Article Source
- Title: Three things you need to know about machine learning
- Authors: Medha Agarwal
Three things you need to know about machine learning

Machine learning is all the rage, and major improvements in infrastructure, data storage, and cloud adoption have led to growing interest in the space. Many consumer-facing advancements reside within Google and Facebook, but other companies are investing in the field as well. However, given all the excitement around machine learning, it’s important to understand some of the nuances and mechanics of what machine learning is and how it works. As an investor at Redpoint Ventures, I have the privilege of learning from people and companies on the cutting edge of this technology.
So, what is machine learning and artificial intelligence? Artificial intelligence (AI) is software that does what humans do but faster and hopefully better. For example, transcribing notes from a meeting and highlighting all follow up tasks. Machine learning is one approach to achieve AI by using algorithms, instead of the traditional hand-coded rules-based decision trees. At a high level, there are three steps in machine learning: sensing, reasoning, and producing.
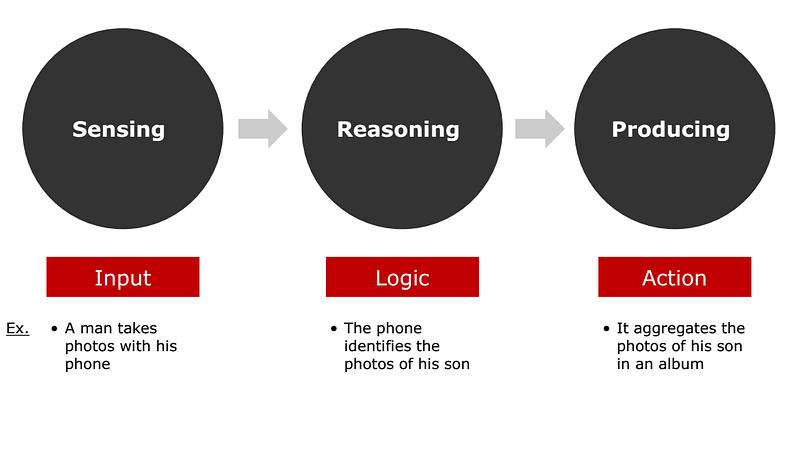
Machine learning has increased in popularity and become more feasible in the last five years.
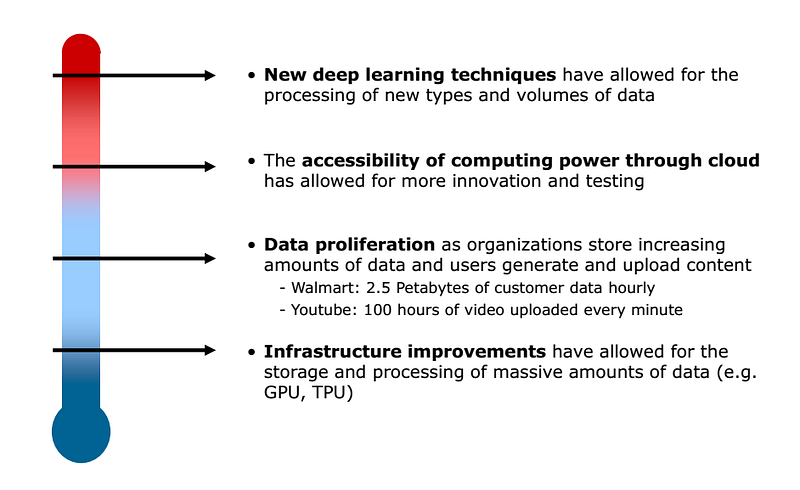
There have been several advancements in the field of machine learning that have driven improvements in techniques, applications, and the overall accessibility of the technique such as the rise of cloud computing and the proliferation of data.
There are four major factors that have led to the current proliferation of companies that are leveraging machine learning in their products.
The machine learning landscape and its potential for impact on products and services in the future can be viewed in three specific ways:
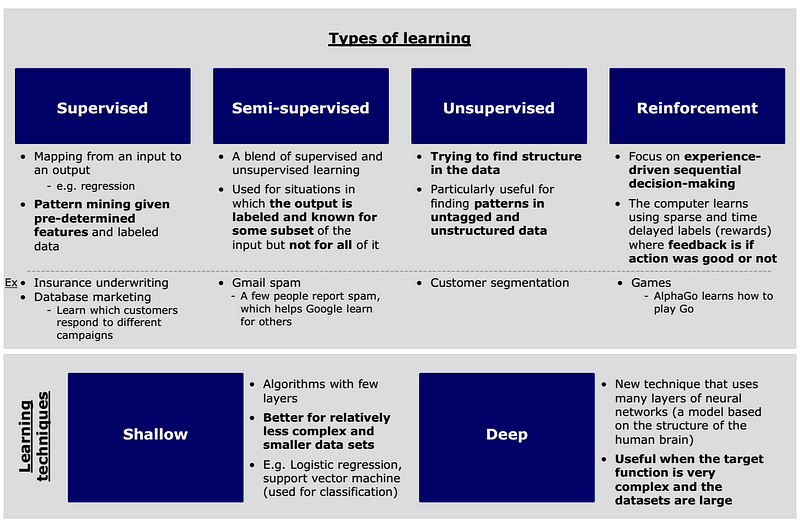
Takeway #1: Machine learning is not monolithic
Within machine learning, there are different types of learning (e.g., supervised, unsupervised) and various techniques (e.g., regression, neural nets). These techniques and types of learning do not exclusively map to each other but are used in different combinations depending on the situation. Below I’ve shared how I visually mapped this out for myself.
Types of learning:
- Supervised: Supervised learning identifies patterns in data given pre-determined features and labeled data (e.g., traditional insurance underwriting)
- Unsupervised: Unsupervised learning identifies patterns in data, which is particularly helpful for unlabeled and unstructured data (e.g., Gmail spam)
- Semi-supervised: A blend of supervised and unsupervised learning. Best in situations where there is some labeled data but not a lot (e.g., customer segmentation)
- Reinforcement: Reinforcement learning provides feedback to the algorithm as it trains; it is essentially experience-driven decision making (e.g., playing chess)
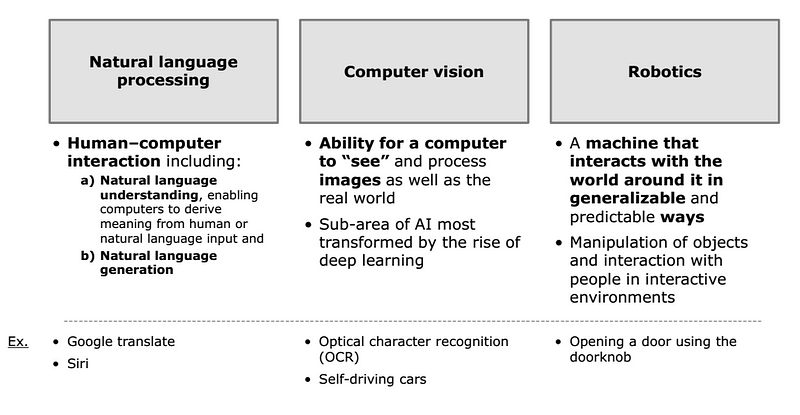
Takeaway #2: Deep learning has emerged as a technique with strong advantages, but also has important drawbacks as well
Deep learning involves many layers of neural nets, algorithms modeled on the structure of the human brain, making the network “deep.” We often hear about the benefits of deep learning for unsupervised and reinforcement learning, which has in fact led to major advancements in both fields, although it is not always required. Deep learning may also be valuable in supervised learning with large, complex problems.
Deep learning has three key advantages relative to other techniques. It is robust, generalizable, and scalable. It is robust because the features, the characteristics used to differentiate or classify the data, do not need to be predetermined; the optimal features are learned for a given task. It is generalizable because the same neural net approach can be used for different applications and data types. And it is scalable because the method is 1) parallelizable, i.e., able to be run across multiple processors and 2) performance improves with more data, reducing the likelihood of that you will train the algorithm in a way that is accurate for only the specific training data (i.e., overfitting).
This has important consequences for three fields in particular: natural language processing, computer vision, and robotics.
At the same time, there are drawbacks to keep in mind when using deep learning. One big one is that when a neural net determines certain features are important and makes decisions based on them, we do not know why. This means that if there is corrupted data or human bias in the system, we will not be able to pinpoint that it exists, which can be dangerous for specific use cases, such as various areas of finance and law enforcement, that could impact society.
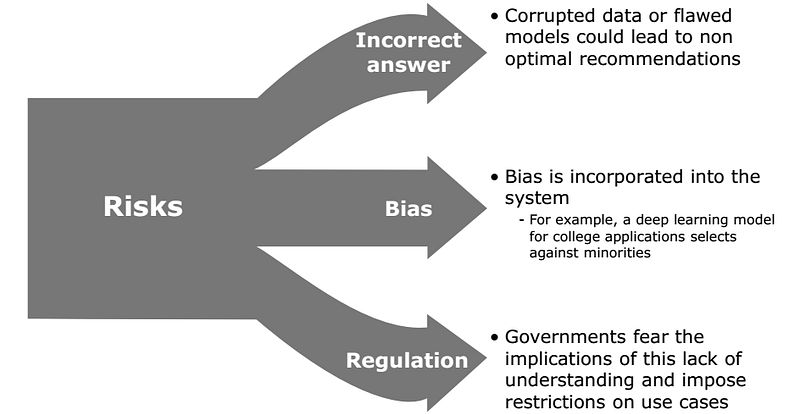
In addition, deep learning models require an extremely large amount of data and compute power to be effective, which is costly and time intensive. This is an important tradeoff to keep in mind, especially for young startups who are building their products on a budget.
Therefore, deep learning is not always the best approach, but rather, for each specific use case, data scientists need to take the potential for bias, availability of computing resources, and access to data into account.
Takeaway #3: Machine learning will have major implications for what products will look like going forward
Machine learning is not a solution in and of itself, but a tool to optimize the desired outcome. Therefore companies leveraging machine learning should focus on providing insights that are actionable, and move from helping customers manipulate data for analysis to focusing on strategy and recommendations to make decision making more efficient and accurate. It’s likely that user interfaces will simplify to focus on recommending an action instead of providing a myriad of options to pick from. Below are two examples that illustrate early versions of this shift.
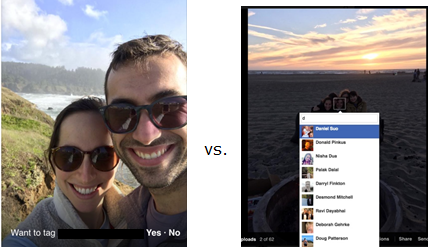
Facebook’s photo tagging engine has moved to recommended tagging (left), making it smarter and simpler to use than its previous version (right).
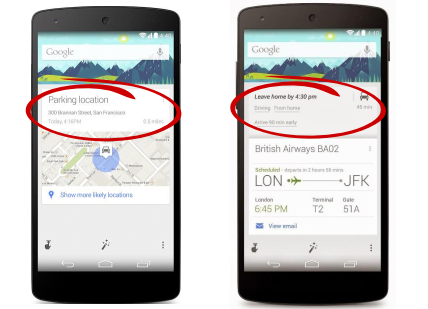
Similarly, Google Now remembers where a user parks (left) and recommends when to leave for the airport (right) based on flight times, current location, and traffic information. This recommendation-driven, simplified user experience will be the future of product user interfaces.
These examples illustrate the massive impact that machine learning will have as it continues to enable products that are more effective and simpler to use.
For further musings on machine learning and its implications for products and start-ups, follow me on Twitter at @mkhandel and on Medium at @medhaa