Article Source
Inference: The Next Step in GPU-Accelerated Deep Learning
Deep learning is revolutionizing many areas of machine perception, with the potential to impact the everyday experience of people everywhere. On a high level, working with deep neural networks is a two-stage process: First, a neural network is trained: its parameters are determined using labeled examples of inputs and desired output. Then, the network is deployed to run inference, using its previously trained parameters to classify, recognize and process unknown inputs.
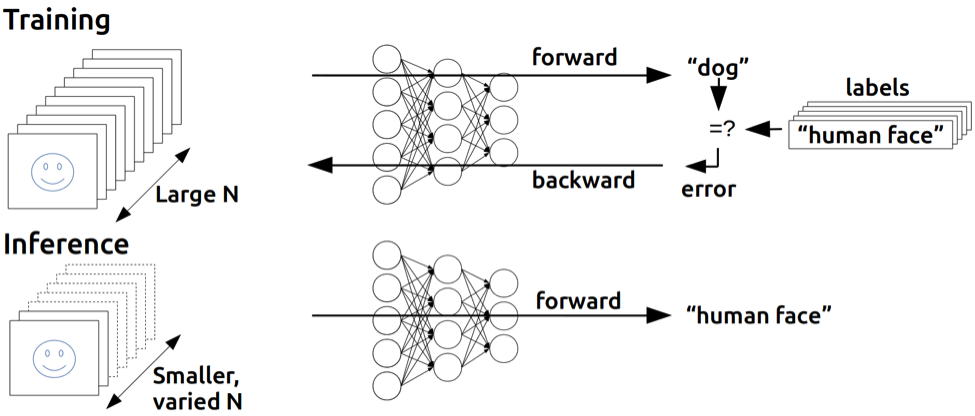 Figure 1: Deep learning training compared to inference. In training,
many inputs, often in large batches, are used to train a deep neural
network. In inference, the trained network is used to discover
information within new inputs that are fed through the network in
smaller batches.
Figure 1: Deep learning training compared to inference. In training,
many inputs, often in large batches, are used to train a deep neural
network. In inference, the trained network is used to discover
information within new inputs that are fed through the network in
smaller batches.
It is widely recognized within academia and industry that GPUs are the state of the art in training deep neural networks, due to both speed and energy efficiency advantages compared to more traditional CPU-based platforms. A new whitepaper from NVIDIA takes the next step and investigates GPU performance and energy efficiency for deep learning inference.
The results show that GPUs provide state-of-the-art inference performance and energy efficiency, making them the platform of choice for anyone wanting to deploy a trained neural network in the field. In particular, the NVIDIA GeForce GTX Titan X delivers between 5.3 and 6.7 times higher performance than the 16-core Intel Xeon E5 CPU while achieving 3.6 to 4.4 times higher energy efficiency. The NVIDIA Tegra X1 SoC also achieves impressive results, achieving higher performance (258 vs. 242 images/second) and much higher energy efficiency (45 vs. 3.9 images/second/Watt) than the state-of-the-art Intel Core i7 6700K.
Inference versus Training
Both DNN training and Inference start out with the same forward propagation calculation, but training goes further. As Figure 1 illustrates, after forward propagation, the results from the forward propagation are compared against the (known) correct answer to compute an error value. A backward propagation phase propagates the error back through the network’s layers and updates their weights using gradient descent in order to improve the network’s performance at the task it is trying to learn. It is common to batch hundreds of training inputs (for example, images in an image classification network or spectrograms for speech recognition) and operate on them simultaneously during DNN training in order to prevent overfitting and, more importantly, amortize loading weights from GPU memory across many inputs, increasing computational efficiency.
For inference, the performance goals are different. To minimize the network’s end-to-end response time, inference typically batches a smaller number of inputs than training, as services relying on inference to work (for example, a cloud-based image-processing pipeline) are required to be as responsive as possible so users do not have to wait several seconds while the system is accumulating images for a large batch. In general, we might say that the per-image workload for training is higher than for inference, and while high throughput is the only thing that counts during training, latency becomes important for inference as well.
GPUs rock at neural network inference!
To cover a range of possible inference scenarios, the NVIDIA inference whitepaper looks at two classical neural network architectures: AlexNet (2012 ImageNet ILSVRC winner), and the more recent GoogLeNet (2014 ImageNet winner), a much deeper and more complicated neural network compared to AlexNet. The paper looks at two cases for each network. The first case allows batching many input images together, to model use cases like inference in the cloud where thousands of users submit images every second. Here, large batches are acceptable, as waiting for a batch to assemble does not add significant latency. The experiments use a large batch size of 48 for CPUs (Maximum supported by IDLF) and 128 for GPUs. The second case considers extremely latency-focused cases with no batching (batch size 1).
The experiments were run on four different devices: The NVIDIA Tegra X1 and the Intel Core i7 6700K as client-side processors; and the NVIDIA GeForce GTX Titan X and a 16-core Intel Xeon E5 2698 as high-end processors. The neural networks were run on the GPUs using Caffe compiled for GPU usage using cuDNN. The Intel CPUs run the most optimized CPU inference code available, the recently released Intel Deep Learning Framework (IDLF) [17]. IDLF only supports a neural network architecture called CaffeNet that is similar to AlexNet with batch sizes of 1 and 48.
On Tegra X1, results for inference in both 16-bit and 32-bit floating point precision are given, because Tegra X1’s higher FP16 arithmetic throughput and the FP16 arithmetic support in a preview version of cuDNN 4 allow for significantly higher performance without incurring any losses in classification accuracy.Figure 2 shows the results (Please see the white paper for full details of the experimental setup).
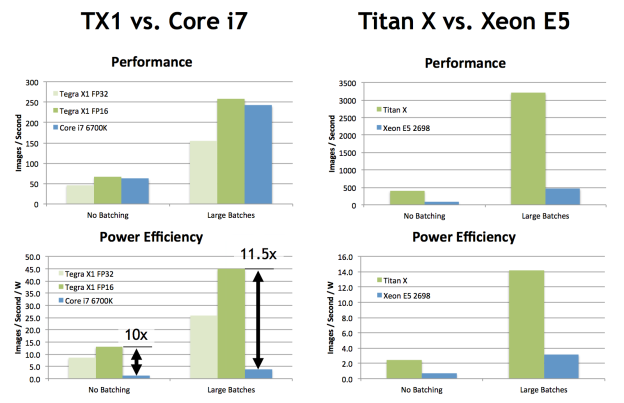
Figure 2: Deep Learning Inference results for AlexNet on NVIDIA Tegra X1
and Titan X GPUs, and Intel Core i7 and Xeon E5 CPUs.
The results show that deep learning inference on Tegra X1 with FP16 is an order of magnitude more energy-efficient than CPU-based inference, with 45 img/sec/W on Tegra X1 in FP16 compared to 3.9 img/sec/W on Core i7 6700K, while achieving similar absolute performance levels (258 img/sec on Tegra X1 in FP16 compared to 242 img/sec on Core i7). The comparison between Titan X and Xeon E5 reinforces the same conclusion as the comparison between Tegra X1 and Core i7: GPUs appear to be capable of significantly higher energy efficiency for deep learning inference in the case of AlexNet. In the case of Titan X, however, the GPU not only provides much better energy efficiency than the CPU, but it also achieves substantially higher performance at over 3000 images/second in the large-batch case compared to less than 500 images/second on the CPU.
While larger batch sizes are more efficient to process, the comparison between Titan X and Xeon E5 with no batching proves that the GPU’s efficiency advantage is present even for smaller batch sizes. In comparison with Tegra X1, the Titan X manages to achieve competitive Performance/Watt despite its much bigger GPU, as the large 12 GB framebuffer allows it to run more efficient but memory-capacity-intensive FFT-based convolutions.
New Batched Inference Optimizations
Also included in the whitepaper is a discussion of new cuDNN optimizations aimed at improving inference performance (and used in the performance results shown in the paper), as well as optimizations added to the Caffe deep learning framework. Among the many optimizations in cuDNN 4 is an improved convolution algorithm that is able to split the work of smaller batches across more multiprocessors, improving the performance of small batches on larger GPUs. cuDNN 4 also adds support for FP16 arithmetic in convolution algorithms. On supported chips, such as Tegra X1 or the upcoming Pascal architecture, FP16 arithmetic delivers up to 2x the performance of equivalent FP32 arithmetic. Just like FP16 storage, using FP16 arithmetic incurs no accuracy loss compared to running neural network inference in FP32.
GPUs also benefit from an improvement contributed to the Caffe framework to allow it to use cuBLAS GEMV (matrix-vector multiplication) instead of GEMM (matrix-matrix multiplication) for inference when the batch size is
- See the whitepaper for more details on these optimizations.
Learn More about Deep Learning with GPUs
The industry-leading performance and power efficiency of NVIDIA GPUs make them the platform of choice for deep learning training and inference. Be sure to read the white paper “GPU-Based Deep Learning Inference: A Performance and Power Analysis” for full details.
You may also be interested in Dustin Franklin’s post about the new Jetson TX1 Embedded Developer Kit.
If you are new to the field of deep learning or would like to learn more about using GPUs to accelerate deep neural networks, be sure to register for NVIDIA’s new Deep Learning Courses. You can also read our previous blog posts on DIGITS and cuDNN. DIGITS is an easy-to-use, interactive, deep-learning training system that makes it easy to develop and train deep neural networks on GPUs. DIGITS can be easily deployed on a workstation or a cloud platform such as IBM Cloud’s SoftLayer infrastructure.