Article Source
- Title: Stinger Intiative - Making Apache Hive 100 Times Faster
- Authors: Alan Gates

The Stinger Initiative: Making Apache Hive 100 Times Faster
UPDATE: Since this article was posted, the Stinger initiative has continued to drive to the goal of 100x Faster Hive. You can read the latest information at http://hortonworks.com/labs/stinger
Introduced by Facebook in 2007, Apache Hive and its HiveQL interface has become the de facto SQL interface for Hadoop. Today, companies of all types and sizes use Hive to access Hadoop data in a familiar way and to extend value to their organization or customers either directly or though a broad ecosystem of existing BI tools that rely on this key proven interface. The who’s who of business analytics have already adopted Hive.
Apache Hive was originally built for large-scale operational batch processing and it is very effective with reporting, data mining and data preparation use cases. These usage patterns remain very important but with widespread adoption of Hadoop, the enterprise requirement for Hadoop to become more real time or interactive has increased in importance as well. At Hortonworks, we believe in the power of the open source community to innovate faster than any proprietary offering and the Stinger initiative is proof of this once again as we collaborate with others to improve Hive performance.
So, What is Stinger?
Enabling Hive to answer human-time use cases (i.e. queries in the 5-30 second range) such as big data exploration, visualization, and parameterized reports without needing to resort to yet another tool to install, maintain and learn can deliver a lot of value to the large community of users with existing Hive skills and investments.
To this end, we have launched the Stinger Initiative, with input and participation from the broader community, to enhance Hive with more SQL and better performance for these human-time use cases. All the while, HiveQL remains the same before and after these advancements so it just gets better. And in keeping with the ecosystem of existing tools, it is complementary to best-of-breed data warehouses and analytic platforms.
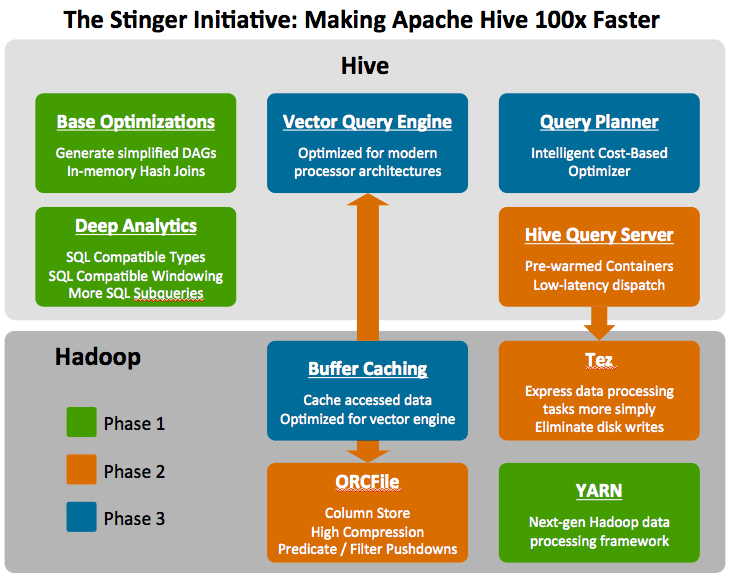
- First, we are making Hive a more suitable tool for the decision support queries people want to perform on Hadoop. This includes adding analytics features like the OVER clause, support for subqueries in WHERE, and aligning Hive’s type system more with the standard SQL model.
- Second, we are optimizing Hive’s query execution plans and based on our initial changes, we have already seen query time drop by 90% on some of our test queries. We are also looking at additional changes inside Hive’s execution engine that we believe will significantly increase the number of records per second that a Hive task can process.
- Third, we have introduced a new columnar file format (i.e. ORCFile) within the Hive community to provide a more modern, efficient, and high performing way to store Hive data.
- And lastly, we’ve introduced a new runtime framework, called Tez, which aims to eliminate Hive’s latency and throughput constraints that result from its reliance on MapReduce. Tez optimizes Hive job execution by eliminating unnecessary tasks, synchronization barriers, and reads from and write to HDFS. This optimizes the execution chain within Hadoop and drastically speeds Hive’s workload processing.
All of these modifications to Hive are underway in the open and an initial preview will be available in advance of Hadoop Summit Amsterdam in March.
Embrace the community, Embrace Hive…
A diverse group of individuals within the Hive community are collaborating on these efforts. As part f the community, a wide group of people contributed to this effort, including resources from SAP, Microsoft, Facebook and Hortonworks.
Harish Butani from SAP has led an effort to add analytics and windowing functions to Hive. This will add the OVER clause for use with existing aggregate functions as well as adding analytics functions like RANK and NTILE and windowing functions like LEAD and LAG; you can see this work at HIVE-896. Namit Jain from Facebook has been spending a lot of time lately optimizing Hive’s query execution planning so that it performs joins and other operations more efficiently and with less need for hints from the user. Hortonworks engineers have been collaborating on these and other community efforts to improve Hive.
Owen O’Malley, a Hortonworks co-founder and early Hadoop developer, has been working with Facebook on the new ORCFile in order to greatly improve performance when Hive is reading, writing, and processing data; you can see this work at HIVE-3874. We are also working on farther reaching changes and optimizations such as reworking Hive’s operators to process records in blocks of a thousand or more and thus be much more efficient than it is today.
We believe the performance changes we are making today, along with the work being done in Tez will transform Hive into a single tool that Hadoop users can use to do report generation, ad hoc queries, and large batch jobs spanning 10s or 100s of terabytes.
Why reinvent the wheel?