Article Source
- Title: Elements of Scale: Composing and Scaling Data Platforms
- Authors: Ben Stopford
Immutability
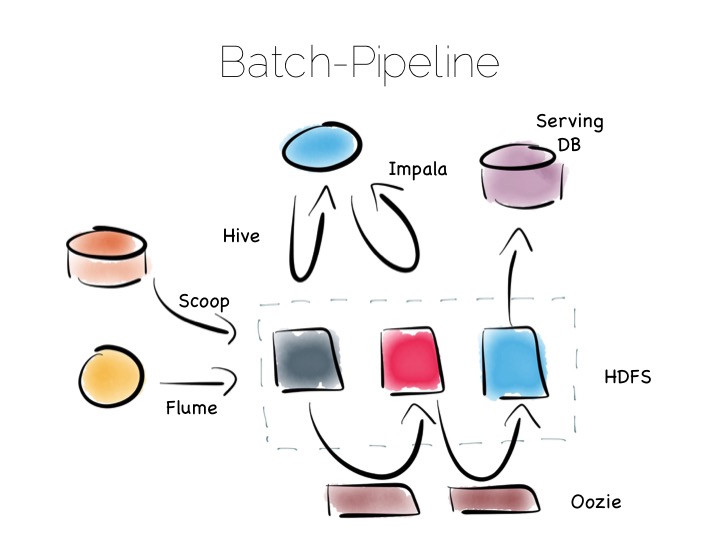
If we are designing for an immutable world, it’s easier to embrace larger data sets and more complex analytics. The batch pipeline, one almost ubiquitously implemented with the Hadoop stack, is typical of this.
The beauty of the Hadoop stack comes from it’s plethora of tools. Whether you want fast read-write access, cheap storage, batch processing, high throughput messaging or tools for extracting, processing and analysing data, the Hadoop ecosystem has it all.
The batch pipeline architecture pulls data from pretty much any source, push or pull. Ingests it into HDFS then processes it to provide increasingly optimised versions of the original data. Data might be enriched, cleansed, denormalised, aggregated, moved to a read optimised format such as Parquet or loaded into a serving layer or data mart. Data can be queried and processed throughout this process.
This architecture works well for immutable data, ingested and processed in large volume. Think 100’s of TBs plus. The evolution of this architecture will be slow though. Straight-through timings are often measured in hours.
The problem with the Batch Pipeline is that we often don’t want to wait hours to get a result. A common solution is to add a streaming layer aside it. This is sometimes referred to as the Lambda Architecture.
The Lambda Architecture retains a batch pipeline, like the one above, but it circumvents it with a fast streaming layer. It’s a bit like building a bypass around a busy town. The streaming layer typically uses a streaming processing tool such as Storm or Samza.
The key insight of the Lambda Architecture is that we’re often happy to have an approximate answer quickly, but we would like an accurate answer in the end.
So the streaming layer bypasses the batch layer providing the best answers it can within a streaming window. These are written to a serving layer. Later the batch pipeline computes an accurate data and overwrites the approximation.
This is a clever way to balance accuracy with responsiveness. Some implementations of this pattern suffer if the two branches end up being dual coded in stream and batch layers. But it is often possible to simply abstract this logic into common libraries that can be reused, particularly as much of this processing is often written in external libraries such as Python or R anyway. Alternatively systems like Spark provide both stream and batch functionality in one system (although the streams in Spark are really micro-batches).
So this pattern again suits high volume data platforms, say in the 100TB+ range, that want to combine streams with existing, rich, batch based analytic function.

There is another approach to this problem of slow data pipelines. It’s sometimes termed the Kappa architecture. I actually thought this name was ‘tongue in cheek’ but I’m now not so sure. Whichever it is, I’m going to use the term Stream Data Platform, which is a term in use also.
Stream Data Platform’s flip the batch pattern on its head. Rather than storing data in HDFS, and refining it with incremental batch jobs, the data is stored in a scale out messaging system, or log, such as Kafka. This becomes the system of record and the stream of data is processed in real time to create a set of tertiary views, indexes, serving layers or data marts.
This is broadly similar to the streaming layer of the Lambda architecture but with the batch layer removed. Obviously the requirement for this is that the messaging layer can store and vend very large volumes of data and there is a sufficiently powerful stream processor to handle the processing.
There is no free lunch so, for hard problems, Stream Data Platform’s will likely run no faster than an equivalent batch system, but switching the default approach from ‘store and process’ to ‘stream and process’ can provide greater opportunity for faster results.

Finally, the Stream Data Platform approach can be applied to the problem of ‘application integration’. This is a thorny and difficult problem that has seen focus from big vendors such as Informatica, Tibco and Oracle for many years. For the most part results have been beneficial, but not transformative. Application integration remains a topic looking for a real workable solution.
Stream Data Platform’s provide an interesting potential solution to this problem. They take many of the benefits of an O/A bridge – the variety of asynchronous storage formats and ability to recreate views – but leave the consistency requirement isolated in, often existing sources:
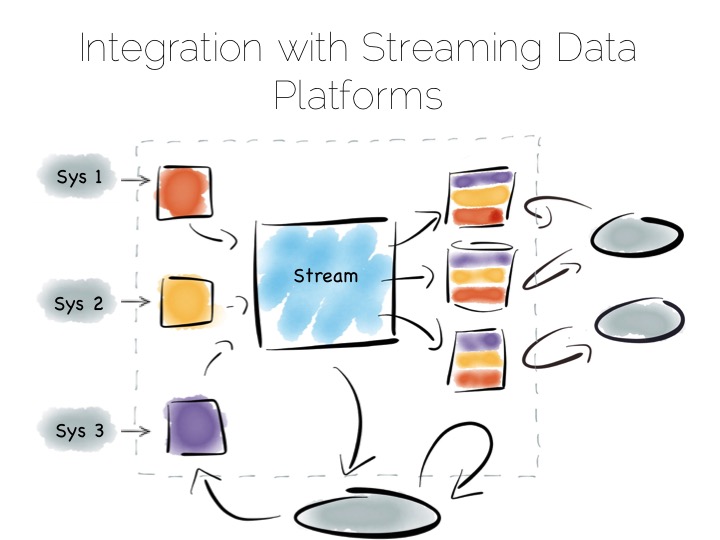
With the system of record being a log it’s easy to enforce immutability. Products like Kafka can retain enough volume internally to be used as a historic record. This means recovery can be a process of replaying and regenerating state, rather than constantly checkpointing.
Similarly styled approaches have been taken before in a number of large institutions with tools such as Goldengate, porting data to enterprise data warehouses or more recently data lakes. They were often thwarted by a lack of throughput in the replication layer and the complexity of managing changing schemas. It seems unlikely the first problem will continue. As for the later problem though, the jury is still out.
So we started with locality. With sequential addressing for both reads and writes. This dominates the tradeoffs inside the components we use. We looked at scaling these components out, leveraging primitives for both sharding and replication. Finally we rebranded consistency as a problem we should isolate in the platforms we build.
But data platforms themselves are really about balancing the sweet-spots of these individual components within a single, holistic form. Incrementally restructuring. Migrating the write-optimised to the read-optimised. Moving from the constraints of consistency to the open plains of streamed, asynchronous, immutable state.
This must be done with a few things in mind. Schemas are one. Time, the peril of the distributed, asynchronous world, is another. But these problems are manageable if carefully addressed. Certainly the future is likely to include more of these things, particularly as tooling, innovated in the big data space, percolates into platforms that address broader problems, both old and new.
THINGS WE LIKE