Spark Architecture Shuffle
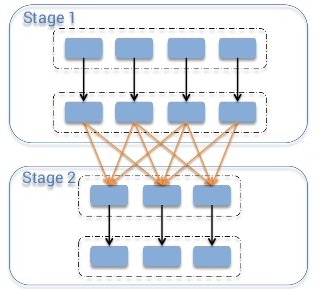
What is the shuffle in general? Imagine that you have a list of phone call detail records in a table and you want to calculate amount of calls happened each day. This way you would set the “day” as your key, and for each record (i.e. for each call) you would emit “1” as a value. After this you would sum up values for each key, which would be an answer to your question – total amount of records for each day. But when you store the data across the cluster, how can you sum up the values for the same key stored on different machines? The only way to do so is to make all the values for the same key be on the same machine, after this you would be able to sum them up.
There are many different tasks that require shuffling of the data across the cluster, for instance table join – to join two tables on the field “id”, you must be sure that all the data for the same values of “id” for both of the tables are stored in the same chunks. Imagine the tables with integer keys ranging from 1 to 1’000’000. By storing the data in same chunks I mean that for instance for both tables values of the key 1-100 are stored in a single partition/chunk, this way instead of going through the whole second table for each partition of the first one, we can join partition with partition directly, because we know that the key values 1-100 are stored only in these two partitions. To achieve this both tables should have the same number of partitions, this way their join would require much less computations. So now you can understand how important shuffling is.
Discussing this topic, I would follow the MapReduce naming convention. In the shuffle operation, the task that emits the data in the source executor is “mapper”, the task that consumes the data into the target executor is “reducer”, and what happens between them is “shuffle”.
Shuffling in general has 2 important compression parameters: spark.shuffle.compress – whether the engine would compress shuffle outputs or not, and spark.shuffle.spill.compress – whether to compress intermediate shuffle spill files or not. Both have the value “true” by default, and both would use spark.io.compression.codec codec for compressing the data, which is snappy by default.
As you might know, there are a number of shuffle implementations available in Spark. Which implementation would be used in your particular case is determined by the value of spark.shuffle.manager parameter. Three possible options are: hash, sort, tungsten-sort, and the “sort” option is default starting from Spark 1.2.0.