Article Source
- Title: Improving Spark for Data Pipelines with Native YARN Integration
- Authors: Gopal Vijayaraghavan and Oleg Zhurakousky
Improving Spark for Data Pipelines with Native YARN Integration
Spark on Tez for efficient ETL
A few weeks back, we outlined a broad initiative to invest in Spark in the context of the Hadoop ecosystem. We intend to facilitate a more efficient utilization of Hadoop cluster resources for ETL and/or Data Pipeline workloads when using Spark. Many of the lessons learned while building out MapReduce, Apache Tez and other YARN data-processing frameworks can be applied to the Spark project in order to optimize its resource utilization and to make it a good multi-tenant citizen within a YARN-based Hadoop cluster.
Here we present some of our initial findings and improvements to Spark that are based off the latest Spark release (spark-1.1). In the following discussion, they will be referred to as Spark (original) and Spark (improved), which with the help of the pluggable execution context proposed in Spark (SPARK-3561) provides significant improvements to Spark, particularly in multi-tenant environments prevalent in large enterprises.
This post is certainly not intended as a processing benchmark, since we execute identical Spark code (filters, mappers, reducers etc.) with the only difference being is in an improved execution context provided by YARN & Tez. However, the scalability problem here that is worthy of Amdahl’s law is the interconnect & exchange layer that all tasks have to share and handle with care.
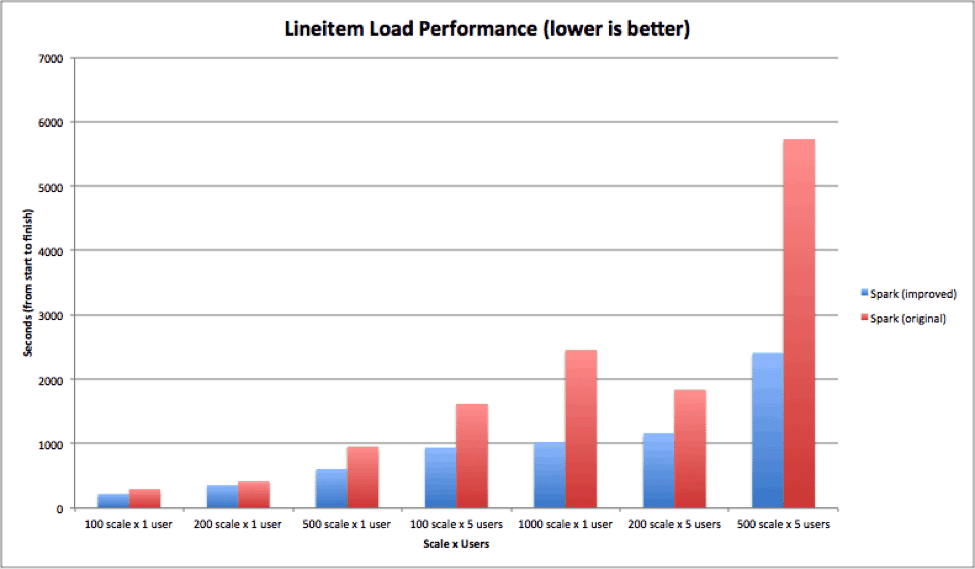
Spark (original) v Spark (improved): Initial Results
These experiments were run on a 20 node YARN cluster, with 12 cores each, 6x1TB disks, 64Gb RAM, 10GigE. The cluster has an aggregate RAM of 800Gb available to both Spark (original) and Spark (improved) – all data in this workload fits within aggregate ram, twice over.
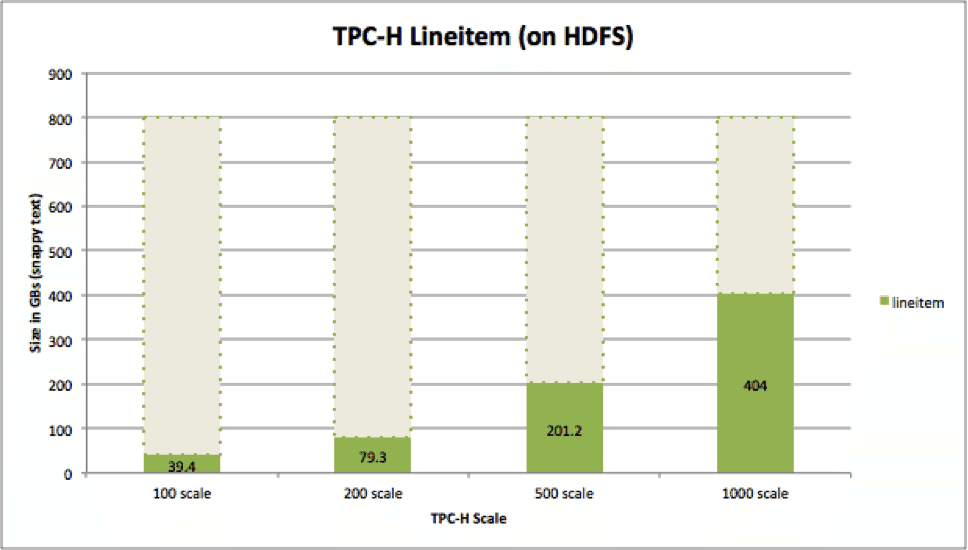
A simple classification application will serve as our workload – this particular workload has provenance from the TPC-H benchmark – it takes data from TPC-H lineitem table in text format and partitions it by L_SHIPDATE into per-date text files.
Following is the key part of the workload used for our testing:
val result = source
.map(a => (a.split('|')(10), a))
.partitionBy(new HashPartitioner(reducers))
.saveAsHadoopFile(outputPath, classOf[Text], classOf[Text],
classOf[KeyPerPartitionOutputFormat])
Spark (original) takes the direct approach of exchanging data between executors through its ShuffleManager, while Spark (improved)is using the shuffle mechanism that is part of YARN and secured by the well-known authentication mechanisms of Hadoop.
Significant effort was spent to tune Spark (original) to support the larger data set – ConsolidateFiles is enabled to avoid hitting system limits during shuffle, and shuffle memoryFraction was increased at the expense of cache-storage memoryFraction to support larger shuffle sizes. In addition, the reducer counts were tuned to not hit the inherent 2GB shuffle limits and higher scale runs were abandoned because of such shuffle errors. We also experimented with 8Gb, 24Gb and 40Gb executors to determine if the errors went away as executors got bigger. With the larger dataset, we still observed a significant task failures even after fine-tuning it using Spark (original).
All Spark (improved) runs were with identical configurations, with 4Gb executors and the default runtime memory scalar.
Analysis of Improvements
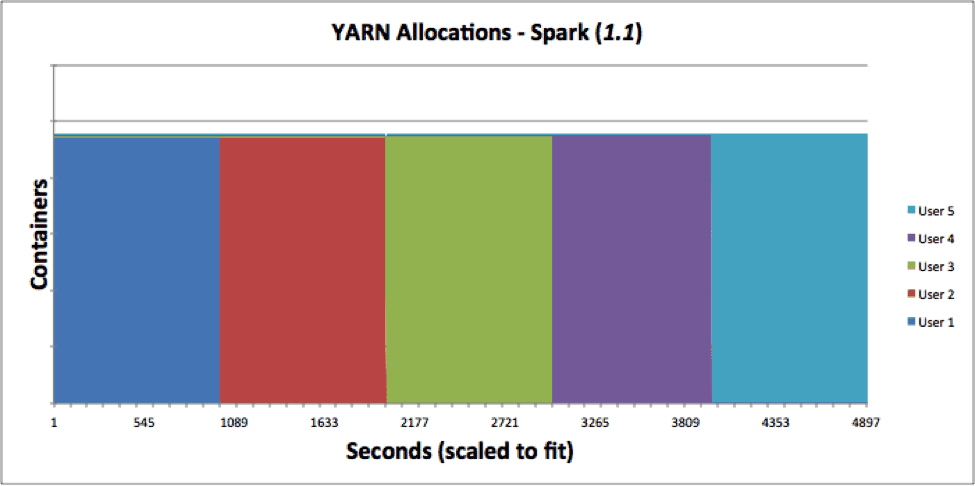
The multi-tenancy runs with multiple users favor engines purpose-built with elasticity. Spark (original) jobs cannot take advantage of any elasticity provided by YARN today, since it releases containers only at the end of the entire job.
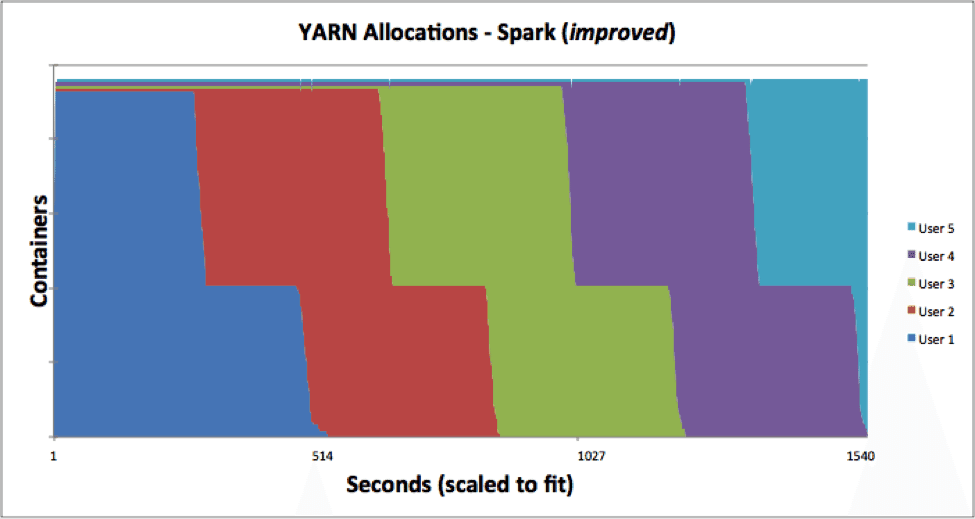
In comparison, the five user tests in Spark (improved) look like below, with the sharp kink where the flatMap stages are complete and allpartitionBy stages have started. As a result, the aggregate workload has a significantly higher throughput (nearly 3x). In fact, we expect to see higher throughput as we stress the system by packing more pipelines.
Conclusion
Apache Spark is one of the most exciting recent developments in the Hadoop ecosystem. At Hortonworks, we love Spark and want to help our customers leverage all its benefits. We also want to help make it scale better and leverage full benefits provided by YARN and Tez. We have provided the improved Spark in two versions, as a tarball and in source form on github.
We encourage you to play with it and reproduce the benefits for yourself. Go ahead, leverage an improved Spark!
Acknowledgements
We’d like to thank everyone in the Apache Spark community for their help and, in particular, early users who have used beta versions of the software and provided us with their feedback.