Article Source
Google Cloud BigQuery ML Using SQL

As the Machine learning model are been utilized in different fields and with the advancement of technologies (Better hardware and High-level Programming languages) it is getting easier to build a working machine learning model that fits your needs. The process of making Machine learning models is getting simpler and lines of codes are getting less.
In this article, I will show you how to build a custom ML model with just SQL using Google BigQuery ML.
But first, what is Google BigQuery?
Google BigQuery is a server-less, cost-effective, and highly scalable data warehouse system provided by Google Cloud Platform with lots of features for business agility. BigQuery ML is one such feature which helps data scientist, data analysts and Data engineers(like me) to build operational production-grade ML models. We can create a model on structures as well as unstructured data. Most importantly just by using a SQL environment using queries in a short period.
In this article we will complete the following task:
- Use as sample data set, “German Credit data” to predict good or bad loan application.
- Divide the sample data into the train and test set.
- Create and load the data in the Google BigQuery table.
- Create a “logistic regression” model just by using SQL.
- And, finally, we will evaluate and predict the loan types as good or bad.
Sample Data That We Will Be Using
We will be using a sample structured data set “German credit data”.
You can also download the files from below git repository:
https://github.com/aakash-rathore/BigQueryML/tree/master/data
├── data
│ ├── germanCredit.csv
│ ├── GermanCredit.xls
│ ├── testData.csv
│ └── trainData.csv
├── README.md
└── test_train.py
In the repository “GermanCredit.xls” in the raw data file which gives details of all columns data. I have encoded all the categorical data and created a file “GermanCredit.csv” and “test_train.py” is a python script to divide the data in test and train data set(testData.csv and trainData.csv)
Loading Data In BigQuery
Login into the Google Cloud Platform Console and navigate to the BigQuery tab using the left options panel.
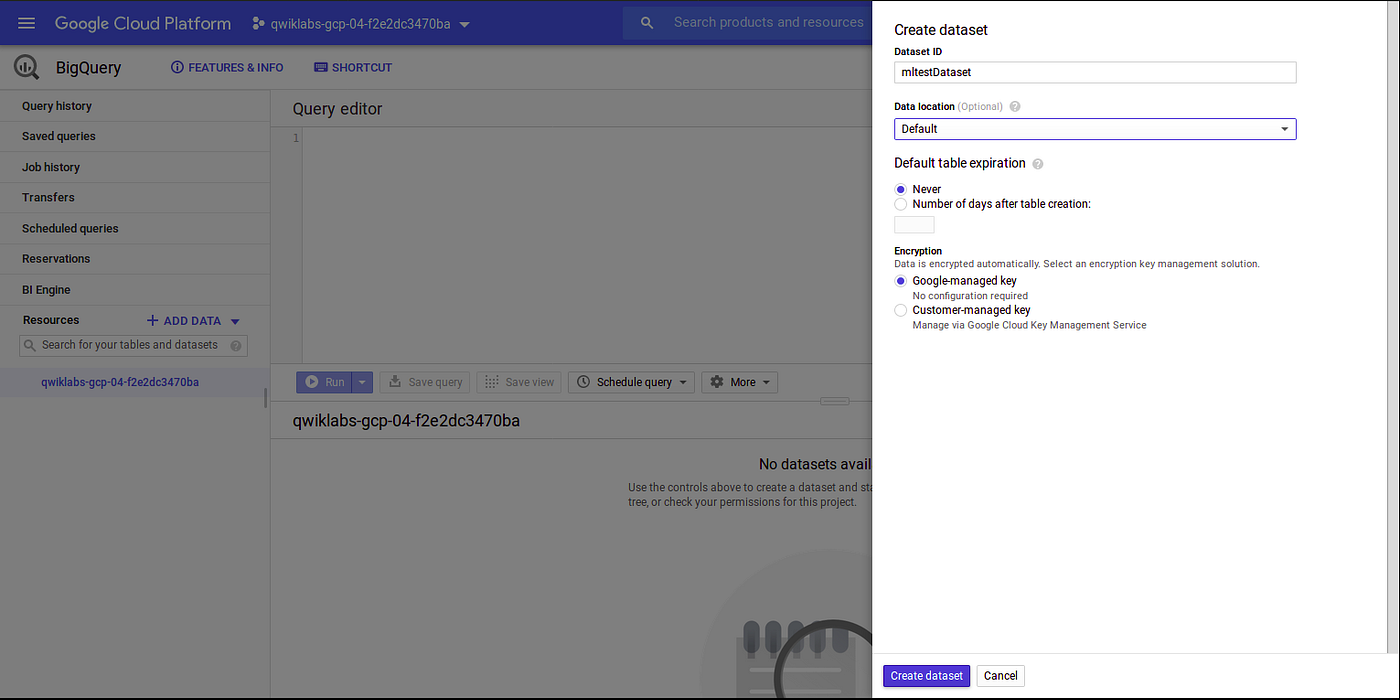
Create a data set using option present in BigQuery console.
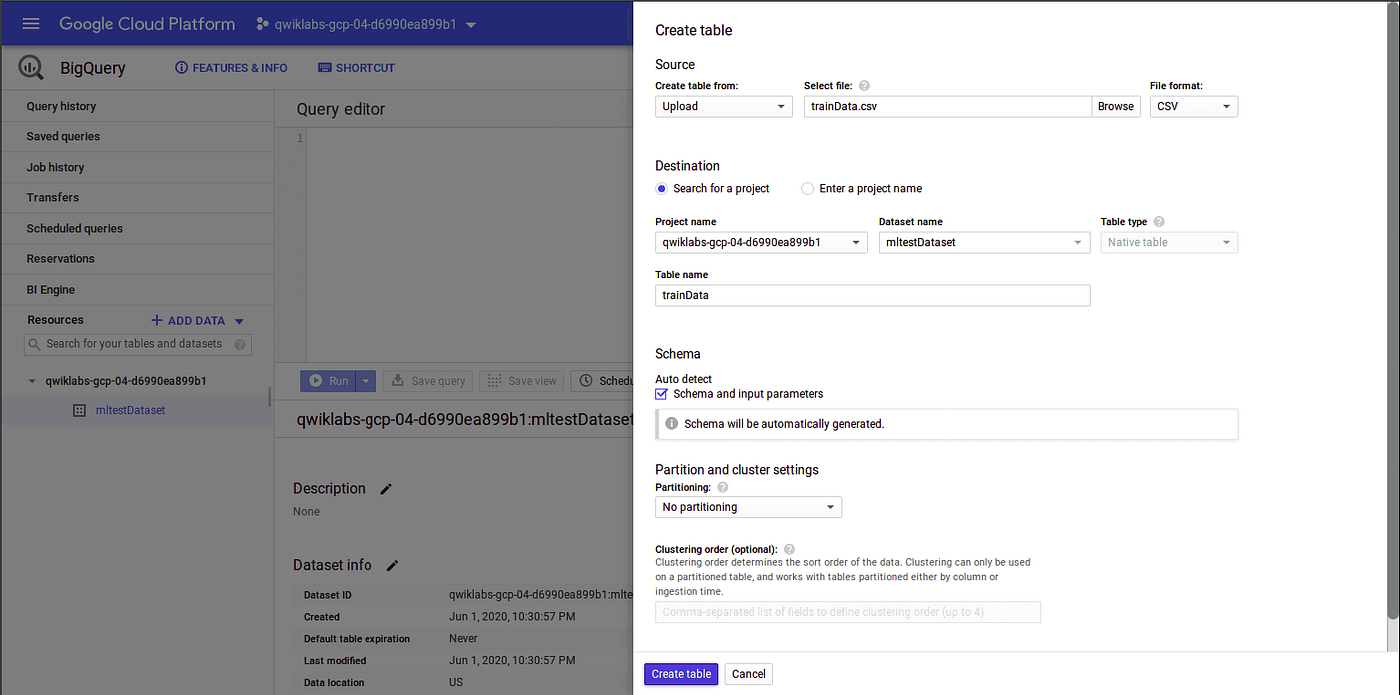
Create tables from trainData.csv and testData.csv inside the previously created data set.
We can preview the sample data in created tables using the “Preview “ option after selecting the respective table.
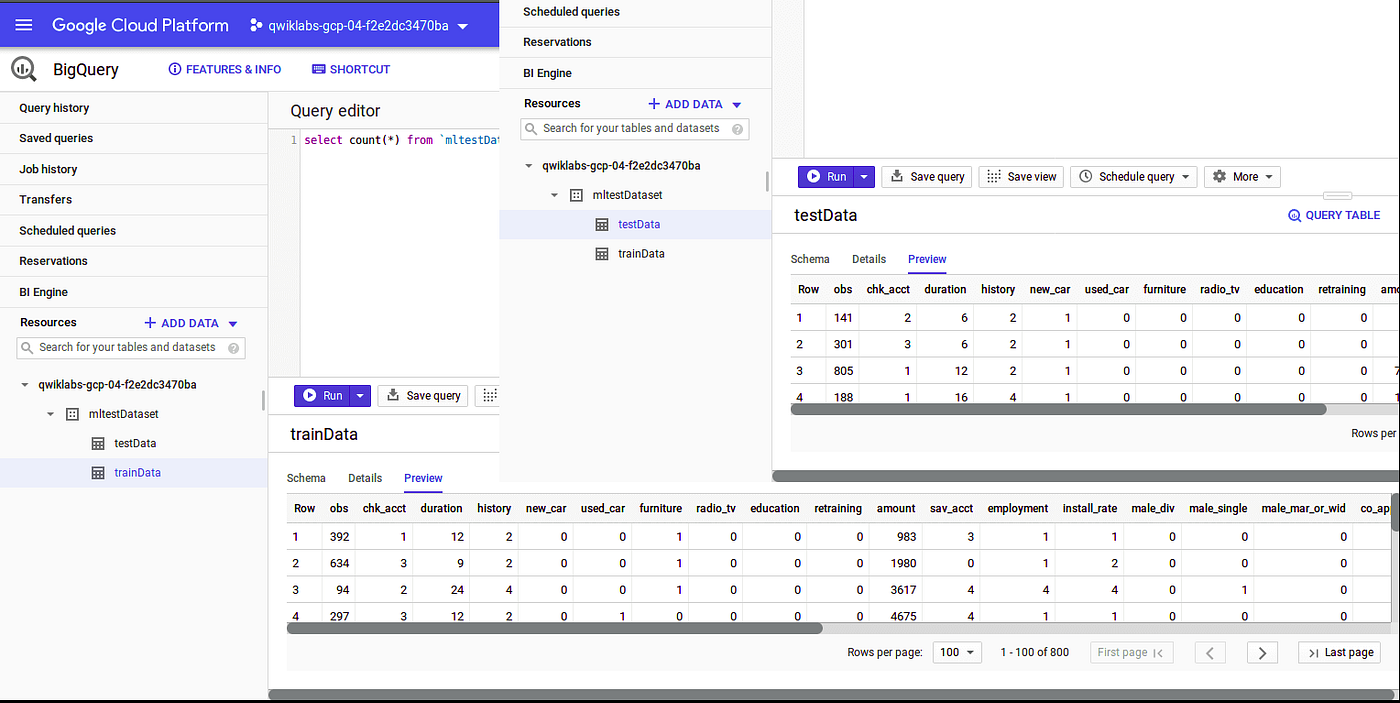
Now we can start creating an ML model, in our sample data “response” column is the label which is the result (1=good, 0=bad) and other columns are input features. The amazing thing is that we will be using only SQL queries to create and evaluate our ML model.
Creating ML Model
We will create a Logistics Regression model which is a classification model, in our case we will use it to classify whether the loan application is good or not based on previous credit report data.
SQL query to create an ML model:
# Creating logistic regression model using data from trainData tableCREATE OR REPLACE MODEL
`mltestDataset.credit_classification_model` OPTIONS ( model_type='logistic_reg' labels=['response'] ) AS
SELECT
* EXCEPT(obs)
FROM
`mltestDataset.trainData`
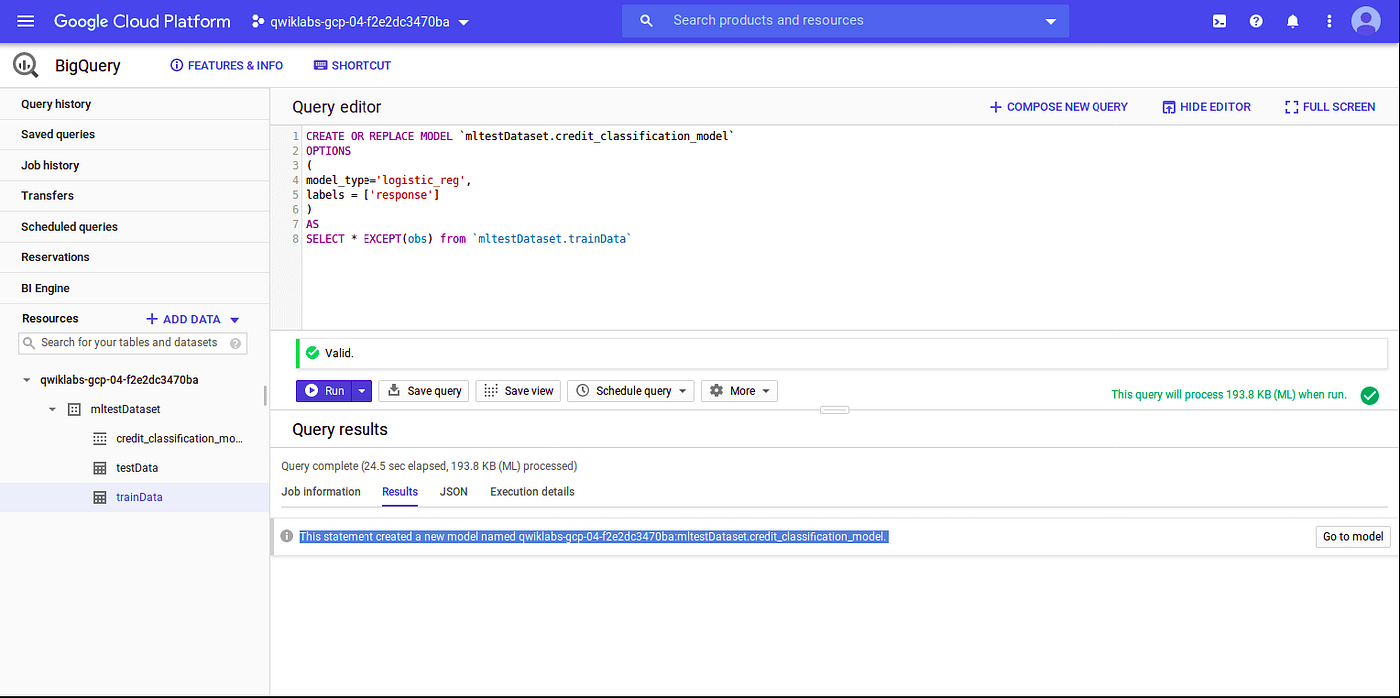
Evaluate Created ML Model
There are different performance parameter to evaluate an ML model, in our created ML model roc_auc is one such simple queryable field when evaluating our trained ML model.
SQL query to evaluate the ML model:
# Evaluating logistic regression model using data from testData tableSELECT
roc_auc,
CASE
WHEN roc_auc > .8 THEN 'good'
WHEN roc_auc > .7 THEN 'fair'
WHEN roc_auc > .6 THEN 'not great'
ELSE
'poor'
END
AS model_quality
FROM
ML.EVALUATE(MODEL mltestDataset.credit_classification_model,
(
SELECT
* EXCEPT(obs)
FROM
`mltestDataset.testData` ) )
Output:
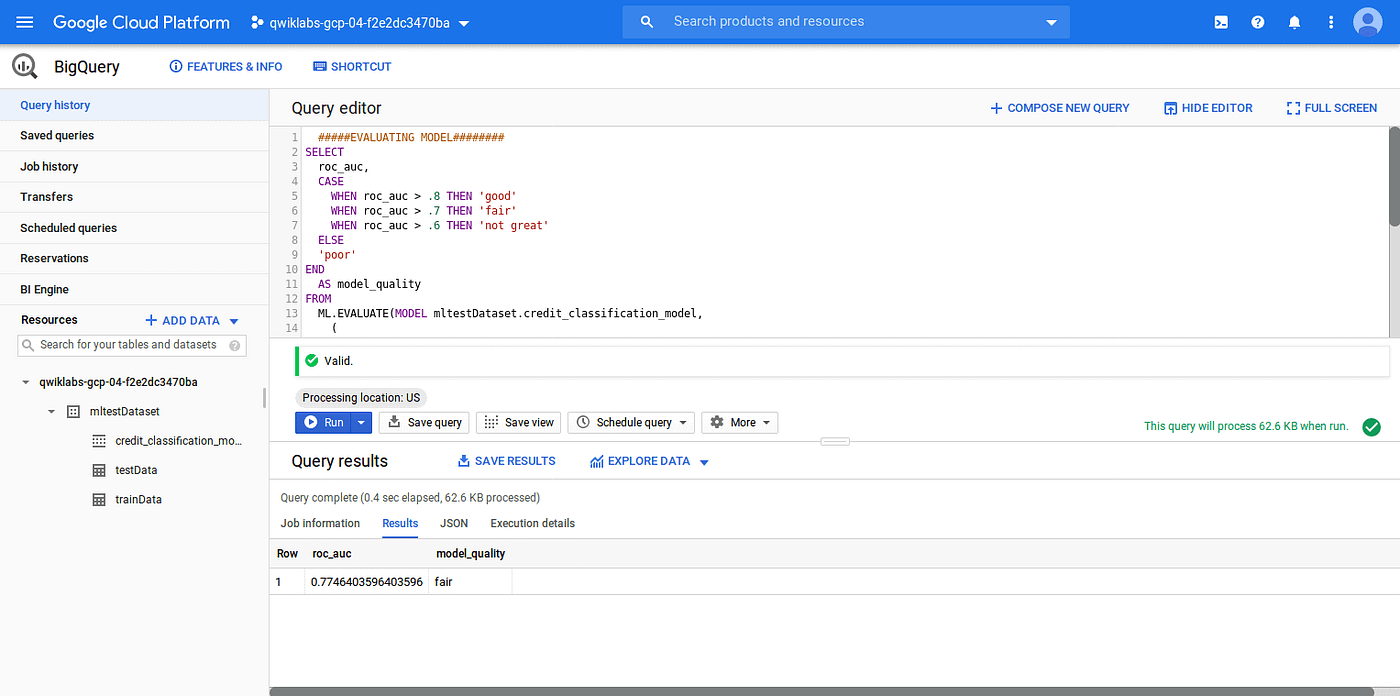
As you can see the performance somewhat fair, we can improve the performance by tuning the model using feature engineering. But for simplicity, we will use this model to analyze the prediction.
Prediction Using Created ML Model
Now we will use this model to predict the loan type(1=Good,0=Bad). Query to get the prediction from the model is given below:
# Getting prediction for our ML model using data from testData tableSELECT
*
FROM
ml.PREDICT(MODEL `mltestDataset.credit_classification_model`,
(
SELECT
* EXCEPT(obs)
FROM
`mltestDataset.testData` ) );
Output:
We will check the first 5 predictions:
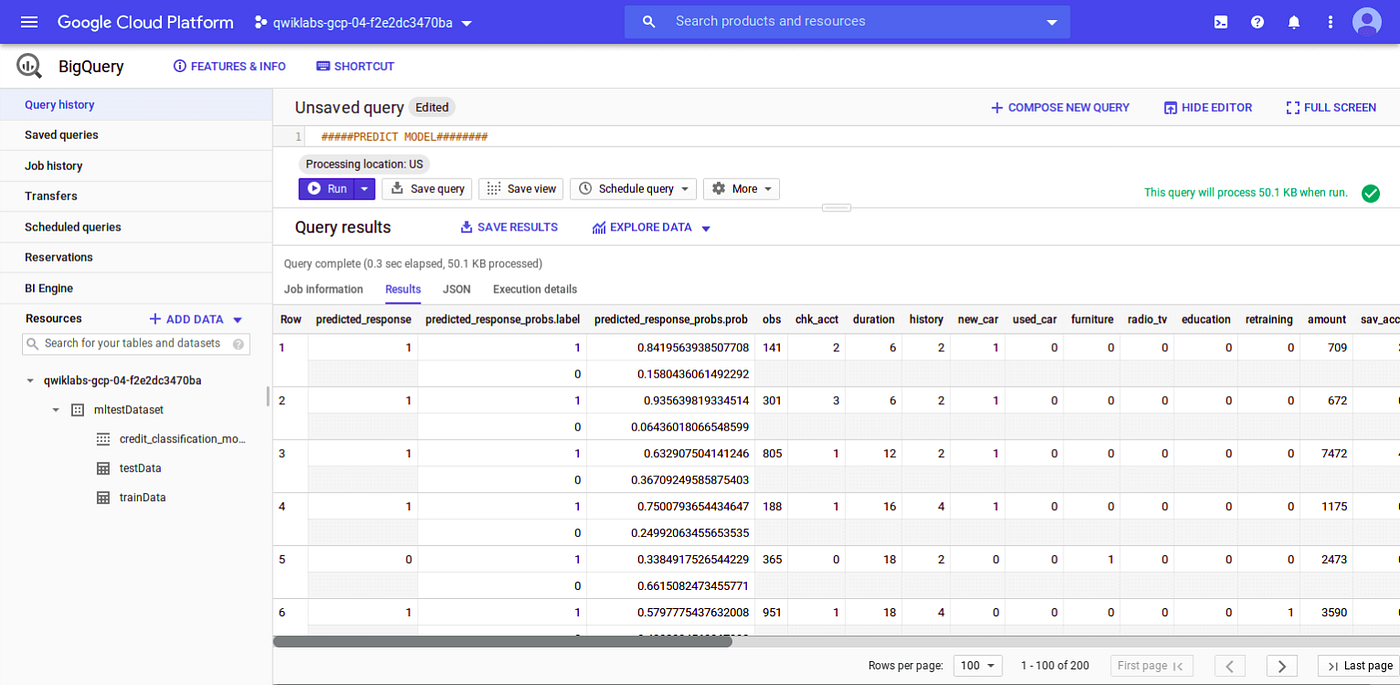
We can see the result of the first 5 predictions:
- For 1st record, our model predicts the loan as good(response=1) with 84% confidence, and actually, it is good (response=1).
- For the 2nd record, the model predicts the loan as good(response=1) with 93% confidence, and actually, it is good (response=1).
- For the 3rd record, the model predicts the loan as good(response=1) with 63% confidence, and actually, it is good (response=1).
- For the 4th record, the model predicts the loan as good(response=1) with 74% confidence, and actually, it is good (response=1).
- For the 5th record, the model predicts the loan as bad(response=0) with 66% confidence, and actually, it is bad (response=0).
Conclusion
In this article, I explained how we can create and evaluate an ML model in Google BigQuery using SQL. Later we analyzed the prediction made by this model.