Tajo Cluster Architecture
Terminology
- Execution Block - A distributed query plan consists of a tree of execution blocks. In other words, a logical plan of a query statement is broken into multiple parts, each of which is included in an execution block. Each execution block is a distributed processing phase which is similar to map or reduce phase in MapReduce. A number of tasks are created with the logical plan and control flags of an execution block.
- SubQuery - It is a control instance and a state machine for an execution block.
- QueryUnit (Task) - QueryUnit indicates a Task. In the design stage, we named QueryUnit to indicate a task. Recently, we are changing QueryUnit to Task.
- QueryUnitAttempt - Like MapReduce, each running query unit (task) has an attempt instance and an attempt id. A task can be restarted if it is failed. So, we need a way to identify failed or succeeded tasks.
TaskRunnerLaunchImpl class
The main objective of TaskRunnerLaunchImpl is to launch TaskRunner through Yarn’s ContainerManager.
The TaskRunnerLaunchImpl class handles two events CONTAINER_REMOTE_LAUNCH and CONTAINER_REMOTE_CLEANUP, which lead to launching a TaskRunner and killing a running TaskRunner respectively. These events come from SubQuery::allocateContainers(SubQuery) method.
Task
In TaskRunner, a Task is created from the response (QueryUnitRequest) of ‘getTask()’ rpc call. Task contains three main attributes as follows:
- A logical plan of an execution block which created the task.
- A fragment - an input path, an offset range, and schema. This is available only if the execution is leaf.
- Fetch URIs - HTTP URIs to fetch the results processed by TaskRunners of the previous execution block. This is available only if the execution is non-leaf.
Initially, a Task registers fetch URIs to fetchLauncher (ExecutorService) in order to pull data, and it restore a logical plan.
Then, a physical operator tree is created from the logical plan via PhysicalPlannerImpl. Finally, Task::run() method is called, and then Task’s status is changed to RUNNING.
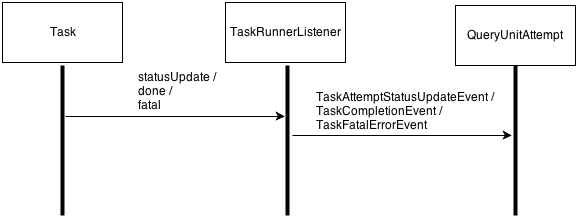
Also, a running Task periodically sends a statusUpdate report to TaskRunnerListener via RPC. A StatusUpdate report includes a status and some statistics of the running task. If the running task is failed, TaskRunner sends a message ‘fatal’ to TaskRunnerListenerImpl. If the task is completed, TaskRunner sends a message ‘done’ to TaskRunnerListenerImpl.
TaskRunner
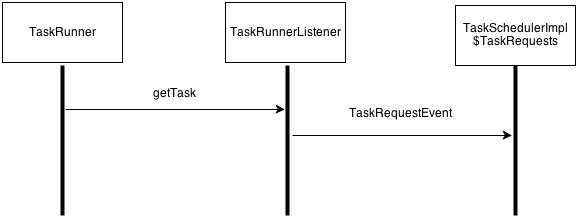
For each execution block, TaskRunner is launched by Yarn’s ContainerManager. TaskRunner processes a Task at a time. If TaskRunner has an available slot, it sends ‘getTask’ to TaskRunnerListner. If TaskRunner receives the response (QueryUnitRequest) of ‘getTask’ message, TaskRunner creates an instance of Task from the response.
TaskListenerImpl
It receives messages sent from a number of TaskRunners. It passes the received message as events to some event handlers, such as QueryUnitAttempt and TaskScheduler.
In the current implementation, there are four messages as follows:
- getTask
- When a TaskRunner has an empty slot, the TaskRunner sends this message to the TaskListenerImpl. This message is transformed to a TaskRequestEvent which is passed to the TaskSchedulerImpl$TaskRequests instance.
- statusUpdate
- a Task periodically sends this message to TaskRunnerListener via RPC. This message is transformed to a TaskAttemptStatusUpdateEvent which is passed to the QueryUnitAttempt instance corresponding to the identifier included in the statusUpdate message.
- done
- When a task attempt is completed, a Task sends this message to the TaskListenerImpl via RPC. This message is transformed to a TaskCompletionEvent which is passed to the QueryUnitAttempt instance corresponding to the identifier included in the done message.
- fatal
- When a task is failed, the task sends this message to the TaskRunnerListenerImpl via RPC. This message is transformed to a TaskFatalErrorEvent which is also passed to the QueryUnitAttempt instance corresponding to the identifier included in the fatal message.
A sequence diagram of statusUpdate, done, and fatal messages
A sequence diagram of getTask message
Tajo Cluster Architecture
A single Tajo cluster consists of the main components as follows:
- TajoMaster (1 <= N)
- TajoWorker (1 <= N)
TajoMaster is responsible for coordinating a number of TajoWorkers and provides a client services. TajoWorker actually processes data. As the number of TajoWorkers increases, the processing capacity will increase linearly. The detailed description are as follows:
TajoMaster
TajoMaster has three sub components:
QueryCoordinator: decides whether each query should be executed in a distributed way or be executed immediately in TajoMaster. If a query needs distributed execution, QueryCooordinator enqueues the query into query scheduler. If required cluster resources become available, the query scheduler will start queries. QueryCoordinator forwards a starting query to an arbitrary worker, and then the worker creates a QueryMasterTask instance which will controls and coordinates multiple stages and lots of tasks which will be executed across a number of nodes.
Resource Tracker: manages membership of cluster nodes. It detects a joining node to a Tajo cluster and leaving a node from a Tajo cluster. Resource Tracker receives heartbeat messages of them periodically, and maintains resources and healthy status of nodes via heartbeat messages. If some node is outage, Resource Tracker is responsible for notifying its node failure to QueryCoordinator. Then, QueryCoordinator will decide how to deal with the failure depending on the failure cases.
Client Service Provider: provides a set of remote APIs. Client Service Provider routes client API calls to proper QueryCoordinator or ResourceTracker.
Basically, one TajoMaster runs in a Tajo cluster, but in HA mode, two or more TajoMaster can run in a single Tajo cluster.
TajoWorker
TajoWorker has two sub components:
NodeResourceManager: manages resource of worker node. It decides allocating requests to the node. if available resources is not enough, part of request can be rejected, and sends an accepted tasks to TaskManager
TaskManager: launches task to the TaskExecutor and It uses multiple threads equal to the number of cpu-cores. When a task is completed, TaskManager releases the allocated resource and NodeStatusUpdater sends node status with latest resource status to the ResourceTracker in TajoMaster

CatalogServer
Tajo System Directory Hierarchy
The default system directory hierarchy is as follows:
[HDFS ROOT]
|
|-- tajo
| |
| |-- system
| | |-- resource
| | |-- system_conf.xml
| |-- warehouse
| |- [database A]
| | |- [table a]
| | |- [table b]
| |
| |- [database ..]
| |
| |- [database N]
| |- [table x]
| |- [table z]
|
|-- tmp
|-- staging
|- q_1378468137418_0001
| |- RESULT
|
|- q_1378468137418_0002
| |- RESULT
|
|- q_1378468137418_000N
root directory
- Tajo has a root directory (config key - ‘tajo.rootdir’)
- tajo.rootdir is configurable.
- tajo.rootdir contains a subdirectory ‘system’.
System directory
- system directory location is not configurable.
- system/resource directory contains ‘system_conf.xml’ which contains a global configuration used across a number of workers.
Warehouse directory
- It contains a subdirectory per table.
- If you execute CREATE TABLE statement, the table is stored in here as a subdirectory.
staging directory
- It contains a temporary directory for each query.
- Each temporary directory has a query id as a directory name.
- For each query, query results are stored temporarily in here. But these results will be removed after a while.
- If a query is either CREATE TABLE or INSERT TABLE, the query result is moved to the warehouse directory.