Article Source
- Title: Benchmarking Apache Hive 13 for Enterprise Hadoop, June 2nd, 2014.
- Authors: Carter Shanklin
Benchmarking Apache Hive 13 for Enterprise Hadoop
Stinger Initiative delivers batch and interactive SQL query workloads in single engine
Introduced in 2008, Apache Hive has been the de-facto SQL solution in Hadoop. By 2012, SQL had become a key battleground for Hadoop and many vendors started to publish benchmarks showing massive performance advantages their solutions had over Hive. Each of these vendors predicted that Hive would eventually be supplanted by the proprietary solution they were pushing.
The concerns about Hive’s performance were real. Hadoop in 2012 was a purely batch platform and no work had ever been done within Hive to address low-latency or interactive workloads. The big question remained: was it possible to make Hive fast natively in Hadoop, or did people really need to abandon Hadoop and bolt on a foreign SQL engine strictly to satisfy the one use case of interactive query?
For Hortonworks the choice was obvious. The core of Hortonworks’ philosophy is 100% community led open source and solutions 100% in Hadoop, bolting a solution on the side for one use case creates major operational headaches and would have been a major disservice to our customers. At the same time, Hadoop needed to move beyond purely batch and into interactive and real-time use cases. The introduction of YARN in Hadoop 2 meant interactive query could be developed natively in Hadoop rather than as a bolt-on.
The Apache Community at Its Best
The Stinger Initiative spanned 13 months and comprised a joint engineering effort across 44 companies and 145 developers who delivered more than 390,000 lines of code to Apache Hive alone. This broad community effort is incredibly impressive and more than any single company could create on their own. But, what’s more impressive are the results, which we are now ready to share.
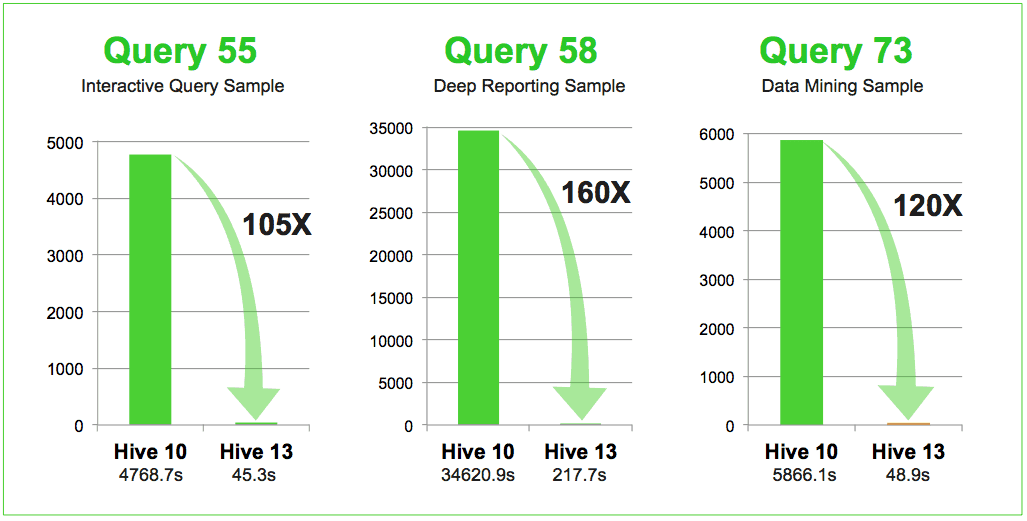
All tests run at 30TB scale factor, Hive 10 RCFile and Hive 13 ORCFile
Benchmark Results
The goal of any benchmark is to ensure it is as impartial as possible. To this end, we styled our tests after the TPC Benchmark™ DS (TPC-DS) and then modeled our bench test bed after a real-world Hadoop cluster configuration. We will provide more detail but here are some highlights from our benchmark findings on fifty test queries.
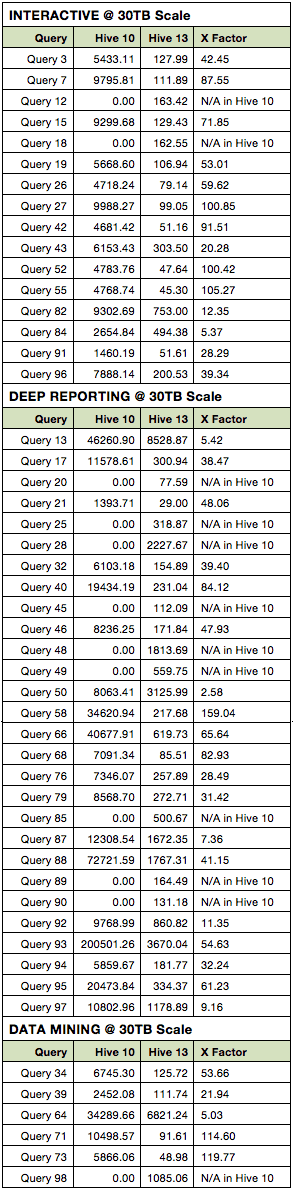
For a complete description of all the queries and complete results, please view this slideshare presentation.
Speed
Stinger outlined an open roadmap to improve Apache Hive’s performance 100x. The 3 major pieces driving performance gain are Apache Tez, the next-generation data processing engine for Hadoop that enables batch and interactive data processing at large scale, Hive’s new Vectorized Query engine, and ORCFile, a columnar format providing high compression and high performance. As we detail in the results section below, 100x performance improvement was achieved across many queries and many different types of SQL analytics.
- More than 100x speedup on 6 out of 50 queries
- Average speedup of 66x on interactive queries
- Average speedup of 52x across all 50 queries
- Total time to run all queries decreased from 7.8 days to 9.3 hours
Scale
Stinger improved Hive’s scalability in several ways. Of course, the performance benefits delivered by Hive’s Vectorized Query engine allows you to process more data in less time. Less obvious perhaps, is the fact that using Tez means that Hive jobs, that used to require many distinct MapReduce jobs, are now processed in a single Tez job. In one extreme case, Query 88 went from 39 distinct MapReduce jobs to a single Tez job. One other very valuable item was improvements to dynamic partitioning, making it much easier to load large amounts of data into large numbers of partitions in a single shot.
- 17 of 50 queries join more than 1 fact table
- Query 49 joins a total of 6 fact tables
- Query 98, a data mining query returned more than 23 GB of data and almost 70 million rows
- Query 96, a full table scan that hits about 40% of the entire warehouse, ran almost 40x faster
SQL
Stinger wasn’t just focused on performance. Over the past year Hive has expanded its SQL capabilities tremendously, including windowing functions, subqueries, datatypes like CHAR and VARCHAR, and much more. Hive has by far the most comprehensive SQL support in the open source Hadoop ecosystem, along with the most certifications, the most integrations, and is proven as the most scalable and robust solution available natively in Hadoop.
- Total of 50 queries run, covering interactive, deep reporting, and data mining queries
- 12 of the 50 were not supported by Hive 0.10.0 because windowing functions, sub-queries in IN clause, missing data types, and expanded JOIN syntax support were not supported. Hive 0.13.0 now supports all of these queries.
Broad Testing, Completely Open
In total, we ran tests on 50 queries and tested at a scale factor of 30,000 for each. In keeping with complete openness, we provide you with detailed results on SlideShare.
The results are grouped by queries in three categories:
- Interactive Queries: Star schema joins over single fact tables, which may involve advances SQL features such as windowing functions or rollups
- Deep Reporting: Complex queries involving multiple fact tables or large intermediate datasets
- Data Mining: Queries that return large amounts of data for further processing by other tools
Benchmark Configuration
In addition, we also provide a comprehensive description of the configuration of the benchmark setup along with the test bench for data generation and the queries themselves.
Software: |
Hardware: |
Hive 0.13.0 SetupHDP 2.1 General Availability
HDP was deployed using Ambari 1.5.1. For the most part, the cluster used the Ambari defaults (except where noted below). Hive 0.13.0 runs were done using Java 7 (default JVM). Tez and MapReduce were tuned to process all queries using 4 GB containers at a target container-to-disk ratio of 2.0. The ratio is important because it minimizes disk thrash and maximizes throughput. Other Settings:
Note: this is 1/3 of the Xmx value, about 1.7 GB. The following additional optimizations were used for Hive 0.13.0:
Hive 0.10.0 Setup Hive 0.10.0 is not included in Hortonworks HDP 2.1 and needed to be built manually.
The following optimizations were used for Hive 0.10.0:
|
20 physical nodes, each with:
Notes: Based on the YARN Node Manager’s Memory Resource setting used below, only 48 GB of RAM per node was dedicated to query processing, the remaining 200 GB of RAM were available for system caches and HDFS. Linux Configurations:
|
Data: |
Queries: |
|
|
Execution:
- Queries were executed serially and their results recorded. 50 queries were divided into 2 buckets, small and large based on expected execution duration.
- Under Hive 0.13.0, small queries were executed 5 times and large queries were executed 3 times. In both cases, the average execution time was used as the official time.
- Under Hive 0.10.0, due to long execution times, both small and large queries were executed only once. Despite this, the full suite took more than 7 days to fully execute. The reported time is the result of the single execution.
Comparing Benchmarks
There are a lot of published benchmarks that compare SQL options for Hadoop. We welcome you to compare the solutions yourself, however, if you rely on “published” versions, please take into consideration the following (for convenience, we have annotated them with details of our benchmark in parenthesis):
- Version numbers of software tested (hive-0.13, tez-0.4, hadoop-2.4.0)
- Cluster Configuration
- Number of nodes (20 machines)
- Available memory* (256GB per node, even though this benchmark only used 48GB for running the Hive queries)
- Disks* (6 HDDs each of 4TB – optimized for storage rather than I/O performance)
- Benchmark Definition
- Complexity of queries (simple queries, complex ones with multiple fact-tables etc.)
- Number of queries reported in the benchmark (50)
- Size of dataset benchmarked (30TB)
- Our benchmark used 48GB of available memory to run 12 processes (tasks) with 4GB each. This is the near optimal ratio of processes to drives for a machine with the I/O bandwidth available from 6 HDDs. We recommend 12x3TB or 12x4TB in production for better I/O bandwidth/throughput.
Summary:
Customers use Hive for complex query use cases and want the same data types and complexities of query semantics to work on large datasets as well as datasets more suitable to interactive use cases. The queries that we explored within this benchmark go well beyond simple tests, which assume you have only one big table or that the data set can fit into some pre-defined memory space.
Business analysts, data scientists, or other data workers should not require specialized query syntax, comprehensive knowledge of the underlying configuration of the engine or the platform it resides upon, nor a priori knowledge of either the data set size or expected results in order to be successful.
Our goal is simple; provide a single SQL-based query engine that delivers Speed, at Scale, with the broadest possible SQL query semantics and data types. Stinger has delivered impressive results – supporting interactive, ad hoc, deep reporting, and data mining queries.
The End of The Beginning
Though the Stinger Initiative is complete, the rate of innovation in Hive continues at an amazing rate, focused on the 3 key themes of Speed, Scale and SQL. As Hive improves, performance will only continue to get better, powered by features like the Cost-Based Optimizer (CBO), and more extensive in-memory processing. Hive will also soon see major new SQL functionality like ACID support. As the Stinger initiative comes to a close, the future of Hive and the future of Hadoop look very bright.