Article Source
- Title: Architecture
Peloton Architecture
Introduction
Peloton is an in-memory DBMS designed for real-time analytics. It can handle both fast ACID transaction and complex analytical queries on the same database.
This page describes the high level architecture of Peloton. As Peloton’s frontend is based on the Postgres DBMS, please pay attention to similar concepts and data structures in the two systems. For instance, we use both Postgres and our own Peloton query plan nodes in our system.
Life Cycle of a Query
A nice way to get familiar with Peloton’s architecture is to track down the life cycle of a query, and see how it gets executed. A high-level architecture diagram of Peloton is given below.
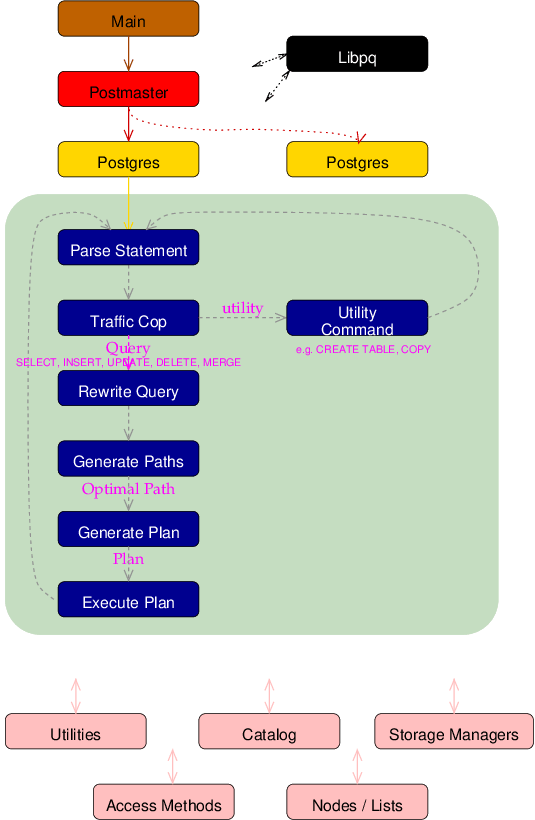
Peloton has a multi-threaded architecture. There is a postmaster module that takes care of the server startup/termination. When a connection request arrives, it starts off a backend (also referred to as postgres backend) thread, and hands off the connection to the backend.
Peloton can handle user’s queries given either through the psql interactive command-line interface, which has the same API as the one in Postgres, or given through a programming language middleware API, such as the Java-oriented JDBC. A client connection can be, for instance, a psql session or a JDBC session. After receiving the query, the backend thread parses it, performs query rewriting, and query planning. Finally, it emits a plan tree comprising of Postgres plan nodes.
PostgreSQL Query Processing
Here’s some more information on the stages a query has to pass in order to obtain a result (quoted verbatim from the Postgres manual):
-
A connection from an application program to the PostgreSQL server has to be established. The application program transmits a query to the server and waits to receive the results sent back by the server.
-
The
parserstage checks the query transmitted by the application program for correct syntax and creates aquery tree. -
The
rewritesystem takes thequery treecreated by the parser stage and looks for any rules (stored in the system catalogs) to apply to the query tree. It performs the transformations given in the rule bodies. One application of the rewrite system is in the realization of views. Whenever a query against a view (i.e., a virtual table) is made, the rewrite system rewrites the user’s query to a query that accesses the base tables given in the view definition instead. -
The
planner/optimizertakes the (rewritten) query tree and creates aquery planthat will be the input to the executor. It does so by first creating all possible paths leading to the same result. For example if there is an index on a relation to be scanned, there are two paths for the scan. One possibility is a simple sequential scan and the other possibility is to use the index. Next the cost for the execution of each path is estimated and the cheapest path is chosen. The cheapest path is expanded into a complete plan that the executor can use. -
The
executorrecursively steps through theplan treeand retrieves rows in the way represented by the plan. The executor makes use of the storage system while scanning relations, performs sorts and joins, evaluates qualifications and finally hands back therowsderived.
More information on the Postgres side of things can be found in the manual and in this awesome tour of PostgreSQL Internals by Tom Lane.
Peloton Query Processing
We intercept the generated plan trees generated by the Postgres planner and use our own executor module. Now, we will get into the specifics within our side of things.
Queries are classified into data description language (DDL) queries and data manipulation language (DML) queries.
These two categories of queries take two different processing paths both within the Postgres frontend and Peloton.
In Postgres, DML queries are executed in four stages. Take a look at the entry point of the Postgres executor module here.
ExecutorStart() performs some initialization that sets up the dynamic plan state tree from the static plan tree.
ExecutorRun() invokes the plan state tree.
ExecutorFinish() and ExecutorEnd() take care of cleaning things up, but they are not relevant to us. Peloton takes over query execution when queries reach ExecutorRun(), and we therefore only make use of ExecutorStart() in our system.
In case of DDL queries, Peloton intercepts them in the ProcessUtility function here.
Peloton cannot directly execute the Postgres plan state tree as our executors can only understand the Peloton query plan nodes. So, we need to transform the Postgres plan state tree into a Peloton plan tree before execution.
We refer to this process as plan mapping. After mapping the plan, Peloton executes the plan tree by recursively executing the plan tree nodes. We obtain Peloton tuples after query processing. We then transform them back into Postgres tuples before sending them back to the client via the Postgres frontend.
Plan Mapping
After taking over from Postgres, DDL queries are handled by peloton_ddl(), whereas DML queries would be processed by peloton_dml(). These functions are located here within the peloton module.
Plan mapping is done only for DML queries, since DDL queries do not require any planning. The high-level idea is to map each plan node in the Postgres plan state tree recursively into a corresponding plan node in the Peloton plan tree. The plan mapper module preprocesses the plan state tree, and extracts the critical information from each Postgres plan node. This preprocessing is performed by functions in the peloton::bridge::DMLUtils namespace. The main PlanTransformer would then transform the preprocessed plan by recursively invoking sub-transformers based on the type of node in the tree. An entry point for this module is peloton::bridge::PlanTransformer::TransformPlan().
Plan Execution
Peloton then builds an executor tree based on the Peloton query plan tree. It then runs the executor tree recursively.
Execution context is the state associated with an instance of the plan execution, such as parameters and transaction information. By separating the execution context from the query plan, we can support prepared statements. A planned and then mapped query plan can be reused with different execution contexts. This saves time spent for query planning and mapping.
After that, query execution consists of two stages. The execution tree has to be initialized (DInit()), and then it is executed (DExecute). An entry point for this module is here.
Code Base Entry Points
Here are some code base entry points:
Postgres backend main loop: PostgreMain(): src/postgres/backend/tcop/postgres.cpp;
Simple query execution: exec_simple_query(): src/postgres/backend/tcop/postgres.cpp;