Article Source
Generative Adversarial Networks
페이스북 인공지능 연구팀의 리더이자 딥러닝의 아버지라 불리는 얀 르쿤(Yann LeCun) 교수는 GAN(Generative Adversarial Network)을 가리켜 최근 10년간 머신러닝 분야에서 가장 혁신적인 아이디어라고 말했다. 요즘 가장 주목받는 기술인 딥러닝 중에서도 GAN은 가장 많은 관심을 받고 있는 기술이다. 그만큼 GAN은 새로운 연구가 활발히 이루어지고 혁신이 빠르게 일어나고 있는 기술이기도 하다. GAN을 활용해 이전에 없었던 서비스나 제품이 출시되고 우리 삶에 깊숙이 자리 잡을 날도 얼마 남지 않은 듯이 보인다. 이 글에서 GAN이란 무엇인지 소개하고 간단한 튜토리얼을 통해 작동 원리를 이해해보자. 또한, GAN에 어떤 종류가 있는지 살펴보고 그 가능성과 한계에 대해서 알아보자.
GAN이란?
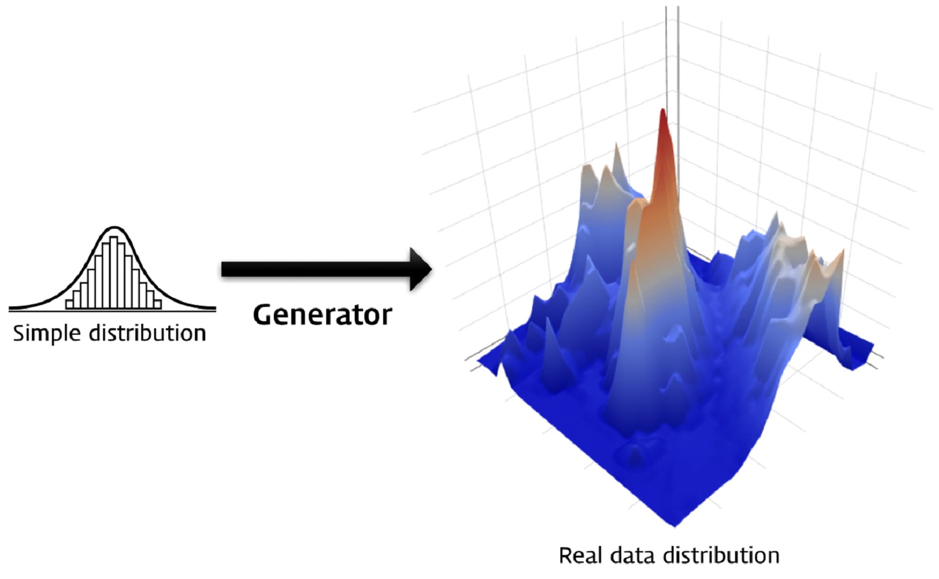
GAN은 ‘Generative Adversarial Network‘의 약자다. 이 세 글자의 뜻을 풀어보는 것만으로도 GAN에 대한 전반적으로 이해할 수 있다. 첫 단어인 ‘Generative’는 GAN이 생성(Generation) 모델이라는 것을 뜻한다. 생성 모델이란 ‘그럴듯한 가짜‘를 만들어내는 모델이다. 언뜻 보면 진짜 같은 가짜 사람 얼굴 사진을 만들어내거나 실제로 있을 법한 고양이 사진을 만들어내는 것이 생성 모델의 예다.

‘그럴듯하다’라는 것을 어떻게 정의할 수 있을까? 수학적으로는 실제 데이터의 분포와 비슷한 분포에서 나온 데이터를 실제와 비슷하다고 말할 수 있다. 예를 들어, 어떤 사람이 키는 172cm이고 몸무게는 68kg이라고 하면 그럴듯하지만, 키는 190cm이고 몸무게는 40kg이라고 하면 현실적으로 그럴듯하지 않을 것이다. 190cm와 40kg이라는 키와 몸무게의 조합은 실제 데이터 분포에서는 거의 나오지 않는 조합이기 때문이다. 그럴듯한 키와 몸무게 조합을 만들어 내려면 실제 키와 몸무게의 분포를 최대한 비슷하게 따라야 한다. 이처럼 수학적으로 생성 모델의 목적은 실제 데이터 분포와 근사한 것이라고 말할 수 있다.
키와 몸무게의 생성 모델을 만드는 것은 비교적 쉬운 문제다. 사람 얼굴이나 고양이 사진의 생성 모델을 만드는 것은 더 어려운 문제다. 이미지는 변수의 수가 훨씬 더 많기 때문이다. 이미지의 크기가 256 x 256 픽셀이라면 RGB 컬러값까지 총 256 x 256 x 3개의 변수가 생긴다. 그 변수들의 어떤 조합은 사람 얼굴처럼 보이지만, 어떤 조합은 그렇지 않다. 얼굴 이미지의 생성 모델을 만들겠다는 것은 사람 얼굴처럼 보이는 픽셀값 조합의 분포를 찾아내겠다는 것이다. 물론 이는 키와 몸무게 두가지 변수의 조합보다 어려운 문제다. 하지만 딥러닝의 발전으로 이런 생성 문제들이 점점 더 도전해 볼만한 주제들이 되고 있다.
GAN의 두번째 단어인 ‘Adversarial’은 GAN이 두 개의 모델을 적대적(Adversarial)으로 경쟁시키며 발전시킨다는 것을 뜻한다. 위조지폐범과 경찰을 생각해보자. 이 둘은 적대적인 경쟁 관계다. 위조지폐범은 경찰을 속이기 위해 점점 지폐 위조 제조 기술을 발전시키고, 경찰은 위조지폐범을 잡기 위해 점점 위폐를 찾는 기술을 발전시킨다. 시간이 흐르면 위조지폐범의 위폐 제조 기술은 완벽에 가깝게 발전할 것이다.
이처럼 GAN은 위조지폐범에 해당하는 생성자(Generator)와 경찰에 해당하는 구분자(Discriminator)를 경쟁적으로 학습시킨다. 생성자의 목적은 그럴듯한 가짜 데이터를 만들어서 구분자를 속이는 것이며, 구분자의 목적은 생성자가 만든 가짜 데이터와 진짜 데이터를 구분하는 것이다. 이 둘을 함께 학습시키면서 진짜와 구분할 수 없는 가짜를 만들어내는 생성자를 얻을 수 있다. 이것이 GAN의 핵심적인 아이디어인 적대적 학습(Adversarial Training)이다.
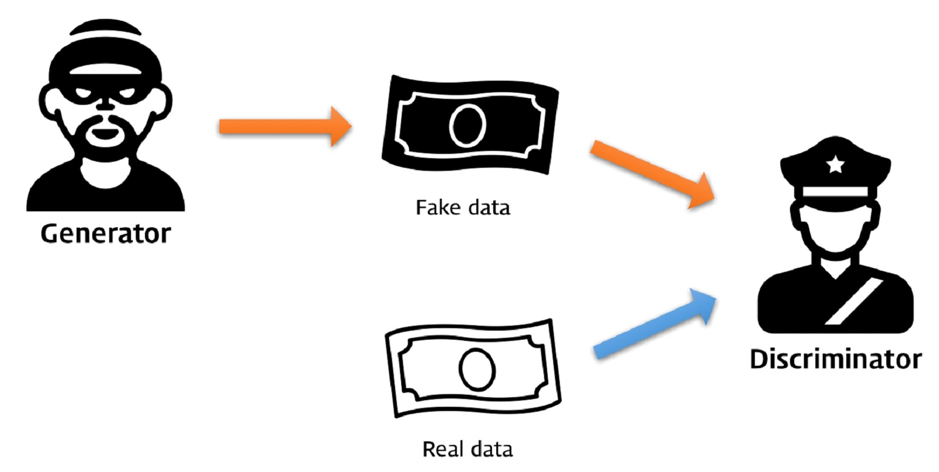
GAN의 마지막 단어 ‘네트워크(Network)’는 이 모델이 인공신경망(Artificial Neural Network) 또는 딥러닝(Deep Learning)으로 만들어졌기 때문에 붙었다. 이 글에서는 ‘인공신경망’과 ‘딥러닝’을 구분 없이 사용하겠다. 사실 적대적 학습이라는 개념을 구현하기 위해 반드시 딥러닝을 써야 하는 것은 아니다. 하지만 알파고 등 여러 사례에서 볼 수 있듯이 딥러닝은 강력한 머신러닝 모델을 가능하게 만드는 기술이다. 딥러닝이 이런 힘을 갖게 된 비결을 비선형 활성 함수(non-Linear Activation Function)와 계층(Hierarchy) 구조, 그리고 역전파(Backpropagation)의 원리를 통해 간단하게 알아보자.
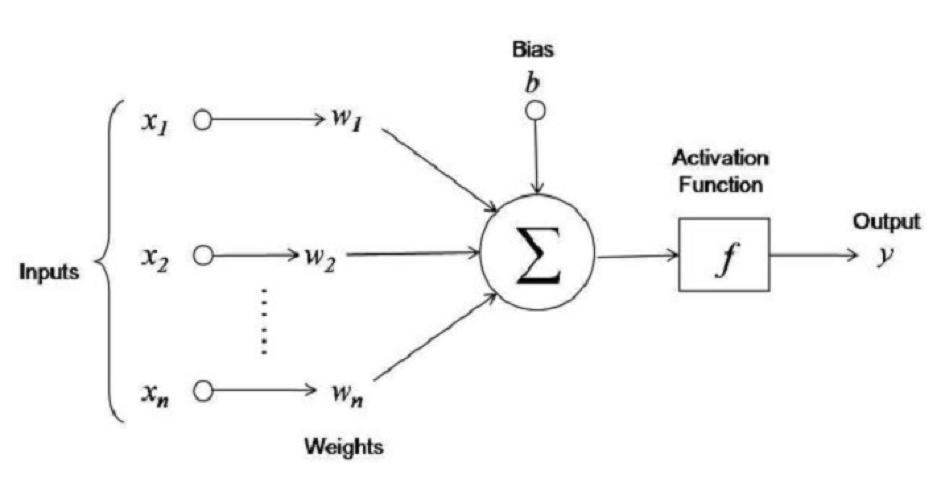
널리 알려져 있다시피 인공신경망 알고리즘은 인간 뇌 속 뉴런의 행동 방식에 영감을 받아 만들어졌다. 이전 층(Layer)의 뉴런의 출력값에 가중치(Weights)나 매개 변수(Parameters)를 곱해 합한 것이 다음 층 뉴런의 입력값이 된다. 이 입력값에 활성 함수(Activation Function)라 불리는 비선형 함수를 적용시키면 선형 함수로 표현할 수 없는 복잡한 관계를 표현할 수 있게 된다. 딥러닝의 강력함은 이런 층들이 매우 깊게 쌓을 수 있다는 점에서 나온다. 층을 많이 쌓을수록 더욱 복잡한 함수를 표현할 수 있는 힘(Representation Power)을 얻게 된다.
딥러닝을 학습시킨다는 것은 최적의 가중치를 찾아간다는 것을 의미한다. 가중치는 처음에 랜덤으로 초기화되지만, 모델의 손실 함수(Loss Function)을 최소화시키는 방향으로 조금씩 업데이트된다. 이때 손실 함수 값이 역전파를 통해 각 층의 가중치에 전달되며 업데이트 방향과 크기를 결정한다. 이런 방식으로 가중치를 최적화하는 방식을 경사하강법(Gradient Descent)이라고 부른다.
딥러닝은 이론적으로 어떤 함수도 근사할 수 있는 함수(Global Function Approximator)라는 것이 알려져 있다. 이것이 딥러닝이 개와 고양이 사진을 분류하는 문제에서부터 영어를 한국어로 번역하고, 이세돌 9단을 이기는 바둑 알고리즘을 만드는 데까지 널리 쓰이는 이유다. GAN은 실제 데이터 분포를 근사하는 함수를 만들기 위해 이러한 딥러닝 구조를 활용한다.
요약하자면 GAN은 생성이라는 문제를 풀기 위해 딥러닝으로 만들어진 모델을 적대적 학습이라는 독특한 방식으로 학습시키는 알고리즘이다. 이처럼 ‘Generative Adversarial Network’라는 이름 속에는 모델의 목적부터 학습 방법까지 GAN의 전반적인 개념이 모두 들어있다.
GAN 직접 만들어보기
이제 앞서 설명한 개념들이 코드를 통해 어떻게 구현되는지 살펴보자. 구현에는 딥러닝 프레임워크인 파이토치(PyTorch)를 이용한다. 파이토치는 페이스북이 주도해서 개발하는 딥러닝 프레임워크로 파이썬스럽게(Pythonic) 설계됐기 때문에 다른 프레임워크에 비해 비교적 코드가 간결하고, 디버깅이 쉬워서 연구용으로 인기가 높다. 물론 각 프레임워크마다 장단점이 있지만 여기에서는 직관적인 설명과 이해를 위해 파이토치로 GAN을 구현해보자.
GAN으로 풀어볼 문제는 0부터 9까지 숫자 모양의 손글씨 이미지를 생성하는 문제다. MNIST(Mixed National Institute of Standards and Technology)라 불리는 숫자 손글씨 데이터셋은 딥러닝 계의 ‘Hello World’라고 불릴 정도로 널리 쓰이는 데이터셋이다. 비교적 간단한 문제지만 여기에서 쓰인 GAN의 원리는 어떤 문제에도 동일하게 적용되기 때문에 유용한 예제가 될 것이다. 파이토치에서는 MNIST 데이터셋을 쉽게 불러와 사용할 수 있는 방법을 제공한다.
전체 코드는 github.com/dreamgonfly/GAN-tutorial 에서 볼 수 있다.
# <코드1> 라이브러리 및 데이터 불러오기
import torch
import torch.nn as nn
from torch.optim import Adam
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torch.autograd import Variable
#데이터 전처리 방식을 지정한다.
transform = transforms.Compose([
transforms.ToTensor(), # 데이터를 파이토치의 Tensor 형식으로바꾼다.
transforms.Normalize(mean=(0.5,), std=(0.5,)) # 픽셀값 0 ~ 1 -> -1 ~ 1
])
#MNIST 데이터셋을 불러온다. 지정한 폴더에 없을 경우 자동으로 다운로드한다.
mnist =datasets.MNIST(root='data', download=True, transform=transform)
#데이터를 한번에 batch_size만큼만 가져오는 dataloader를 만든다.
dataloader =DataLoader(mnist, batch_size=60, shuffle=True)
GAN의 2가지 요소인 생성자와 구분자 중 생성자(Generator)를 먼저 만들어보자. 생성자는 랜덤 벡터 ‘z’를 입력으로 받아 가짜 이미지를 출력하는 함수다. 여기서 ‘z’는 단순하게 균등 분포(Uniform Distribution)나 정규 분포(Normal Distribution)에서 무작위로 추출된 값이다. 생성자는 이렇게 단순한 분포를 사람 얼굴 이미지와 같은 복잡한 분포로 매핑(Mapping)하는 함수라고 볼 수 있다. 생성자 모델에 충분한 수의 매개 변수가 있다면 어떤 복잡한 분포도 근사할 수 있다는 것이 알려져 있다.
‘z’ 벡터가 존재하는 공간을 잠재 공간(Latent Space)이라고도 부른다. 여기서는 잠재 공간의 크기를 임의로 100차원으로 뒀다. 잠재 공간의 크기에는 제한이 없으나 나타내려고 하는 대상의 정보를 충분히 담을 수 있을 만큼은 커야 한다. GAN은 우리가 이해할 수는 없는 방식이지만 ‘z’ 벡터의 값을 이미지의 속성에 매핑시키기 때문이다. 뒤에 살펴볼 GAN의 파생 모델에서 잠재 공간의 의미를 더욱 자세히 이해할 수 있을 것이다.
생성자에 충분한 수의 매개 변수를 확보하기 위해, 이 구현에서는 4개의 선형 레이어(Linear Layer, Fully Connected Layer, Linear Transformation)를 쌓아서 생성자를 만들었다. 선형 레이어는 속해있는 모든 뉴런이 이전 레이어의 모든 뉴런과 연결되는 가장 단순한 구조의 레이어다. 이 모델에서는 100차원의 랜덤 벡터를 받아 이를 256개의 뉴런을 가진 레이어로 보내고, 다시 레이어의 크기를 512, 1024로 점점 증가시켰다. 마지막에는 출력을 MNIST 이미지의 크기로 맞추기 위해 레이어 크기를 28x28로 줄였다.
각 레이어마다 활성 함수로는 LeakyReLU를 이용했다. LeakyReLU는 각 뉴런의 출력값이 0보다 높으면 그대로 놔두고, 0보다 낮으면 정해진 작은 숫자를 곱하는 간단한 함수다. 여기서는 0.2를 곱했다. 이밖에도 활성 함수로는 ReLU, Elu, Tanh, Sigmoid 등이 자주 쓰인다. 생성자의 마지막 레이어에서는 출력값을 픽셀값의 범위인 -1과 1 사이로 만들어주기 위해 Tanh를 사용했다.
이렇게 여러 개의 레이어와 활성 함수를 쌓은 덕분에 MNIST의 데이터 분포를 근사할 수 있는 충분한 표현력(Representation Power)을 얻을 수 있었다. MNIST는 비교적 간단한 문제에 속하므로 더욱 복잡한 문제를 풀기 위해서는 더 깊은 레이어 구조와 더 많은 양의 매개 변수가 필요할 것이다.
# <코드2> GAN의 생성자(Generator)
# 생성자는 랜덤 벡터 z를 입력으로 받아 가짜 이미지를 출력한다.
class Generator(nn.Module):
# 네트워크 구조
def __init__(self):
super(Generator, self).__init__()
self.main = nn.Sequential(
nn.Linear(in_features=100, out_features=256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(in_features=256, out_features=512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(in_features=512, out_features=1024),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(in_features=1024, out_features=28*28),
nn.Tanh())
# (batch_size x 100) 크기의 랜덤 벡터를 받아
# 이미지를 (batch_size x 1 x 28 x 28) 크기로 출력한다.
def forward(self, inputs):
return self.main(inputs).view(-1, 1, 28, 28)
구분자는 이미지를 입력으로 받고 그 이미지가 진짜일 확률을 0과 1 사이의 숫자 하나로 출력하는 함수다. 구분자의 구현은 생성자와 마찬가지로 4개의 선형 레이어를 쌓았으며 레이어마다 활성 함수로 LeakyReLU를 넣어줬다. 입력값으로 이미지 크기인 28x28개의 변수를 받은 뒤 레이어의 크기가 28x28에서 1024로, 512로, 256으로 점차 줄어들다. 마지막에는 확률값을 나타내는 숫자 하나를 출력한다.
레이어마다 들어간 드롭아웃(Dropout)은 학습 시에 무작위로 절반의 뉴런을 사용하지 않도록 한다. 이를 통해 모델이 과적합(Overfitting, 오버피팅)되는 것을 방지할 수 있고, 또한 구분자가 생성자보다 지나치게 빨리 학습되는 것도 막을 수 있다. 구분자의 마지막 레이어에서는 출력값을 0과 1 사이로 만들기 위해 활성 함수로 Sigmoid를 넣었다.
# <코드3> GAN의 구분자(Discriminator)
# 구분자는 이미지를 입력으로 받아 이미지가 진짜인지 가짜인지 출력한다.
class Discriminator(nn.Module):
# 네트워크 구조
def __init__(self):
super(Discriminator, self).__init__()
self.main = nn.Sequential(
nn.Linear(in_features=28*28, out_features=1024),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(inplace=True),
nn.Linear(in_features=1024, out_features=512),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(inplace=True),
nn.Linear(in_features=512, out_features=256),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(inplace=True),
nn.Linear(in_features=256, out_features=1),
nn.Sigmoid())
# (batch_size x 1 x 28 x 28) 크기의 이미지를 받아
# 이미지가 진짜일 확률을 0~1 사이로 출력한다.
def forward(self, inputs):
inputs = inputs.view(-1, 28*28)
return self.main(inputs)
# <코드4> 생성자와 구분자 객체 만들기
G = Generator()
D = Discriminator()
이제부터는 이렇게 만들어진 네트워크 구조를 학습하는 방법에 대해 알아보자. 학습하기 위해서는 모델을 평가할 수 있어야 한다. 모델의 평가 지표가 좋아지는 방향으로 매개 변수를 업데이트할 것이기 때문이다. 구분자의 출력값은 이미지가 진짜일 확률이고, 이 확률이 얼마나 정답과 가까운지를 측정하기 위해 바이너리 크로스 엔트로피(Binary cross entropy) 손실 함수(loss function)를 사용한다. 이 함수는 구분자가 출력한 확률값이 정답에 가까우면 낮아지고 정답에서 멀면 높아진다. 이 손실 함수의 값을 낮추는 것이 모델 학습의 목표가 된다.
이제 생성자와 구분자의 매개 변수를 업데이트하는 최적화 함수가 각각 하나씩 필요하다. 최적화 기법에는 여러 종류가 있지만 여기서는 가장 널리 쓰이는 기법인 아담(Adam)을 사용했다. 아담은 매개 변수마다 업데이트 속도를 최적으로 조절하는 효율적인 최적화 기법이다.
# <코드5> 손실 함수와 최적화 기법 지정하기
# Binary Cross Entropy loss
criterion = nn.BCELoss()
# 생성자의 매개 변수를 최적화하는 Adam optimizer
G_optimizer = Adam(G.parameters(), lr=0.0002, betas=(0.5, 0.999))
# 구분자의 매개 변수를 최적화하는 Adam optimizer
D_optimizer = Adam(D.parameters(), lr=0.0002, betas=(0.5, 0.999))
모델 학습을 위해서 전체 데이터셋을 여러 번 돌며 매개 변수를 조금씩 업데이트한다. 데이터셋을 한 번 도는 것을 1 에폭(Epoch)이라고 부르는데, 여기서는 100 에폭 동안 학습할 것이다. 각 에폭마다 배치 사이즈(Batch Size)인 60개만큼 데이터를 가져와서 모델을 학습시킨다. MNIST 학습 데이터의 개수가 6만개이니 1에폭마다 1000번씩 학습이 이루어지는 셈이다.
# <코드6> 모델 학습을 위한 반복문
# 데이터셋을 100번 돌며 학습한다.
for epoch in range(100):
# 한번에 batch_size만큼 데이터를 가져온다.
for real_data, _ in dataloader:
batch_size = real_data.size(0)
# 데이터를 파이토치의 변수로 변환한다.
real_data = Variable(real_data)
# ...(중략)
먼저 구분자를 학습시켜보자. 구분자는 진짜 이미지를 입력하면 1에 가까운 확률값을 출력하고, 가짜 데이터를 입력하면 0에 가까운 확률값을 출력해야 한다. 따라서 구분자의 손실 함수는 두 가지의 합으로 이루어진다. 진짜 이미지를 입력했을 때의 출력값과 1과의 차이, 그리고 가짜 이미지를 입력했을 때의 출력값과 0과의 차이, 두 경우의 합이 구분자의 손실 함수다. 이 손실 함수의 값을 최소화하는 방향으로 구분자의 매개 변수가 업데이트된다.
파이토치에서는 간단한 방법으로 역전파를 통해 계산된 각 변수의 미분 값을 구할 수 있다. 그 상태에서 최적화 함수를 실행시키면 매개 변수가 한번 업데이트된다.
# <코드7> 구분자 학습시키기
# 이미지가 진짜일 때 정답 값은 1이고 가짜일 때는 0이다.
# 정답지에 해당하는 변수를 만든다.
target_real = Variable(torch.ones(batch_size, 1))
target_fake = Variable(torch.zeros(batch_size, 1))
# 진짜 이미지를 구분자에 넣는다.
D_result_from_real = D(real_data)
# 구분자의 출력값이 정답지인 1에서 멀수록 loss가 높아진다.
D_loss_real = criterion(D_result_from_real, target_real)
# 생성자에 입력으로 줄 랜덤 벡터 z를 만든다.
z = Variable(torch.randn((batch_size, 100)))
# 생성자로 가짜 이미지를 생성한다.
fake_data = G(z)
# 생성자가 만든 가짜 이미지를 구분자에 넣는다.
D_result_from_fake = D(fake_data)
# 구분자의 출력값이 정답지인 0에서 멀수록 loss가 높아진다.
D_loss_fake = criterion(D_result_from_fake, target_fake)
# 구분자의 loss는 두 문제에서 계산된 loss의 합이다.
D_loss = D_loss_real + D_loss_fake
# 구분자의 매개 변수의 미분값을 0으로 초기화한다.
D.zero_grad()
# 역전파를 통해 매개 변수의 loss에 대한 미분값을 계산한다.
D_loss.backward()
# 최적화 기법을 이용해 구분자의 매개 변수를 업데이트한다.
D_optimizer.step()
다음으로 생성자를 학습할 차례다. 생성자의 목적은 구분자를 속이는 것이다. 다시 말해 생성자가 만들어낸 가짜 이미지를 구분자에 넣었을 때 출력값이 1에 가깝게 나오도록 해야 한다. 이 값이 1에서 떨어진 정도가 생성자의 손실 함수가 되고, 이를 최소화 시키도록 생성자를 학습시키게 된다.
# <코드8> 생성자 학습시키기
# 생성자에 입력으로 줄 랜덤 벡터 z를 만든다.
z = Variable(torch.randn((batch_size, 100)))
z = z.cuda()
# 생성자로 가짜 이미지를 생성한다.
fake_data = G(z)
# 생성자가 만든 가짜 이미지를 구분자에 넣는다.
D_result_from_fake = D(fake_data)
# 생성자의 입장에서 구분자의 출력값이 1에서 멀수록 loss가 높아진다.
G_loss = criterion(D_result_from_fake, target_real)
# 생성자의 매개 변수의 미분값을 0으로 초기화한다.
G.zero_grad()
# 역전파를 통해 매개 변수의 loss에 대한 미분값을 계산한다.
G_loss.backward()
# 최적화 기법을 이용해 생성자의 매개 변수를 업데이트한다.
G_optimizer.step()


지금까지 코드를 통해 GAN의 원리를 이해해봤다. 이제부터는 GAN이 발표된 이후로 나온 수많은 발전과 응용 중 가장 중요했던 모델들을 살펴보고 GAN으로 할 수 있는 여러 가지 일에 대해 알아보자.
GAN의 전성시대를 연 DCGAN(Deep Convolutional GAN)
GAN은 학습이 불안정하기로 악명이 높다. 학습이 어렵다는 점은 GAN 모델이 다양한 곳에 응용되는 것을 가로막는 큰 장애물이었다. 이런 상황에서 수많은 실험 끝에 안정적인 학습이 가능한 GAN 모델의 구조를 찾아낸 것이 DCGAN이다.
DCGAN의 특징은 몇 가지로 요약할 수 있다. 먼저, 선형 레이어와 풀링 레이어(Pooling Layer)를 최대한 배제하고 합성곱(Convolution)과 ‘Transposed Convolution(Fractional-Strided Convolution)’으로 네트워크 구조를 만들었다. 풀링 레이어는 여러 딥러닝 모델에서 불필요한 매개변수의 수를 줄이고 중요한 특징만을 골라내는 역할을 하는 레이어지만 이미지의 위치 정보를 잃어버린다는 단점이 있다. 이미지를 생성하기 위해서는 위치 정보가 중요하기 때문에 DCGAN은 풀링 레이어를 배제했다. 선형 레이어 역시 마찬가지로 위치 정보를 잃어버리므로 모델의 깊은 레이어에서는 선형 레이어를 사용하지 않았다.
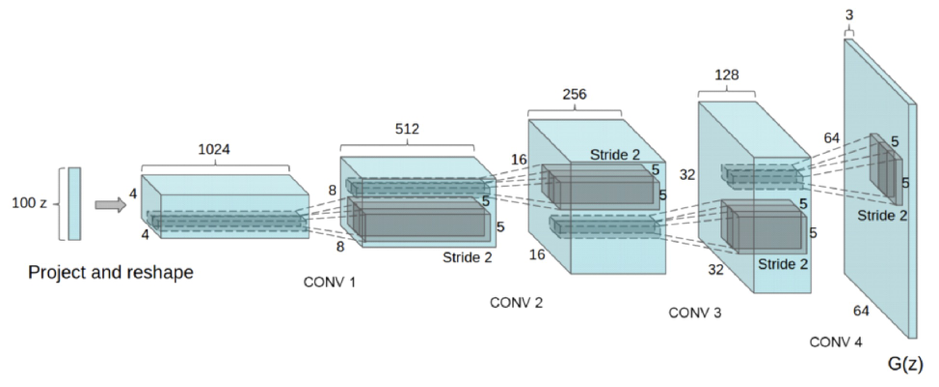
DCGAN의 또 다른 특징은 배치 정규화(Batch Normalization)를 사용했다는 점이다. 배치 정규화는 레이어의 입력 데이터 분포가 치우쳐져 있을 때 평균과 분산을 조정해주는 역할을 한다. 이는 역전파가 각 레이어에 쉽게 전달되도록 해 학습이 안정적으로 이뤄지도록 돕는 데 중요한 역할을 한다.
이외에도 DCGAN은 수많은 실험을 통해 GAN을 학습시키는 가장 좋은 조건들을 찾아냈다. DCGAN은 마지막 레이어를 제외하고 생성자의 모든 레이어에 ReLU를 사용했고, 구분자의 모든 레이어에 LeakyReLU를 사용했다. 또한, 가장 좋은 최적화 기법과 적절한 학습 속도(Learning Rate) 등을 찾아내기도 했다.
DCGAN의 성공은 GAN 모델이 유명해지는 데 결정적인 역할을 했다. DCGAN에서 사용한 모델 구조는 아직도 새로운 GAN 모델을 설계할 때 베이스 모델이 되고 있다.
DCGAN의 네트워크 구조는 기존 GAN에서 생성자와 구분자만 교체하는 것만으로 간단히 구현할 수 있다. DCGAN의 생성자는 GAN과 마찬가지로 랜덤 벡터 z를 받고 가짜 이미지를 생성하는 함수다. 다만 그 구현에서 ‘Transposed Convolution’과 배치 정규화 등을 사용한다는 점이 다르다.
# <코드9> DCGAN의 생성자
class Generator(nn.Module):
# 네트워크 구조
def __init__(self):
super(Generator, self).__init__()
self.main = nn.Sequential(
nn.ConvTranspose2d(in_channels=100, out_channels=28*8,
kernel_size=7, stride=1, padding=0,
bias=False),
nn.BatchNorm2d(num_features=28*8),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(in_channels=28*8, out_channels=28*4,
kernel_size=4, stride=2, padding=1,
bias=False),
nn.BatchNorm2d(num_features=28*4),
nn.ReLU(True),
nn.ConvTranspose2d(in_channels=28*4, out_channels=1,
kernel_size=4, stride=2, padding=1,
bias=False),
nn.Tanh())
# (batch_size x 100) 크기의 랜덤 벡터를 받아
# 이미지를 (batch_size x 1 x 28 x 28) 크기로 출력한다.
def forward(self, inputs):
inputs = inputs.view(-1, 100, 1, 1)
return self.main(inputs)
DCGAN의 구분자도 GAN의 구분자와 입력과 출력이 동일하다. 단지 convolution 레이어와 배치 정규화 등을 사용한다는 차이점만 있다.
# <코드10> DCGAN의 구분자
class Discriminator(nn.Module):
# 네트워크 구조
def __init__(self):
super(Discriminator, self).__init__()
self.main = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=28*4,
kernel_size=4, stride=2, padding=1,
bias=False),
nn.BatchNorm2d(num_features=28*4),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=28*4, out_channels=28*8,
kernel_size=4, stride=2, padding=1,
bias=False),
nn.BatchNorm2d(num_features=28*8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=28*8, out_channels=1,
kernel_size=7, stride=1, padding=0,
bias=False),
nn.Sigmoid())
# (batch_size x 1 x 28 x 28) 크기의 이미지를 받아
# 이미지가 진짜일 확률을 0~1 사이로 출력한다.
def forward(self, inputs):
o = self.main(inputs)
return o.view(-1, 1)
DCGAN의 또 다른 혁신은 학습이 잘 이뤄졌는지 확인하기 위한 여러 가지 검증 방법을 도입했다는 점이다. 그 중 하나가 잠재 공간에 실제 데이터의 특성이 투영됐는지 살펴보는 것이다. 예를 들어 사람 얼굴을 생성하는 모델이 잘 학습되면 단순히 사람 얼굴을 잘 만들어내는 것뿐만 아니라 성별, 머리 색깔, 얼굴방향, 선글라스를 썼는지 여부 등 의미 있는 단위들이 잠재 공간에 드러나게 된다. 즉 생성자의 입력인 100차원짜리 ‘z’ 벡터의 값을 바꿔보는것으로 생성자의 출력인 이미지의 속성을 바꿔볼 수 있다는 것이다.
예를 들어 잠재공간에서 얼굴 방향에 해당하는 특성을 찾아낼 수 있고, ‘z’ 벡터에서 이에 해당하는 값을 바꿈으로써 이미지에서 얼굴이 바라보고 있는 방향을 바꿔볼수 있다. 이것이 가능하다는 것은 생성자가 얼굴의 의미적인 속성을 학습했다는 것을 뜻한다.

이미지를 새로운 이미지로 변형하는 cGAN
때때로 이미지를 처음부터 생성하기보다 이미 있는 이미지를 다른 영역의 이미지로 변형하고 싶은 경우가 많다. 예를 들어, 스케치에 채색하거나, 흑백 사진을 컬러로 만들거나, 낮 사진을 밤 사진으로 바꾸고 싶을 때 등이다. ‘cGAN(Conditional GAN)’은 이를 가능케 해주는 모델이다.
기존의 GAN의 생성자가 랜덤 벡터를 입력으로 받는 것에 비해 cGAN의 생성자는 변형할 이미지를 입력으로 받는다. 그 뒤 생성자는 입력 이미지에 맞는 변형된 이미지를 출력한다. 예를 들어 스케치 사진을 받은 생성자는 그 스케치에 맞는 색을 칠한 뒤 채색된 이미지를 출력하는 것이다. 구분자는 스케치와 채색된 이미지를 모두 보고 그 채색된 이미지가 과연 스케치에 어울리는지 판단한다. 구분자를 속이기 위해서 생성자는 첫째, 진짜 같은 이미지를 만들어야 하고 둘째, 스케치에 맞는 이미지를 만들어야 한다.
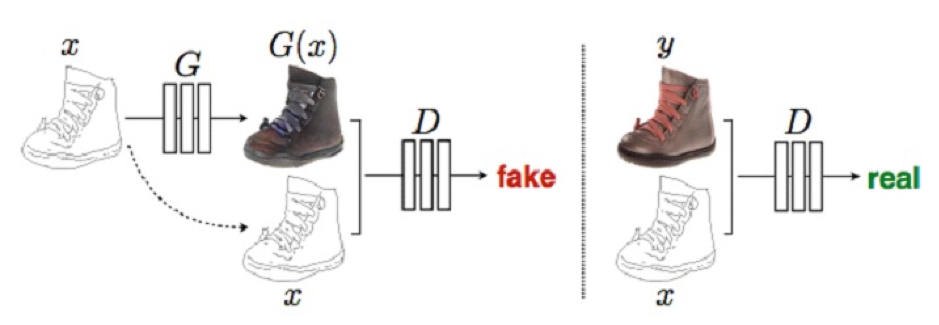
cGAN의 혁신은 주어진 이미지를 새로운 이미지로 변형하는 수많은 문제를 하나의 간단한 네트워크 구조로 모두 풀었다는 점이다. 모든 문제는 이미지에서 의미적인 정보를 찾아내어 다른 이미지로 바꾸는 문제로 볼 수 있기 때문이다. 이렇게 한 영역의 이미지를 다른 영역의 이미지로 변형하는 문제의 경우 cGAN이 유용하게 쓰일 수 있다.
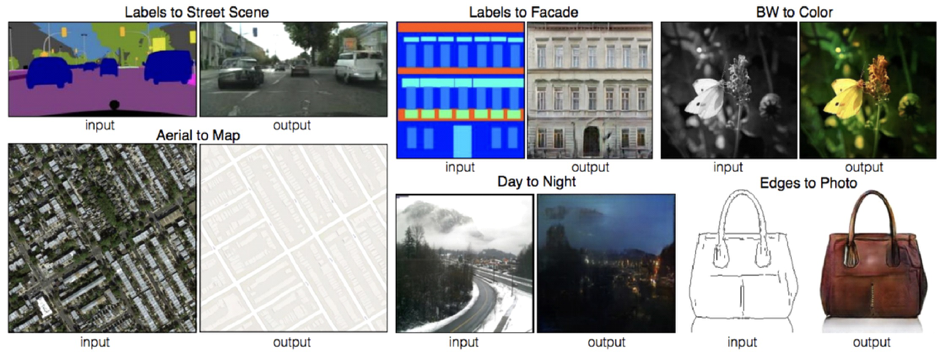
다양한 종류의 GAN
앞서 소개한 모델 외에도 GAN의 성능을 높이고 새로운 분야에 응용하려는 다양한 종류의 GAN 모델이 있다. ‘WGAN(Wasserstein GAN)’은 GAN에서 실제 데이터 분포와 근사하는 분포가 얼마나 다른지 측정하는 거리 개념을 바꿔 안정적인 학습을 가능하게 만들었다. ‘EBGAN(Energy-based GAN)’은 GAN을 에너지 관점에서 바라봄으로써 역시 더 안정적인 학습을 추구했다. ‘BEGAN(Boundary Equilibrium GAN)’은 WGAN과 EBGAN을 발전시켜 생성하는 이미지의 퀄리티를 획기적으로 높이고 이미지의 퀄리티와 다양성을 컨트롤 할 수 있게 했다. 이 글의 처음에 있는 <그림1>의 실제 같은 사람 얼굴 이미지들이 BEGAN의 결과물이다.
cGAN은 강력한 모델이지만 입력 이미지와 출력 이미지가 매칭된 데이터를 필요로 한다. ‘CycleGAN’과 ‘DiscoGAN’은 두 영역의 이미지 데이터셋이 매칭돼 있지 않아도 이미지 변형을 가능하게 하는 모델이다. 예를 들어 핸드백과 신발의 이미지 데이터셋이 있으면 이 두 영역 사이의 연결을 스스로 찾아내어 주어진 핸드백 이미지와 같은 스타일의 신발 이미지를 생성한다(CycleGAN과 DiscoGAN은 거의 동일한 구조를 갖고 있다). ‘StarGAN’은 이 아이디어를 확장시켜 세 개 이상의 영역 사이의 이미지 변형을 시도했다.
GAN을 다양한 분야에 응용하려는 시도도 활발하다. 사진의 해상도를 높이는 ‘SRGAN(Super-Resolution GAN)’이나, 음성 녹음에서 노이즈를 줄여주는 ‘SEGAN(Speech Enhancement GAN)’을 예로 들 수 있다.

GAN의 한계점
GAN은 많은 기대를 받고 있는 모델이지만 아직 여러 가지 한계점도 존재한다. 앞서 소개한 많은 모델이 GAN의 학습을 안정화시키기 위해 노력했지만, 아직도 GAN을 실제로 적용하려 할 때 가장 큰 걸림돌은 학습이 어렵다는 점이다. GAN 학습이 잘 되기 위해서는 서로 비슷한 수준의 생성자와 구분자가 함께 조금씩 발전해야 한다. 그런데 한쪽이 너무 급격하게 강력해지면 이 관계가 깨져버려서 GAN의 학습이 이루어지지 않는다. 경찰이 너무 강력하면 위조지폐범의 씨가 말라버리는 것이다.
GAN이 제대로 학습을 하지 못하고 있을 때 나타나는 모드붕괴(Mode Collapse)라는 현상이 있다. 이는 생성자가 다양한 이미지를 만들어내지 못하고 비슷한 이미지만 계속해서 생성하는 경우를 뜻한다. GAN을 학습시킬 때는 이런 모드 붕괴 현상이 벌어지지 않는지, 생성자와 구분자 중 한 쪽이 너무 강해지지 않는지 유의해야 한다.
GAN의 학습이 너무 어려울 때는 ‘VAE(Variational Auto-Encoder)’라는 모델을 쓰는 것도 고려해 볼 수 있다. VAE는 생성 모델이라는 목적은 GAN과 같지만, GAN과는 다른 방식으로 동작한다. VAE는 GAN보다 학습이 좀 더 안정적이라는 점이 장점이지만, 흐릿한 이미지가 생성되는 블러(Blur) 현상이 있다고 알려져 있다.
GAN의 또 다른 한계점은 아직 텍스트를 생성하는 데는 적용하기 어렵다는 점이다. 이미지나 음성 분야에서는 GAN의 성공 사례가 많이 있지만, 영어나 한국어 같은 자연어를 생성하는 문제에는 GAN의 성공 사례를 찾아보기 어렵다. 이는 텍스트가 이미지와 달리 불연속적이기 때문이다. 이미지는 실수값인 픽셀로 이루어져 있기 때문에 미분을 통해 조금씩 값을 바꿔보며 개선해 나갈 수 있다. 하지만 텍스트는 단어로 이뤄져 있기 때문에 이런 방식이 불가능하다. 물론 GAN으로 텍스트를 생성하려는 시도가 없었던 것은 아니지만, 아직 뚜렷한 성과는 내지 못하고 있다.
마치며
이안 굿펠로우(Ian Goodfellow)가 GAN을 처음 발표한 것은 2014년이다. 그 후 4년에 가까운 시간이 지나는 동안 GAN에는 수많은 발전이 있었다. 이제 GAN으로 사람 눈으로도 진짜와 구분하기 힘든 얼굴 이미지를 생성하고, 스케치에 채색을 입히고, 핸드백과 같은 스타일의 신발을 만들어낼 수 있다. 그러나 여전히 GAN은 태어난지 얼마 되지 않은 모델이고 앞으로 더욱 놀라운 결과물을 내는 모델들과 서비스들이 발표될 것이다. 이 글이 GAN이라는 혁신적인 모델을 이해하는 데 도움이 되고 인공 지능의 물결에 올라타는 발판이 됐으면 하는 바람이다.
참고 자료
- GAN: https://arxiv.org/abs/1406.2661
- DCGAN: https://arxiv.org/abs/1511.06434
- cGAN: https://arxiv.org/abs/1611.07004
- WGAN: https://arxiv.org/abs/1701.07875
- EBGAN: https://arxiv.org/abs/1609.03126
- BEGAN: https://arxiv.org/abs/1703.10717
- CycleGAN: https://arxiv.org/abs/1703.10593
- DiscoGAN: https://arxiv.org/abs/1703.05192
- StarGAN: https://arxiv.org/abs/1711.09020
- SRGAN: https://arxiv.org/abs/1609.04802
- SEGAN: https://arxiv.org/abs/1703.09452