Article Source
- Title: sampleclean
SampleClean
Data Cleaning With Algorithms, Machines, and People
Analysts report spending upwards of 80% of their time on problems in data cleaning including extraction, formatting, handling missing values, and entity resolution. As a part of the SampleClean project, we are developing scalable techniques for data cleaning and statistical inference on dirty data.
Introduction
The data cleaning process is inherently iterative, usually starting with cursory exploratory data analysis on small samples where the analyst manually fixes errors and estimates their impact. As the analyst learns more about the dataset, she often refines the cleaning to make it more accurate and robust. SampleClean implements a set of interchangeable and composable physical and logical data cleaning operators. This allows for quick construction and adaptation of data cleaning pipelines
The case for optimized cleaning operators
Many data scientists clean and wrangle data with one-off scripts. This leads to unreliable software and brittle workflows that transfer data between different programs. In our research, we identify a set of logical operators commonly found in data cleaning workflows: Sampling, Similiarity Join, Filtering, and Extraction. We build an API around these logical operators allowing them to be executed and optimized at a physical level.
Optimized Similarity Join: Deduplication, entity resolution, and outlier detection use an operator called “Similarity Join”. Given two relations, this finds all pairs that satisfy some similarity condition. A naive implementation would require applying the metric to all pairs of tuples. In SampleClean, we apply prefix-filtering to reduce the number of tuple comparisons. Programs that use the logical operator can benefit from all of our optimizations. In many applications, an approximate answer suffices. In SampleClean, we allow users to clean samples of data and extrapolate results. Below, we show a subset of restaurant records from a yelp challenge dataset where 15% are duplicates. SampleClean’s deduplication implementation is significantly faster than the naive all pairs implementation and sampling allows the user to tradeoff between accuracy and time.

Active Learning: Crowd input is expensive and SampleClean is parsimonious with the questions it asks to the crowd. We apply a technique called active learning to budget crowd effort. As crowd responses arrive, we train a model to predict the responses. We then apply the crowd to the most uncertain predictions. Below, we plot the query error in a value filling task. As crowd workers fill in values, we can learn what values to add. We find that Active learning provides a significant benefit for small sample sizes and is very valuable for early results/evaluations.

Tuning without rewriting: Many data cleaning physical implementations are sensitive to parameterization. By abstracting physical implementations, users can easily try different techniques and parameters.
Steps in a typical cleaning workflow
Sample data and explore with aggregate statistics

Simple rule or regular expression based cleaning
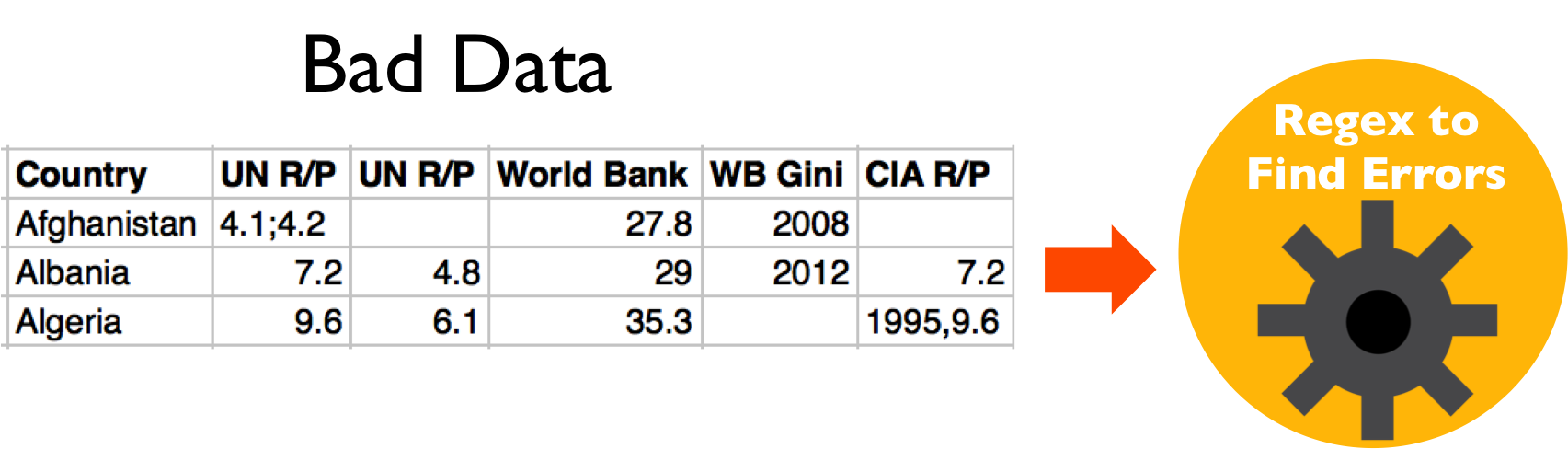
Refinement with crowd sourcing

Talks, Presentations, and Publications
Publications
Jiannan Wang, Sanjay Krishnan, Michael Franklin, Ken Goldberg, Tim Kraska, Tova Milo. A Sample-and-Clean Framework for Fast and Accurate Query Processing on Dirty Data. In SIGMOD 2014
Jeffrey Mahler, Sanjay Krishnan, Michael Laskey, Siddarth Sen, Adithyavairavan Murali, Ben Kehoe, Sachin Patil, Jiannan Wang, Mike Franklin, Pieter Abbeel, Ken Goldberg.Learning Accurate Kinematic Control of Cable-Driven Surgical Robots Using Data Cleaning and Gaussian Process Regression. In CASE 2014.
Sanjay Krishnan, Jiannan Wang, Michael Franklin, Ken Goldberg, Tim Kraska Stale View Cleaning: Getting Fresh Answers From Stale Materialized Views. Under Review VLDB 2015.
Daniel Haas, Sanjay Krishnan, Jiannan Wang, Michael J. Franklin, Eugene Wu. Wisteria: Nurturing Scalable Data Cleaning Infrastructure.Under Review VLDB 2015.