Article Source
- Title: Introduction to Data Science with Apache Spark
- Authors: Ram Sriharsha
Introduction to Data Science with Apache Spark
Get started with Zeppelin on HDP - Part 1
Apache Spark provides a lot of valuable tools for data science. With our release of Apache Spark 1.3.1 Technical Preview, the powerful Data Frame API is available on HDP.
Data scientists use data exploration and visualization to help frame the question and fine tune the learning. Apache Zeppelin helps with this.
Based on the concept of an interpreter that can be bound to any language or data processing backend, Zeppelin is a web based notebook server. As one of its backends, Zeppelin implements Spark, and other implementations, such as Hive, Markdown, D3 etc., are also available.
In a series of blog posts, we will describe how Zeppelin, Spark SQL and MLLib can be combined to simplify exploratory Data Science.In the first post of this series, we describe how to Install / Build Zeppelin for HDP 2.2 and uncover some basic capabilities for data exploration that Zeppelin offers.
We assume that HDP 2.2 has been installed on the cluster along with Spark.
Spark can either be installed as a service using Ambari 2.0 or can be downloaded and configured as described here.
In either case, denote **spark.home** as the location of the root of the Spark installation.
Building Zeppelin
Choose a cluster node that does not contain the datanode or namenode if possible to build and run Zeppelin. This is to ensure that Zeppelin has enough processing resources on that node. Check out Zeppelin from github:
git clone https://github.com/apache/incubator-zeppelin.git
cd incubator-zeppelin
To build against Spark 1.3.1, issue the following command:
mvn clean install -DskipTests -Pspark-1.3 -Dspark.version=1.3.1 -Phadoop-2.6 -Pyarn
To To build Zepplein against Spark 1.2.1, issue the following command:
mvn clean install -DskipTests -Pspark-1.2 -Phadoop-2.6 -Pyarn
In the previous step, we built Zeppelin with Spark-1.3.1 and Hadoop 2.6
Now determine the HDP version you are running using:
hdp-select status hadoop-client | sed 's/hadoop-client - \(.*\)/\1/'
This should yield something like
2.2.4.2-2
Let’s call this parameter **hdp.version**
Edit conf/zeppelin-env.sh to add the following lines:
export HADOOP_CONF_DIR=/etc/hadoop/conf
export ZEPPELIN_PORT=10008
export ZEPPELIN_JAVA_OPTS="-Dhdp.version=$hdp.version"
Copy hive-site.xml from /etc/hive/conf/hive-site.xmlto conf/ folder
Create a directory in HDFS for the user that Zeppelin will run as (eg.
zeppelin)
su hdfs
hdfs dfs -mkdir /user/zeppelin;hdfs dfs -chown zeppelin:hdfs /user/zeppelin>
Launch Zeppelin using
bin/zeppelin-daemon.sh start
This will launch a notebook server and bring up a Web UI on port 10008
Navigate to http://$host:10008 to access the notebooks. Change tabs to the Interpreter page in order to set a few properties.
Configuring Zeppelin
The following properties must be overridden in $SPARK_HOME/conf/spark-defaults.conf to run the Interpreter in YARN client mode:
master yarn-client
spark.driver.extraJavaOptions -Dhdp.version=$hdp.version
spark.home $spark.home
spark.yarn.am.extraJavaOptions -Dhdp.version=$hdp.version
spark.yarn.jar $zeppelin.home/interpreter/spark/zeppelin-spark-0.5.0-SNAPSHOT.jar
Once these configurations are updated, Zeppelin will prompt you to restart the interpreter. Accept the prompt and the interpreter will reload the configurations.
At this point, we are ready to take Zeppelin notebook for a spin. Navigate to http://$host:10008
You should see a screenshot like the one below:
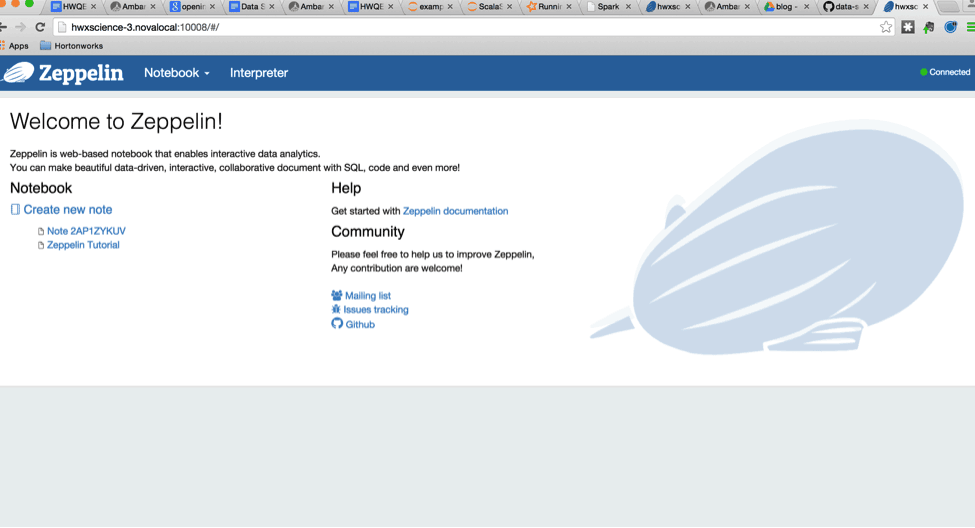
Click on “Create new note” in order to open a fresh notebook.
Writing Scala in the Notebook
On any Ambari managed cluster, the ambari-agent logs are written to /var/log/ambari-agent/ambari-agent.log.
We will write some Scala code inside Zeppelin to visualize these logs and extract information contained in them.
In order to view the contents of this log and manipulate them subsequently, we will create an RDD out of the log file.
val ambariLogs = sc.textFile("file:///var/log/ambari-agent/ambari-agent.log")
The above line of code binds the contents of the text file to an RDD represented by the variable ambariLogs.
In order to better visualize what the logs contain, we will dump a few lines of text onto the interpreter console using:
ambariLogs.take(10).mkString("\n")
The output should look something similar to this:
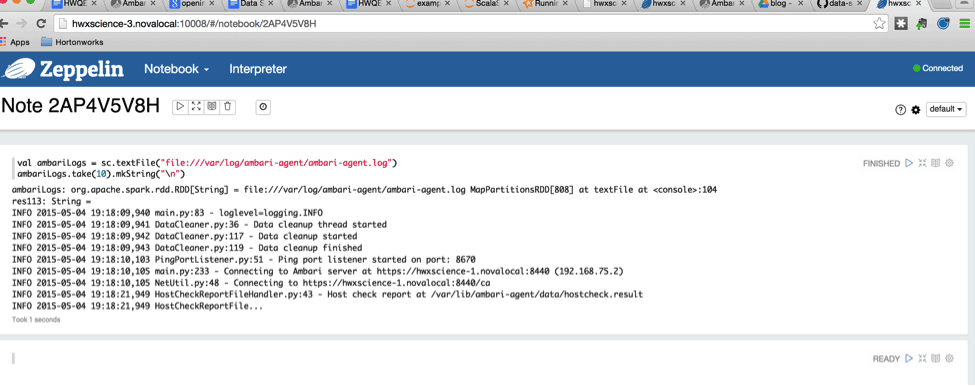
Working with Spark SQL
To further analyze the logs, it is better to bind them to a schema and use Spark’s powerful SQL query capabilities.
A powerful feature of Spark SQL is that you can programmatically bind a schema to a Data Source and map it into Scala case classes which can be navigated and queried in a typesafe manner.
For our present analysis we can treat a line of the ambari logs as consisting of four essential components, each separated by a whitespace.
- Log Level (INFO, DEBUG, WARN etc)
- Date (YYYY-mm-dd)
- Time (HH:mm:ss,SSS format)
- File Name
Let us create a case class to bind to this schema:
// sc is an existing SparkContext.
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
// this is used to implicitly convert an RDD to a DataFrame.
import sqlContext.implicits._
// Define the schema using a case class.
import java.sql.Date
case class Log(level: String, date: Date, fileName: String)
Note: We combine date and time into a Date object for convenience.
import java.text.SimpleDateFormat
val df = new SimpleDateFormat("yyyy-mm-dd HH:mm:ss,SSS")
val ambari = ambariLogs.map { line =>
val s = line.split(" ")
val logLevel = s(0)
val dateTime = df.parse(s(1) + " " + s(2))
val fileName = s(3).split(":")(0)
Log(logLevel,new Date(dateTime.getTime()), fileName)}.toDF()
ambari.registerTempTable("ambari")

After a dataframe is instantiated, we can query it using SQL queries. Dataframes are designed to take the SQL queries constructed against them and optimize the execution as sequences of Spark Jobs as required.
For example, suppose we want to determine by log level, the count of events across time. In SQL, we would have issued a query of the form:
SELECT level, COUNT(1) from ambari GROUP BY level
But using the Scala Data Frame API, you could issue the following query:
ambari.groupBy("level").count()
At which point, something very close to native SQL can be used for querying like:
sqlContext.sql("SELECT level, COUNT(1) from ambari group by level")
This returns the same data structure as returned in the DataFrame API. The data structure returned is itself a data frame.
At this point, no execution has occurred: The operations on data frames get mapped to appropriate operations on the RDD (in this case
RDD.groupBy(...).aggregateByKey(...))
We can force execution by doing say collect() on the results to bring the results of the execution into driver memory.
Visualizing with Zeppelin
One of the powerful features of Zeppelin Notebook is that you can view the result set of the previous section within the same framework. Zeppelin’s display system plugs into standard output.
Any string that is outputted to standard output via println can be intercepted by Zeppelin’s display system if it is followed first by the interpreter command say %table, or %img, or %html etc.
In our case, we would like to output the count of logs by log level as a table, so we use the following snippet of code:
import org.apache.spark.sql.Row
val result = sqlContext.sql("SELECT level, COUNT(1) from ambari group by level").map {
case Row(level: String, count: Long) => {
level + "\t" + count
}
}.collect()
This assembles the output of the groupby into a format that is suitable for the table interpreter to render.
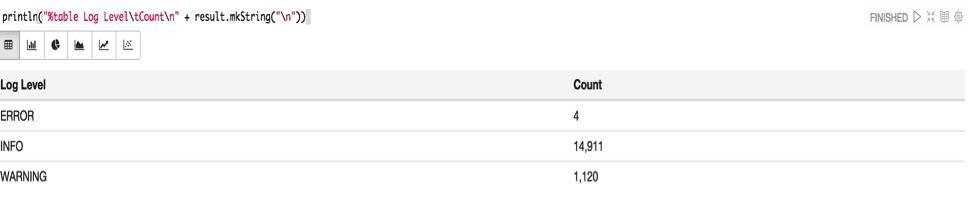
%table requires the rows each to be separated by “\n” (next line) and columns to be separated by “\t” (tab) characters respectively, as below:
println("%table Log Level\tCount\n" + result.mkString("\n"))
The rendering produced by the above print command should look something like this:
Wrapping Up
Data Scientists use a lot of tools. With Zeppelin they now get a new tool to ask better questions. In the next blog post, we will do a deep dive on a specific data science problem, and show you how to use Zeppelin, Spark SQL and MLLib in order to put together a data science project using HDP and Spark together with Zeppelin.