Article Source
Hadoop + GPU Architecture
분산형 컴퓨팅을 가능하게 하는 오픈 소스 프레임워크인 하둡(Hadoop)은 빅 데이터 처리 방식을 완전히 새롭게 바꿔어 놓았다. 하둡을 이용한 병렬 처리를 통해 성능을 몇 배나 향상시킬 수 있다.
그렇다면 이보다 더 빠른 처리도 가능할까? 만약 CPU에서의 연산 작업을 복잡한 3D와 수학 작업을 위해 설계한 GPU(Graphic Processing Unit)로 이전하면 어떨까? 이론적으로 프로세스가 병렬 컴퓨팅에 최적화되어 있는 경우 GPU는 CPU보다 50~100배 빠르게 연산을 수행한다.
알토로스 시스템즈(Altoros Systems)의 R&D 팀은 빅 데이터용 PaaS(platform-as-a-service)를 지원하고 대규모 시스템에서 무엇이 가능하며 무엇을 시도해 볼 수 있는지를 직접 검토했다.
사실 아이디어 자체는 전혀 새로울 것이 없다. 수 년 동안 과학 프로젝트들은 하둡 또는 맵리듀스(MapReduce) 관련 작업을 GPU로 처리하기 위해 노력해 왔다. 마스(Mars)는 최초로 그래픽 프로세서를 위한 맵리듀스 프레임워크 개발에 성공했다. 해당 프로젝트에서는 웹 데이터(검색/로그)를 분석하고 (행렬 곱셈을 포함해) 웹 문서를 처리할 때 성능을 1.5~1.6x 높일 수 있었다.
마스의 성과를 토대로 다른 연구기관에서 데이터 집중형 시스템의 처리 속도를 높이기 위해 유사한 툴을 개발했다. 분자 동력학, (몬테 카를로(Monte Carlo) 방식 등의) 수학적 모형, 블록 기반의 행렬 곱셈, 재무분석, 이미지 처리 등이 대표적이다.
이 중에서 가장 주목받고 있는 것 중 하나가 그리드 컴퓨팅용 미들웨어 시스템인 BOINC(Berkeley Open Infrastructure for Network Computing)이다. 하둡을 사용하는 것은 아니지만 이미 많은 과학 프로젝트에 사용되고 있다. 예를 들어 GPUGRID는 건강 및 질병에 있어서 단백질의 기능을 이해하는데 필요한 분사 시뮬레이션을 수행하기 위해 BOINC의 GPU 및 분산형 컴퓨팅을 사용하고 있다. 이밖에 약학, 물리학, 수학, 생물학 등과 관련된 대부분의 BOINC 프로젝트도 ‘하둡 + GPU’ 형태로 수행할 수 있다.
따라서 GPU를 이용한 병렬 컴퓨팅 성능을 높이려는 시도는 꾸준히 존재한다. 기업들은 GPU가 탑재된 슈퍼컴퓨터에 투자하거나 자체 솔루션을 개발하고 있다. 크레이(Cray) 등의 하드웨어 업체들은 GPU와 하둡을 미리 탑재한 제품을 선보이기도 했다. 아마존 역시 GPU가 탑재된 자사 클라우드 서버에서 하둡을 가능하게 하는 엘라스틱 맵리듀스(Elastic MapReduce, 아마존 EMR)를 출시했다.
하지만 하둡 + GPU 조합으로 모든 것을 해결할 수 있을까? 수퍼컴퓨터는 가장 강력한 성능을 제공하지만 수백만 달러의 비용이 든다. 아마존 EMR은 수 개월 동안 진행되는 프로젝트에만 적합하다. 2~3년 정도의 대형 과학 프로젝트의 경우 자체 하드웨어를 구입하는 것이 더 비용 효율적일 수 있다.
그렇다면 하둡 클러스터 내에서 GPU를 사용해 연산 속도를 높인다고 해도 데이터 전송과 관련된 성능의 병목현상은 어떻게 해결할까? 이 부분을 더 자세히 살펴보자.
원리
데이터 처리란 HDD, DRAM, CPU, GPU 사이의 데이터 교환을 의미한다. <그림 1>은 상용 머신이 CPU와 GPU를 이용한 연산을 수행할 때 데이터가 어떻게 전송되는지 보여준다.
<그림 1> CPU와 GPU를 이용한 연산 수행시 데이터 흐름
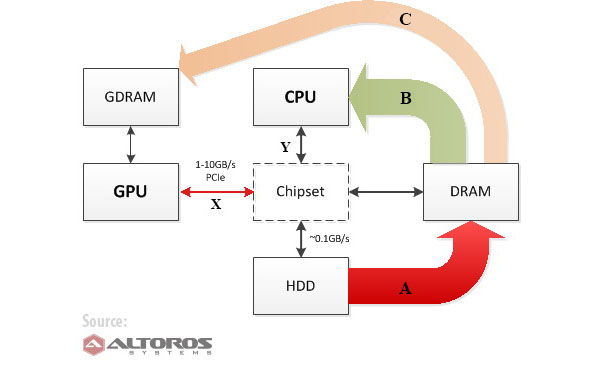
각 단계를 보면 화살표 A는 HDD에서 DRAM으로 데이터 전송하는 것으로 CPU와 GPU 컴퓨팅을 위한 보편적인 최초 단계다. 화살표 B는 CPU를 이용한 데이터 처리로 데이터가 DRAM, 칩셋, CPU 단계로 이동한다. 화살표 C는 GPU를 이용한 데이터 처리 단계로 데이터가 DRAM → 칩셋 → CPU → 칩셋 → GPU → GDRAM → GPU 순으로 이동한다.
결과적으로 이 모든 작업을 완료하기 위해 필요한 총 시간은 다음과 같다.
*- CPU 또는 GPU가 연산을 수행하는데 필요한 시간
- 그리고 모든 구성요소들 사이의 데이터 전송에 소요된 시간*
톰스 하드웨어(Tom’s Hardware, CPU 차트 2012)에 따르면 평균적인 CPU의 성능은 15~130GFLOPS 정도다. 엔비디아의 GPU 성능은 100~3,000+ GFLOPS이다. 이런 측정치는 모두 개략적인 것으로 실제 성능은 작업 유형과 알고리즘에 따라 천차만별이다.
어쨌든 경우에 따라서는 GPU가 노드당 5~25배 정도 연산 속도를 증가시킬 수 있다. 어떤 개발자들은 클러스터가 여러 개의 노드로 구성된 경우 성능을 50~200배까지 높일 수 있다고 말한다. 실제로 MITHRA 프로젝트 개발자들은 성능을 254배나 끌어올리는데 성공했다.
하지만 데이터 전송의 효과는 어떨까? 다양한 종류의 하드웨어가 다양한 속도로 데이터를 전송한다. 비록 수퍼컴퓨터가 GPU 작업에 최적화되어 있을 가능성이 높지만 일반적인 컴퓨터 또는 서버는 데이터를 교환할 때 훨씬 느릴 수 있다.
평균적인 CPU와 칩셋 사이의 데이터 전송 속도는 10~20GBps인 반면에 GPU와 DRAM 사이의 데이터 교환 속도는 1~10GBps이다. 경우에 따라 최대 10GBps(PCIe v3)에 근접할 수 있지만 대부분의 일반적인 환경에서 GPU의 DRAM(GDRAM)과 컴퓨터의 DRAM 사이의 데이터 흐름 속도는 1GBps이다 (CPU의 메모리 대역폭과 이에 해당하는 데이터 전송 속도는 같거나 약 10 정도 차이가 날 수 있기 때문에 실제 하드웨어에서 실제 값을 측정해 보는 것이 좋다).
따라서 GPU가 더 빠른 컴퓨팅 성능을 제공하지만 주요 병목현상은 GPU 메모리와 CPU 메모리 사이의 느린 데이터 전송에서 발생한다. 그러므로 모든 까다로운 프로젝트의 경우에 GPU 가속으로 절감한 시간 대비 GPU의 데이터 전송에 소요된 시간(<그림 1>의 화살표 С)을 측정해 보아야 한다. 이 때 가장 좋은 것은 소규모 클러스터에서 실제 성능을 평가하고 나서 대규모 시스템에서 어떻게 나타날 지를 예측해 보는 것이다.
이와 관련해 14종의 실제 사례를 통해 성능 결과치를 산출한 인텔의 2010년 연구가 좋은 참고자료다. 이에 따르면 단일 노드로 10~1000배의 성능 향상을 달성하는 경우는 사실상 불가능하고 2.5배 정도가 가장 현실적인 것으로 나타났다. 클러스터의 전체적인 성능 향상은 이보다 더 적을 수 있다.
이처럼 데이터 전송 속도가 다소 느릴 수 있기 때문에 각 GPU의 입출력 데이터 량이 수행하는 연산의 수와 비교해 상대적으로 적을 때가 가장 이상적이다. 우선 작업의 종류가 GPU의 능력에 적합한 것이 중요하고 둘째는 해당 작업을 하둡을 통해 독립적인 병렬형 하위 프로세스로 분리할 수 있어야 한다.
대표적인 사례가 행렬 곱셈 등의 복잡한 수학적 공식 계산, 일련의 대단위 무작위 값 산출, 유사한 과학적 모델링 작업, 또는 기타 일반적인 용도의 GPU 애플리케이션 등이다.
사용할 툴
GPU와 연계된 하둡을 사용해 프로토타입을 구성하고 빅 데이터 시스템의 성능을 높이기 위해서는 GPU 접근을 허용하는 라이브러리(Library) 또는 바인딩(Binding)을 사용해야 한다. 현재, GPU의 연산능력을 활용하기 위해 사용할 수 있는 주요 툴은 다음과 같다.
-
JCUDA : JCUDA 프로젝트는 JCublas, JCusparse(행렬 작업을 위한 라이브러리, JCufft(일반적인 신호 처리를 위한 자바 바인딩), JCurand(GPU에서 무작위 숫자를 생성하기 위한 라이브러리) 등의 엔비디아 CUDA와 관련된 라이브러리를 위한 자바 바인딩을 제공한다. 하지만 이것은 오직 엔비디아의 GPU에만 해당한다.
-
자바 아파라피(Java Aparapi) : 아파라피는 자바의 바이트코드(Bytecode)를 실행할 때 OpenCL로 변환하고 이를 GPU에서 실행한다. 하둡을 이용한 연산을 위해 GPU를 사용하는 모든 시스템 중에서 아파라피와 OpenCL 방법이 가장 좋은 장기적인 측면을 갖고 있다. 아파라피는 AMD의 연구소인 AMD 자바랩스(JavaLabs)가 개발했다. 2011년에 오픈 소스로 공개된 이 프로젝트는 빠른 속도로 성장하고 있다. AMD 퓨전 개발자회의(Fusion Developer Summit) 컨퍼런스의 공식 웹 사이트에서 이 기술의 실제 활용사례를 볼 수 있다.
OpenCL은 개방형 크로스플랫폼 표준으로 많은 하드웨어 벤더들이 지원하고 있으며 CPU와 GPU용으로 동일한 코드 베이스를 작성할 수 있다. 어떤 머신에 GPU가 설치되어 있지 않은 경우 OpenCL은 자동으로 CPU에서 작업을 처리한다.
이 표준은 AMD, 인텔, 엔비디아, 알테라(Altera), 실링스(Xilinx) 등이 참여한 업계 컨소시엄인 크로노스 그룹(Khronos Group)이 개발하고 있다. 이 프레임워크로 작성한 코드는 AMD와 인텔의 CPU 뿐만 아니라 AMD와 엔비디아가 만든 GPU에서도 실행할 수 있다. OpenCL과 호환되는 새로운 솔루션이 매년 등장하고 있는 점이 매우 큰 장점이다.
- GPU에 접근할 수 있는 네이티브(Native) 앱 개발 : 복잡한 수학 연산용 네이티브 코드를 강력한 GPU에서 처리하는 것은 좋은 생각이다. 바인딩과 커넥터를 사용하는 솔루션보다 훨씬 빠른 성능을 구현할 수 있다. 그러나 가능한 짧은 시간 안에 솔루션을 제공해야 한다면 아파라피 같은 프레임워크를 선택하는 편이 낫다. 성능이 만족스럽지 못하다면 기존의 아파라피 코드를 부분 또는 전체적으로 네이티브 코드로 대체하는 방법도 있다. 물론 속도는 훨씬 빨라지지만 유연성은 그만큼 떨어지게 된다.
엔비디아 CUDA 또는 OpenCL을 사용한 C언어 API를 사용해 하둡이 (애플리케이션을 자바로 작성한 경우) JNA 또는 (애플리케이션을 C언어로 작성한 경우) 하둡 스트리밍(Hadoop Streaming)을 통해 GPU를 사용할 수 있도록 하는 네이티브 코드를 생성할 수도 있다.
GPU-하둡 프레임워크 한편 마스 프로젝트가 출범한 이후에 개발된 맞춤형 ‘GPU-하둡 프레임워크’도 성능 향상을 위해 사용할 수 있는 또다른 대안이다. 여기에는 그렉스(Grex), 판다(Panda), C-MR, GPMR, 슈레더(Shredder), 스팀MR(SteamMR) 등이 포함돼 있다.
그러나 이 중 대부분은 더 이상 지원하지 않으며 특정 과학 프로젝트 전용으로 개발된 것들이다. 즉 몬테 카를로 시뮬레이션을 다른 알고리즘 기반의 생물 정보과학 프로젝트에 적용하는 것이 사실상 불가능하다는 것이다.
프로세스 기술도 발전하고 있다. 소니의 플레이스테이션 4(PlayStation 4), 어댑테바(Adapteva)의 다중코어 다중 프로세서, ARM의 말리(Mali) GPU 등에서 혁신적인 새로운 아키텍처를 엿볼 수 있다. 어댑테바와 말리 GPU는 OpenCL과 호환될 예정이다.
인텔 또한 OpenCL과 호환되는 제온 파이(Xeon Phi) 코프로세서(Co-processor)를 출시했다. PCI 익스프레스 표준을 지원하는 x86과 유사한 아키텍처를 가진 60코어 코프로세서이다. 성능은 1TFLOPS이고 전력 소비는 300와트에 불과하다. 이 프로세서는 현존 최고 수퍼컴퓨터인 텐허-2(Tianhe-2)에 적용됐다.
고성능 분산형 컴퓨팅 부문에서 어떤 아키텍처가 주류를 이룰 것인지에 대해서는 여전히 딱 잘라 말하기 어렵다. 그 발전 정도에 따라 막대한 용량의 데이터가 처리되는 방식도 바뀌어 나갈 것이다.