Article Source
[1] Healthcare Does Hadoop, Hortonworks Blog.
Healthcare Does Hadoop
Use Apache Hadoop to Save Lives While Delivering More Efficient Care
Difficult challenges and choices face today’s healthcare industry. Hospital administrators, technology and pharmaceutical providers, researchers, and clinicians have to make important decisions—often without sufficient accurate, transparent data.
At the same time, consumers are experiencing increased costs without a corresponding increase in health security or in the reliability of clinical outcomes.
At Hortonworks, we see our healthcare customers ingest and analyze data from many sources. The following reference architecture is an amalgam of Hadoop data patterns that we’ve seen with our customers’ use of Hortonworks Data Platform (HDP). Components shaded green are part of HDP.
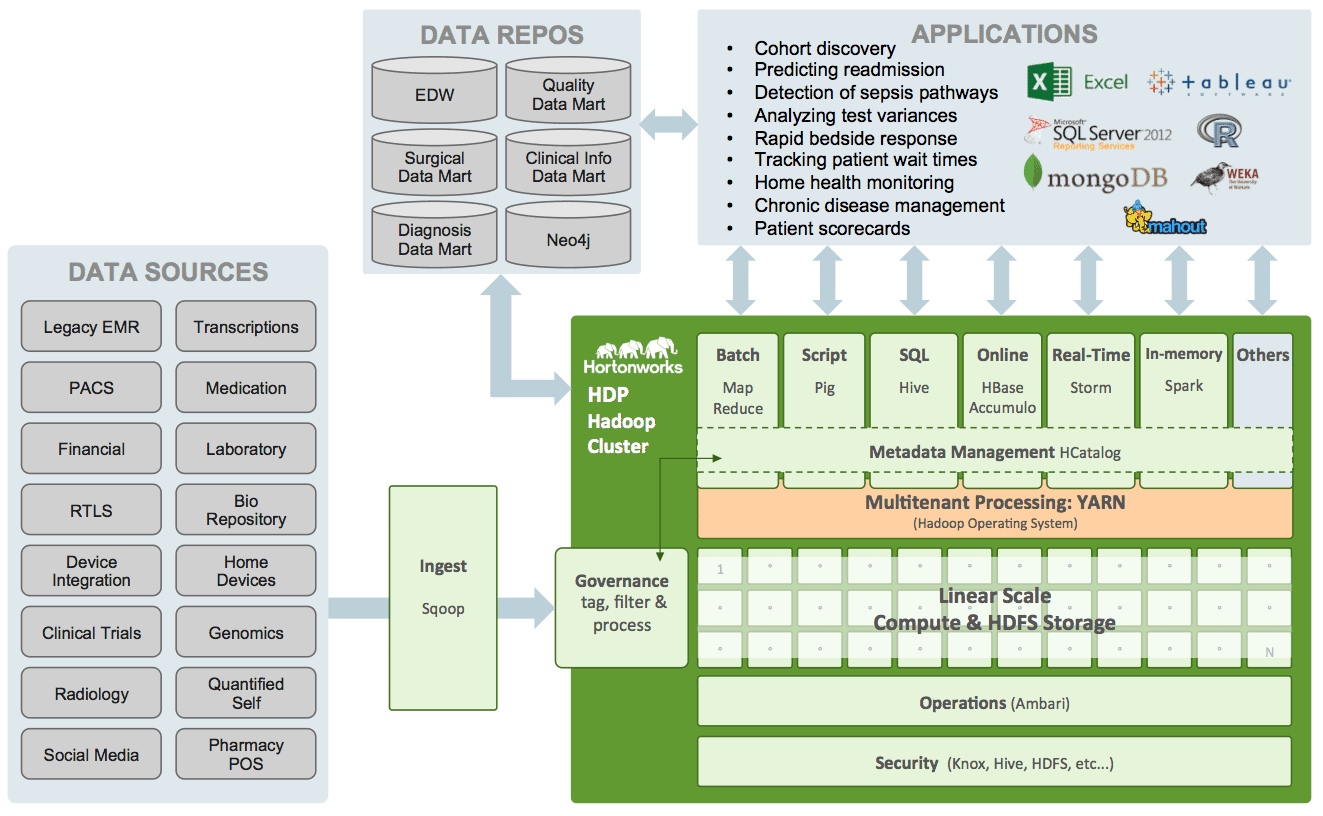
Here are some ways that Hadoop makes data less expensive and more available, so that patients have more choices, doctors have more insight, and pharma and device manufacturers can deliver more effective, reliable products:
Access Genomic Data for Medical Trials
If we read that a given drug is “40% effective in treating cancer,” another interpretation could be that the drug is 100% effective for patients with a certain genetic profile.
Matching a particular drug to a specific genomic profile is a big data problem. Each individual’s genome is about 1.5 gigabytes of data. Massive data storage and processing power is required to analyze data on a drug’s interactions with different genetic combinations. For example, just focusing on 20 genes is a 20,000-choose-20 calculation, with 4.3 x 10\^67 possible combinations.
Researchers are turning to Apache Hadoop as a cost-effective, reliable platform for storing genomic data and combining that with other data sets (e.g. demographics, trial outcomes) to find out which drugs and treatments work best for groups of patients across the genetic spectrum.
Monitor Patient Vitals in Real-Time
In a typical hospital setting, nurses do rounds and manually monitor patient vital signs. They may visit each bed every few hours to measure and record vital signs but the patient’s condition may decline between the time of scheduled visits. This means that caregivers often respond to problems reactively, in situations where arriving earlier may have made a huge difference in the patient’s wellbeing.
New wireless sensors can capture and transmit patient vitals at much higher frequencies, and these measurements can stream into a Hadoop cluster. Caregivers can use these signals for real-time alerts to respond more promptly to unexpected changes. Over time, this data can go into algorithms that proactively predict the likelihood of an emergency even before that could be detected with a bedside visit.
Reduce Cardiac Re-Admittance Rates
Patients with heart disease can be closely monitored while they are in a hospital, but when those patients go home, they may skip their medications or ignore dietary and self-care instructions given by their doctor when they left the hospital.
Congestive heart failure causes fluid retention, which leads to weight gain. In one innovative program at UC Irvine Health, patients can return home with a wireless scale and weigh themselves at regular intervals. Algorithms running in Hadoop determine unsafe weight gain thresholds and notify a physician to see the patient proactively, before an emergency re-admittance.
Machine Learning to Screen for Autism with In-Home Testing
Autism spectrum disorders affect 1 in 100 children at an annual cost estimated at more than $100 billion. The condition can be detected through behavior at eighteen months, but more than 1 in 4 cases are still undiagnosed at 8 years of age. A small number of clinical testing facilities are oversubscribed, with long wait lists. The most common diagnostic test typically takes 2.5 hours to administer and score.
Dr. Dennis Wall is Director of the Computational Biology Initiative at the Harvard Medical School. In this presentation, he describes a process his team developed for low-cost, mobile screening for autism. It takes less than five minutes and relies on the ability to store large volumes of semi-structured data from brief in-home tests administered and submitted by parents. Wall’s lab also used Facebook to capture user-reported information on autism.
Artificial intelligence running on those huge data sets maximize efficiency of diagnosis without loss of accuracy. This approach, in combination with data storage on a Hadoop cluster, can be used for other innovative machine learning diagnostic processes.
Store Medical Research Data Forever
Medical and scientific researchers at universities live by the “publish or perish” code. Data supporting a given paper used to be appended in an Excel spreadsheet, but many of today’s data sets are just too large. Nevertheless, supporting data sets must be perpetually available is association with its paper. If the data disappears, the paper becomes unsubstantiated.
Universities can use a cluster running Hortonworks Data Platform as a cost-effective, perpetual storage platform for its scientists’ data. Easy and open querying capabilities allow scientific colleagues to validate and reuse the data.
Recruit Research Cohorts for Pharmaceutical Trials
Poor patient recruitment is a major cause of failure in clinical trials. Recruitment can take up to 30% of the clinical timeline. Even after a cohort is screened and selected, it is difficult to predict which patients will remain throughout the duration of a multi-year study. Today, the nexus for recruitment has moved from relatively few academic centers to thousands of private practive doctors, which increases the cost of incentives to participants.
Apache Hadoop can reduce the cost and complexity of finding patients for a study. Participants can be identified across more types of data (such as social media). Researchers can maintain a data lake of diverse patients and then search for patients for a variety of trials. Machine learning algorithms can identify patients that are most likely to enroll in a study and also most likely to continue through to its conclusion.
Track Equipment and Medicines with RFID Data
Hospitals have begun to use radio-frequency identification (RFID) to track equipment and medicines that move throughout their facilities. RFID scans of an item or device can capture their contents, location, manufacture date, order numbers, and shipping data.
In the short run, this data can help utilize medicines before their dates of expiration or quickly locate an important piece of equipment. Over time, historical data on how medicines and equipment are used provides valuable information for planning purchases and improving operations.
Improve Prescription Adherence
The Centers for Disease Control and Prevention (CDC) found in 2010 that 48% of Americans take at least one prescription drug. Many people do not take the drugs as prescribed and a separate study by the New England Health Care Institute found that this prescription non-adherence costs the health care system $290 billion annually.
Innovative healthcare providers are testing and measuring various communication programs to improve adherence. A successful outcome is a renewal of a prescription in the expected time frame. Hadoop can store renewal information and tie it to social media content and online reminders. Natural language recognition can analyze doctors’ hand-written notes. And geolocation data can help direct patients to the nearest pharmacy for a refill.