Article Source
- Title: Elements of Scale: Composing and Scaling Data Platforms
- Authors: Ben Stopford
Elements of Scale: Composing and Scaling Data Platforms
As software engineers we are inevitably affected by the tools we surround ourselves with. Languages, frameworks, even processes all act to shape the software we build.
Likewise databases, which have trodden a very specific path, inevitably affect the way we treat mutability and share state in our applications.
Over the last decade we’ve explored what the world might look like had we taken a different path. Small open source projects try out different ideas. These grow. They are composed with others. The platforms that result utilise suites of tools, with each component often leveraging some fundamental hardware or systemic efficiency. The result, platforms that solve problems too unwieldy or too specific to work within any single tool.
So today’s data platforms range greatly in complexity. From simple caching layers or polyglotic persistence right through to wholly integrated data pipelines. There are many paths. They go to many different places. In some of these places at least, nice things are found.
So the aim for this talk is to explain how and why some of these popular approaches work. We’ll do this by first considering the building blocks from which they are composed. These are the intuitions we’ll need to pull together the bigger stuff later on.

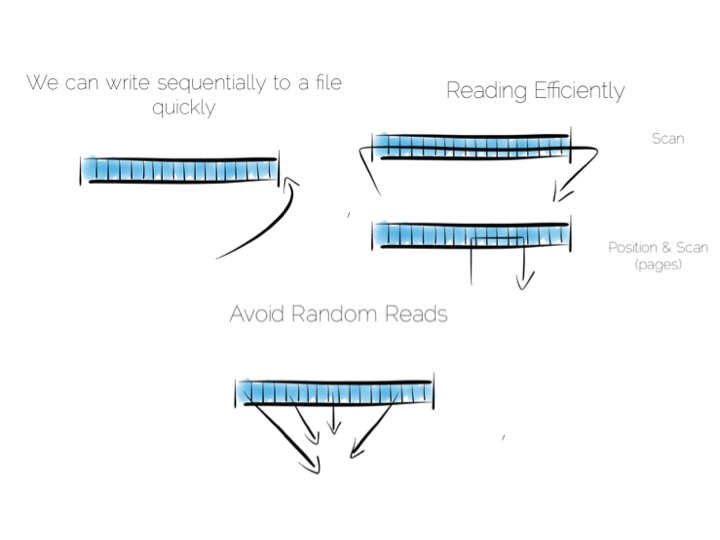
In a somewhat abstract sense, when we’re dealing with data, we’re really just arranging locality. Locality to the CPU. Locality to the other data we need. Accessing data sequentially is an important component of this. Computers are just good at sequential operations. Sequential operations can be predicted.
If you’re taking data from disk sequentially it’ll be pre-fetched into the disk buffer, the page cache and the different levels of CPU caching. This has a significant effect on performance. But it does little to help the addressing of data at random, be it in main memory, on disk or over the network. In fact pre-fetching actually hinders random workloads as the various caches and frontside bus fill with data which is unlikely to be used.

Whilst disk is somewhat renowned for its slow performance, main memory is often assumed to simply be fast. This is not as ubiquitously true as people often think. There are one to two orders of magnitude between random and sequential main memory workloads. Use a language that manages memory for you and things generally get a whole lot worse.
Streaming data sequentially from disk can actually outperform randomly addressed main memory. So disk may not always be quite the tortoise we think it is, at least not if we can arrange sequential access. SSD’s, particularly those that utilise PCIe, further complicate the picture as they demonstrate different tradeoffs, but the caching benefits of the two access patterns remain, regardless.

So lets imagine, as a simple thought experiment, that we want to create a very simple database. We’ll start with the basics: a file.
We want to keep writes and reads sequential, as it works well with the hardware. We can append writes to the end of the file efficiently. We can read by scanning the the file in its entirety. Any processing we wish to do can happen as the data streams through the CPU. We might filter, aggregate or even do something more complex. The world is our oyster!