Article Source
Fast Counts on Big Data Systems using Presto or BigQuery and VerdictDB
How do you get count estimates over Billions of rows consistently quickly (under 4 seconds) when users can define their own predicates?
The problem:
“To create a system where a customer can design their own audience by choosing and combining different filters”
I won’t go heavily into the analysis of this problem in this article but we eventually landed upon a system that would generate a “query” (not necessarily SQL) that we can run against our data warehouse to produce the audience.
The tricky part of this — was “How do we get an estimate displayed to the customer of the audience size”?
As the end user can design an audience from any combination of 8 filters (each filter contains 100’s — 1000’s of options that frequently change as new data comes in) pre-caching the counts on each processing wasn’t really feasible — especially since we were also providing the ability to filter between specific dates meaning each date range would need to be pre-cached too!
Early experiments
We decided upon an example query that we used as our basic benchmark test case — it looked something like this:
Example Query
SELECT count(distinct(id)) from datatable d
LEFT JOIN polygons p ON ST_DWITHIN(ST_MAKEPOINT(d.lon,d.lat), p.geom, 0.1)
WHERE p.place_cat IN ('beauty', 'sports')
We experimented with a number of different methods to get a feel for each platform and what it offers. Naturally, we started with the basics and well known offerings, however, we had a number of different requirements from each Database / Data Warehouse that doesn’t really make this a fair comparison to many of them in a lot of ways (for example we require Geospatial capabilities which ruled out a number of other platforms).

Why count(distinct()) is king for accuracy — but definitely not equitable.
Most readers of this will understand what count(distinct()) does, what many people don’t understand (or think about) is HOW it does what it does.

Counting distinct entities in a huge dataset is actually a hard problem, it is slightly easier if the data is sorted but re-sorting data on each insert becomes expensive depending on the underlying platform used.
Generally a count distinct performs a distinct sort and then counts the items in each “bucket” of grouped values.
If you need a 100% accurate count then this is unfortunately pretty much the only way you can get it on a randomised dataset, there are tricks you can do in how things are structured in the platform to make things more efficient (partitioning, clustering / bucketing for example) but it essentially still has to perform the same operations.
The Tradeoff — Accuracy vs Speed
Often there are use cases that don’t require 100% accuracy, ours is one of them as the audience size is simply an estimate — this gives us a few extra options.
There are many existing sampling methods that exist but their accuracy is too low for our requirements — in this case we needed something that had the right balance.
The Solution using VerdictDB
Early on in the process we contacted VerdictDB who had released an early beta of their open source product that purported to do exactly what we required. VerdictDB uses probability / statistical theory to create estimates of cardinality on large datasets. But most importantly for us it allows this to be created over the entire table.
We set up a pipeline using Airflow to orchestrate the data preparation to ensure that everything was ready

VerdictDB works by creating “Scrambles” of the table, this is a pre-processing stage which requires a significant amount of processing power but it only needs to be done once when new data is added.
We performed this on both Presto and on BigQuery — BigQuery came out cheaper for our particular use case but there are a number of reasons for that (not applicable to this article).
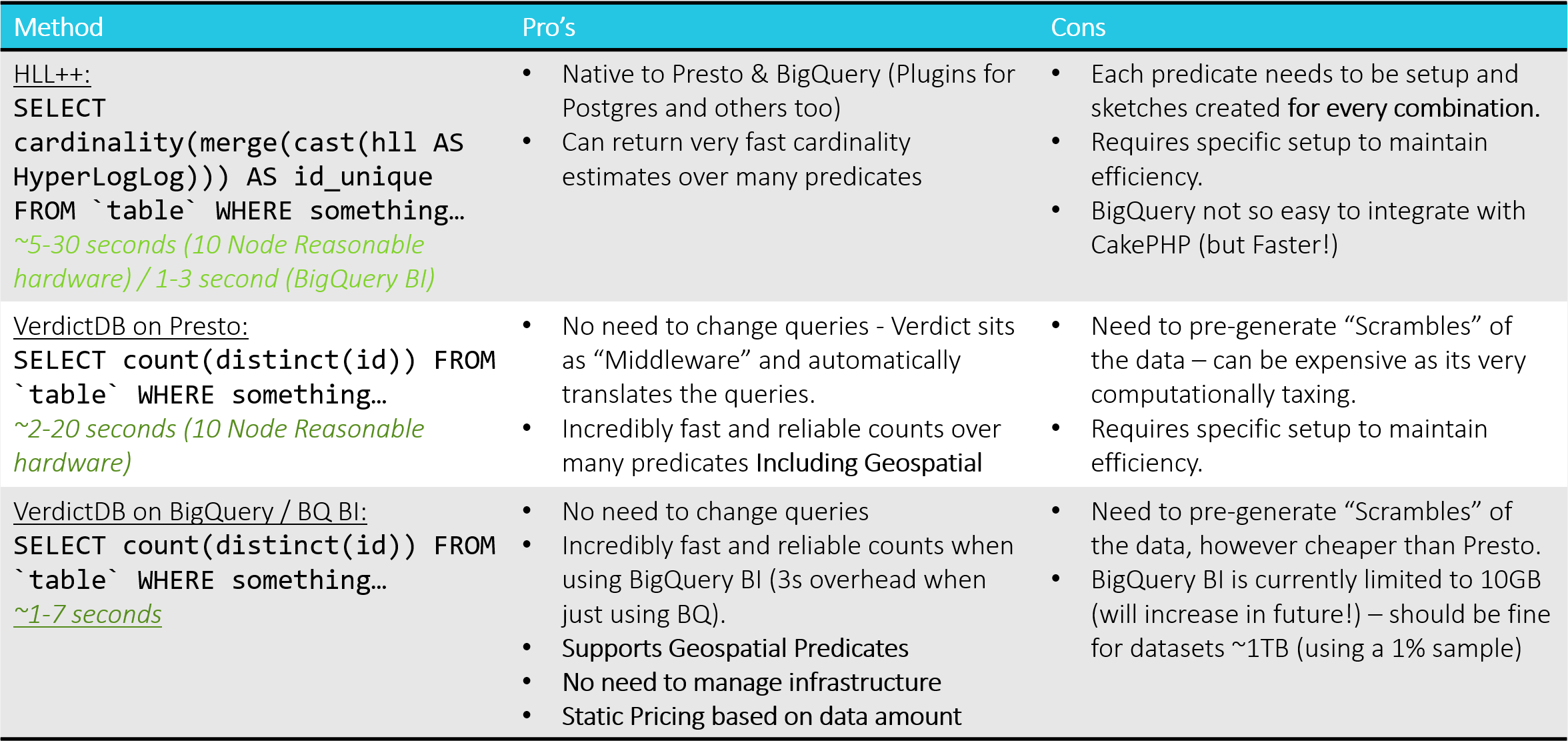
Final results
Here is a table listing the final results of each method. BigQuery came out on top for a number of different reasons as the backing data warehouse, however the focus of this is really on what VerdictDB can really provide in terms of simplicity and speed vs traditional methods such as HyperLogLog.
Conclusion
With the use of VerdictDB both Presto and BigQuery provided the speed required to allow a human interface to our Data Warehouse, BigQuery out performed Presto in a number of areas especially when BigQuery BI was thrown into the equation, and although this is still in beta offering only 10GB (should be enough to cache a 1% scramble of 1TB of data), it has huge potential in offering a cost-effective and fast interface to Big Data.
If you want to avoid vendor lock-in then Presto is a fantastic choice, there are however considerations as to latency and the partioning schema you would use to ensure this is fast enough! There are also several other options that exist that could be used as the query interface once the scrambles are built on Presto!