Starvation
- Deterministic algorithm
 Category:
parallel
computing
Category:
parallel
computing Media related to parallel
computing
at Wikimedia Commons
Media related to parallel
computing
at Wikimedia Commons
References
[1] Parallel computing, From Wikipedia, the free encyclopedia, 2014.