Article Source
LLM 그래프 트랜스포머를 활용한 지식 그래프 구축
LangChain이 LLM을 사용해 그래프를 구성하는 구현 방식을 심도 있게 살펴본다.
텍스트에서 그래프를 생성하는 것은 굉장히 흥미롭지만 확실히 도전적이다. 기본적으로 비정형 텍스트를 구조화된 데이터로 변환하는 작업이다. 이 접근 방식은 오랜 기간 사용되어 왔지만, 대형 언어 모델(LLM)의 등장으로 주류에 진입하게 되었다.
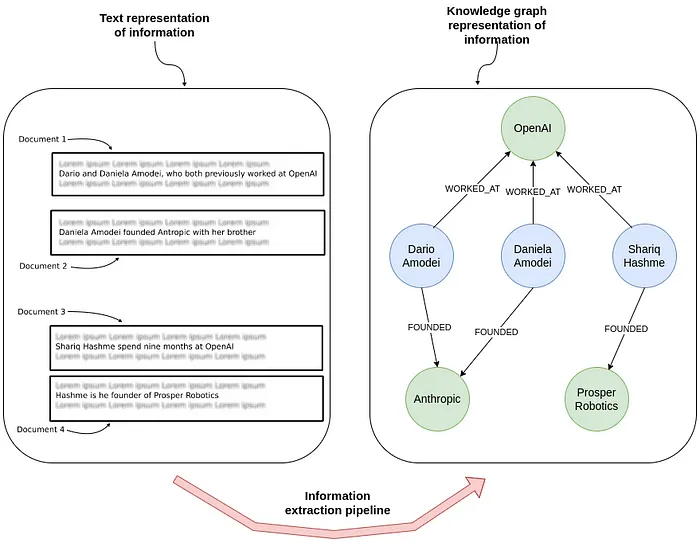
위 이미지에서는 정보 추출이 원시 텍스트를 지식 그래프로 변환하는 과정을 보여준다. 왼쪽에는 여러 문서가 개인과 그들이 기업과 맺은 관계에 대한 비정형 문장을 나타내고, 오른쪽에는 동일한 정보가 개체와 그 연결관계로 표현되어 누가 어떤 조직에서 근무했거나 창업했는지 나타낸다.
텍스트에서 구조화된 정보를 추출해 그래프로 표현하는 이유는 RAG(retrieval-augmented generation) 애플리케이션을 지원하기 위함이다. 비정형 텍스트에 텍스트 임베딩 모델을 사용하는 방식은 유용하지만, 여러 개체 간 연결 관계를 이해해야 하는 복잡한 다단계 질문이나 필터링, 정렬, 집계 같은 구조적 연산이 필요한 질문에는 한계가 있다. 텍스트에서 구조화된 정보를 추출하고 지식 그래프를 구성하면 데이터를 보다 효과적으로 정리할 뿐 아니라, 개체 간 복잡한 관계를 이해할 수 있는 강력한 프레임워크를 제공한다. 이 구조화된 접근 방식은 특정 정보를 훨씬 쉽게 검색하고 활용할 수 있게 하여, 답변 가능한 질문 유형을 확장하고 정확도를 높인다.
약 1년 전 LLM을 사용해 그래프를 구축하는 실험을 시작했고, 관심이 높아짐에 따라 이 기능을 LangChain에 LLM 그래프 트랜스포머로 통합하기로 결정했다. 지난 1년 동안 귀중한 통찰을 얻고 새로운 기능을 도입했으며, 이 포스트에서 이를 소개한다.
코드는 GitHub에서 확인할 수 있다.
Neo4j 환경 설정
기본 그래프 저장소로 Neo4j를 사용하며, 기본 제공되는 그래프 시각화 기능을 갖추고 있다. 시작하는 가장 쉬운 방법은 Neo4j Aura의 무료 인스턴스를 사용하는 것으로, 클라우드 기반의 Neo4j 데이터베이스 인스턴스를 제공한다. 또는 Neo4j Desktop 애플리케이션을 다운로드해 로컬 데이터베이스 인스턴스를 생성할 수도 있다.
from langchain_community.graphs import Neo4jGraph
graph = Neo4jGraph(
url="bolt://54.87.130.140:7687",
username="neo4j",
password="cables-anchors-directories",
refresh_schema=False
)
LLM 그래프 트랜스포머
LLM 그래프 트랜스포머는 어떤 LLM을 사용하더라도 유연하게 그래프를 구축할 수 있는 프레임워크를 제공하도록 설계되었다. 다양한 제공자와 모델이 존재함에 따라 이 작업은 결코 간단하지 않다. 다행히도 LangChain이 대부분의 표준화 과정을 처리한다. LLM 그래프 트랜스포머 자체는 마치 코트 속에 두 마리의 고양이가 들어있는 것처럼 완전히 독립적인 두 가지 모드로 작동할 수 있다.
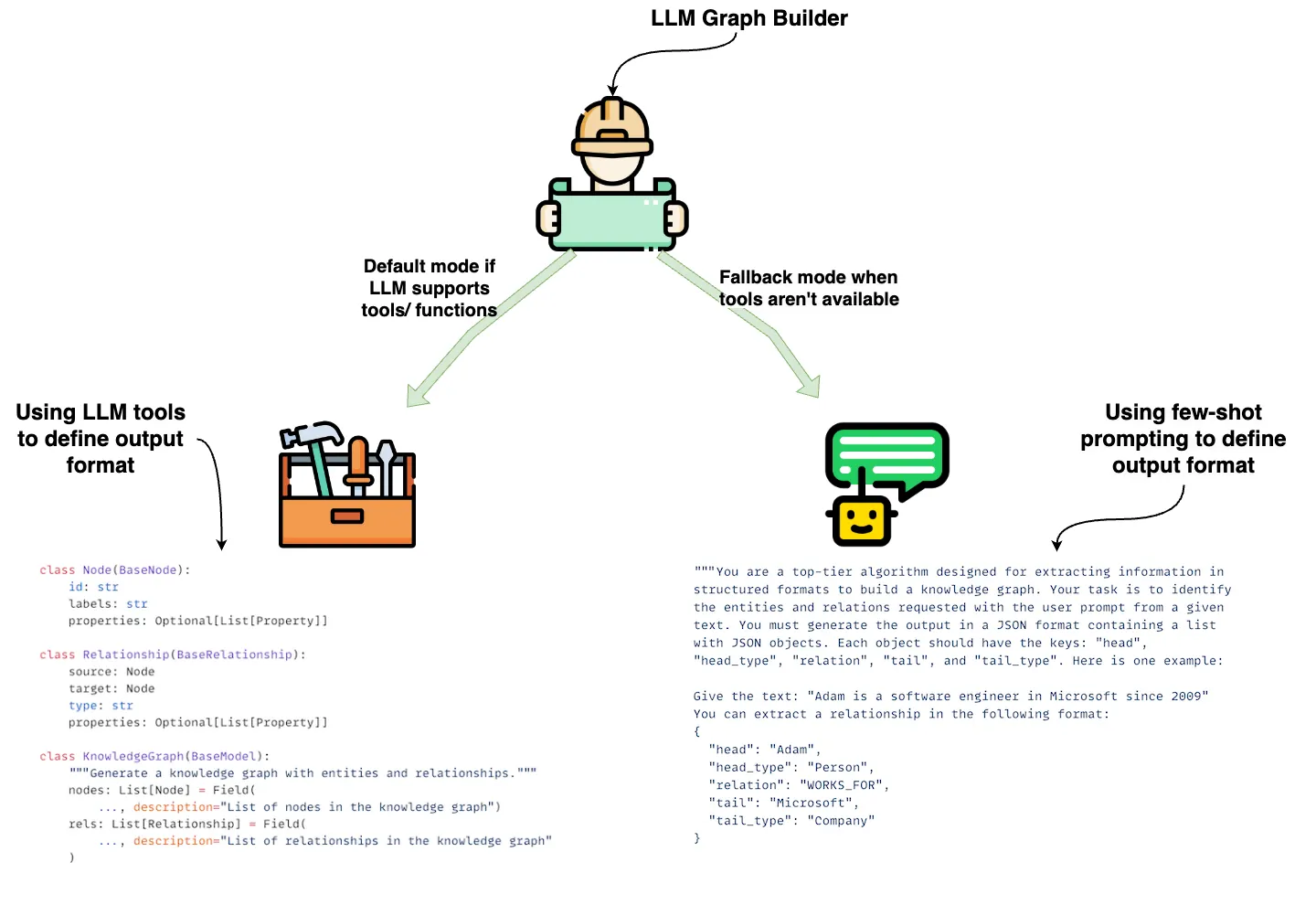
LLM 그래프 트랜스포머는 두 가지 뚜렷한 모드로 작동하며, 각각 다른 상황에서 LLM을 사용해 문서로부터 그래프를 생성하도록 설계되었다.
도구 기반 모드 (기본값)
LLM이 구조화된 출력 또는 함수 호출을 지원할 경우, 이 모드는 LLM의 내장 기능인 with_structured_output을 활용해 도구를 사용한다. 도구 사양은 출력 형식을 정의하여 개체와 관계가 구조화되고 미리 정의된 방식으로 추출되도록 보장한다. 이는 이미지 왼쪽에 표시된 Node와 Relationship 클래스의 코드에서 확인할 수 있다.
프롬프트 기반 모드 (대체 방식)
LLM이 도구나 함수 호출을 지원하지 않는 경우, LLM 그래프 트랜스포머는 순수 프롬프트 기반 방식으로 전환한다. 이 모드는 몇 개의 예시(few-shot)를 이용해 출력 형식을 정의하며, LLM이 텍스트 기반 방식으로 개체와 관계를 추출하도록 안내한다. 그 후 결과를 커스텀 함수로 파싱해 LLM의 출력을 JSON 형식으로 변환한다. 이 JSON은 도구 기반 모드와 마찬가지로 노드와 관계를 채우는 데 사용되지만, 이 경우 LLM은 구조화된 도구가 아닌 프롬프트에 의해서만 안내된다. 이는 이미지 오른쪽에 예시 프롬프트와 결과 JSON 출력이 제공된 것을 통해 확인할 수 있다.
이 두 모드는 LLM 그래프 트랜스포머가 다양한 LLM에 적응할 수 있도록 하며, 도구를 직접 사용하거나 텍스트 기반 프롬프트의 출력을 파싱하는 방식으로 그래프를 구축할 수 있게 한다.
도구/함수를 지원하는 모델에서도 ignore_tool_usage=True 속성을 설정하면 프롬프트 기반 추출을 사용할 수 있다.
도구 기반 추출
초기에는 광범위한 프롬프트 엔지니어링과 커스텀 파싱 함수의 필요성을 줄이기 위해 도구 기반 접근 방식을 선택했다. LangChain의 with_structured_output 메소드는 도구나 함수를 사용해 정보를 추출할 수 있게 하며, 출력은 JSON 구조 또는 Pydantic 객체로 정의할 수 있다. 개인적으로 Pydantic 객체가 더 명확하다고 판단해 이를 선택했다.
Node 클래스를 정의하는 것으로 시작한다.
class Node(BaseNode):
id: str = Field(..., description="Name or human-readable unique identifier")
label: str = Field(..., description=f"Available options are {enum_values}")
properties: Optional[List[Property]]
각 노드는 id, label, 그리고 선택적 properties를 가진다. 간결함을 위해 전체 설명은 생략했다. 일부 LLM은 id 속성을 임의 문자열이나 증가하는 정수로 이해하는 경향이 있어, 사람이 읽을 수 있는 고유 식별자인 개체의 이름을 id로 사용하도록 한다. 또한 label 설명에 가능한 옵션을 나열해 사용 가능한 label 타입을 제한한다. 추가로 OpenAI와 같은 LLM은 enum 파라미터를 지원하는데, 이를 활용한다.
다음으로 Relationship 클래스를 살펴본다.
class Relationship(BaseRelationship):
source_node_id: str
source_node_label: str = Field(..., description=f"Available options are {enum_values}")
target_node_id: str
target_node_label: str = Field(..., description=f"Available options are {enum_values}")
type: str = Field(..., description=f"Available options are {enum_values}")
properties: Optional[List[Property]]
이것은 Relationship 클래스의 두 번째 버전이다. 처음에는 소스와 타깃 노드로 중첩된 Node 객체를 사용했지만, 중첩 객체가 추출 과정의 정확도와 품질을 떨어뜨린다는 것을 확인해, 소스와 타깃 노드를 source_node_id, source_node_label, target_node_id, target_node_label과 같이 별도의 필드로 평탄화했다. 추가로, LLM이 지정된 그래프 스키마를 준수하도록 노드 레이블과 관계 타입의 설명에 허용 값을 정의한다.
도구 기반 추출 방식은 노드와 관계 모두에 대한 속성을 정의할 수 있게 한다. 아래는 이를 정의하기 위해 사용한 Property 클래스이다.
class Property(BaseModel):
"""A single property consisting of key and value"""
key: str = Field(..., description=f"Available options are {enum_values}")
value: str
각 Property는 키-값 쌍으로 정의된다. 이 방식은 유연하지만 한계가 있다. 예를 들어, 각 속성마다 고유한 설명을 제공하거나 특정 속성을 필수, 다른 속성을 선택적으로 지정할 수 없어서 모든 속성이 선택적으로 정의된다. 또한 속성은 노드나 관계 타입별로 개별적으로 정의되지 않고 전체에 걸쳐 공유된다.
추출을 안내하기 위해 상세한 시스템 프롬프트도 구현했다. 경험상 함수와 인자 설명이 시스템 메시지보다 더 큰 영향을 미치는 경향이 있다. 안타깝게도 현재로서는 LLM 그래프 트랜스포머에서 함수나 인자 설명을 간단히 커스터마이즈할 방법은 없다.
프롬프트 기반 추출
상업용 LLM과 LLaMA 3 중 일부만이 네이티브 도구를 지원하므로, 도구 지원이 없는 모델을 위한 대체 방식으로 프롬프트 기반 추출을 구현했다. 도구를 지원하는 모델에서도 ignore_tool_usage=True를 설정하면 프롬프트 기반 방식으로 전환할 수 있다.
프롬프트 기반 방식에 대한 대부분의 프롬프트 엔지니어링과 예시는 Geraldus Wilsen이 기여했다.
프롬프트 기반 방식에서는 출력 구조를 프롬프트 내에 직접 정의해야 한다. 전체 프롬프트는 별도에서 확인할 수 있으나, 여기서는 상위 개요만 다룬다. 시스템 프롬프트 정의부터 시작한다.
너는 지식 그래프를 구축하기 위해 구조화된 형식으로 정보를 추출하도록 설계된 최고 수준의 알고리즘이다. 너의 임무는 주어진 텍스트에서 사용자 프롬프트에 명시된 개체와 관계를 식별하고, JSON 형식으로 출력을 생성하는 것이다. 이 출력은 JSON 객체들의 리스트여야 하며, 각 객체는 다음 키들을 포함해야 한다:
- **"head"**: 사용자 프롬프트에 명시된 타입 중 하나와 일치해야 하는 추출된 개체의 텍스트.
- **"head_type"**: 명시된 타입 목록에서 선택한, 추출된 head 개체의 타입.
- **"relation"**: 허용된 관계 목록에서 선택한, "head"와 "tail" 사이의 관계 타입.
- **"tail"**: 관계의 tail을 나타내는 개체의 텍스트.
- **"tail_type"**: 제공된 타입 목록에서 선택한, tail 개체의 타입.
가능한 한 많은 개체와 관계를 추출한다.
**개체 일관성**: 개체 표현의 일관성을 보장한다. 예를 들어 "John Doe"라는 개체가 텍스트에 여러 번 다른 이름이나 대명사(예: "Joe", "he")로 나타날 경우, 가장 완전한 식별자를 일관되게 사용한다. 이 일관성은 일관성 있고 쉽게 이해할 수 있는 지식 그래프를 생성하는 데 필수적이다.
**중요 사항**:
- 추가 설명이나 텍스트를 삽입하지 않는다.
프롬프트 기반 방식의 주요 차이점은 LLM에게 개별 노드가 아닌 관계만 추출하도록 요청한다는 점이다. 이는 도구 기반 방식과 달리 고립된 노드가 생성되지 않음을 의미한다. 또한 네이티브 도구 지원이 없는 모델은 일반적으로 성능이 떨어지므로, 노드나 관계의 속성 추출을 허용하지 않아 결과를 단순하게 유지한다.
다음으로 모델에 몇 개의 few-shot 예시를 추가한다.
examples = [
{
"text": (
"Adam is a software engineer in Microsoft since 2009, "
"and last year he got an award as the Best Talent"
),
"head": "Adam",
"head_type": "Person",
"relation": "WORKS_FOR",
"tail": "Microsoft",
"tail_type": "Company",
},
{
"text": (
"Adam is a software engineer in Microsoft since 2009, "
"and last year he got an award as the Best Talent"
),
"head": "Adam",
"head_type": "Person",
"relation": "HAS_AWARD",
"tail": "Best Talent",
"tail_type": "Award",
},
...
]
현재 이 방식에서는 커스텀 few-shot 예시나 추가 지침을 삽입하는 것을 지원하지 않는다. 커스터마이즈할 수 있는 유일한 방법은 prompt 속성을 통해 전체 프롬프트를 수정하는 것이다. 커스터마이즈 옵션 확장은 적극 검토 중이다.
다음으로 그래프 스키마 정의를 살펴본다.
그래프 스키마 정의
정보 추출을 위해 LLM 그래프 트랜스포머를 사용할 때, 모델이 의미 있고 구조화된 지식 표현을 구축하도록 안내하기 위해 그래프 스키마를 정의하는 것이 필수적이다. 잘 정의된 그래프 스키마는 추출할 노드와 관계의 타입 및 각 개체와 관련된 속성을 명시하며, 청사진 역할을 하여 LLM이 원하는 지식 그래프 구조에 맞게 일관되게 정보를 추출하도록 보장한다.
이 포스트에서는 테스트용으로 Marie Curie의 위키피디아 첫 단락에 마지막에 Robin Williams에 관한 문장을 추가한 텍스트를 사용한다.
from langchain_core.documents import Document
text = """
Marie Curie, 7 November 1867 – 4 July 1934, was a Polish and naturalised-French physicist and chemist who conducted pioneering research on radioactivity.
She was the first woman to win a Nobel Prize, the first person to win a Nobel Prize twice, and the only person to win a Nobel Prize in two scientific fields.
Her husband, Pierre Curie, was a co-winner of her first Nobel Prize, making them the first-ever married couple to win the Nobel Prize and launching the Curie family legacy of five Nobel Prizes.
She was, in 1906, the first woman to become a professor at the University of Paris.
Also, Robin Williams.
"""
documents = [Document(page_content=text)]
모든 예제에서는 GPT-4o를 사용할 것이다.
from langchain_openai import ChatOpenAI
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass("OpenAI api key")
llm = ChatOpenAI(model='gpt-4o')
먼저 그래프 스키마를 정의하지 않은 상태에서 추출 과정이 어떻게 작동하는지 살펴본다.
from langchain_experimental.graph_transformers import LLMGraphTransformer
no_schema = LLMGraphTransformer(llm=llm)
이제 비동기 함수 aconvert_to_graph_documents를 사용해 문서를 처리한다. LLM 추출 시 async를 사용하는 것이 권장되며, 여러 문서를 병렬로 처리해 대기 시간을 크게 줄이고 처리량을 개선할 수 있다.
data = await no_schema.aconvert_to_graph_documents(documents)
LLM 그래프 트랜스포머의 응답은 다음과 같은 구조를 가진 그래프 문서이다:
[
GraphDocument(
nodes=[
Node(id="Marie Curie", type="Person", properties={}),
Node(id="Pierre Curie", type="Person", properties={}),
Node(id="Nobel Prize", type="Award", properties={}),
Node(id="University Of Paris", type="Organization", properties={}),
Node(id="Robin Williams", type="Person", properties={}),
],
relationships=[
Relationship(
source=Node(id="Marie Curie", type="Person", properties={}),
target=Node(id="Nobel Prize", type="Award", properties={}),
type="WON",
properties={},
),
Relationship(
source=Node(id="Marie Curie", type="Person", properties={}),
target=Node(id="Nobel Prize", type="Award", properties={}),
type="WON",
properties={},
),
Relationship(
source=Node(id="Marie Curie", type="Person", properties={}),
target=Node(
id="University Of Paris", type="Organization", properties={}
),
type="PROFESSOR",
properties={},
),
Relationship(
source=Node(id="Pierre Curie", type="Person", properties={}),
target=Node(id="Nobel Prize", type="Award", properties={}),
type="WON",
properties={},
),
],
source=Document(
metadata={"id": "de3c93515e135ac0e47ca82a4f9b82d8"},
page_content="\nMarie Curie, 7 November 1867 – 4 July 1934, was a Polish and naturalised-French physicist and chemist who conducted pioneering research on radioactivity.\nShe was the first woman to win a Nobel Prize, the first person to win a Nobel Prize twice, and the only person to win a Nobel Prize in two scientific fields.\nHer husband, Pierre Curie, was a co-winner of her first Nobel Prize, making them the first-ever married couple to win the Nobel Prize and launching the Curie family legacy of five Nobel Prizes.\nShe was, in 1906, the first woman to become a professor at the University of Paris.\nAlso, Robin Williams!\n",
),
)
]
그래프 문서는 추출된 노드와 관계를 설명하며, 원본 문서가 source 키 아래에 추가된다. Neo4j 브라우저를 사용해 출력 결과를 시각화하면 데이터를 보다 명확하고 직관적으로 이해할 수 있다.
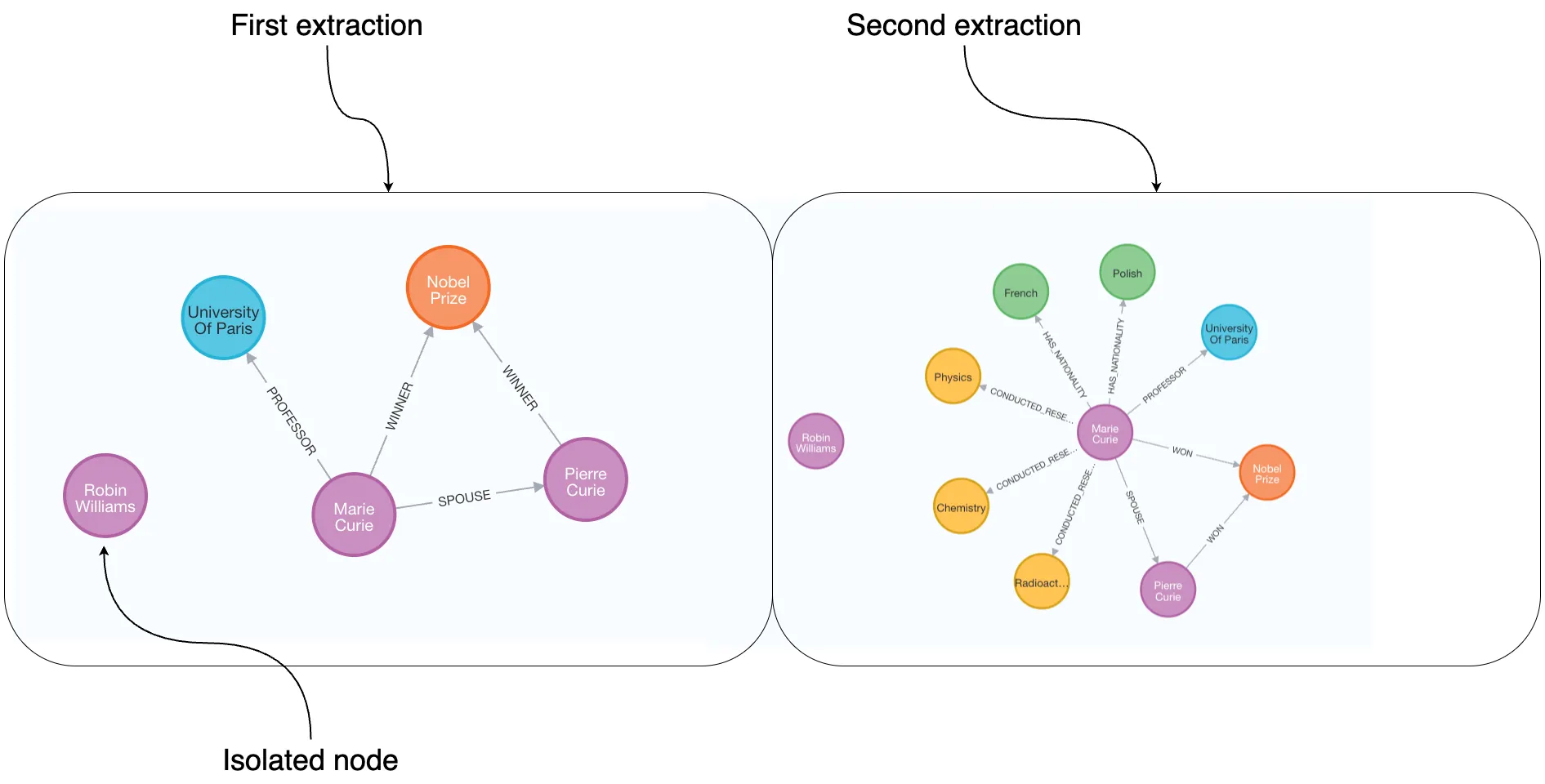
위 이미지는 Marie Curie에 관한 동일한 단락에서 두 번의 추출 결과를 보여준다. 이 경우 도구 기반 추출을 사용하는 GPT-4를 사용했으며, 이미지에서 보듯 고립된 노드를 허용한다. 그래프 스키마가 정의되지 않았기 때문에 LLM은 실행 시점에 추출할 정보를 결정해, 동일한 단락에서도 출력에 차이가 발생할 수 있다. 그 결과 일부 추출은 다른 것보다 더 상세하며, 동일 정보라도 구조가 다르게 나타날 수 있다. 예를 들어 왼쪽에서는 Marie가 노벨상 수상자로 표현되었고, 오른쪽에서는 그녀가 노벨상을 수상한 것으로 나타난다.
이제 프롬프트 기반 방식을 사용해 동일한 추출을 시도한다. 도구를 지원하는 모델에서는 ignore_tool_usage 파라미터를 설정해 프롬프트 기반 추출을 활성화할 수 있다.
no_schema_prompt = LLMGraphTransformer(llm=llm, ignore_tool_usage=True)
data = await no_schema.aconvert_to_graph_documents(documents)
다시 Neo4j 브라우저에서 두 번의 개별 실행 결과를 시각화할 수 있다.
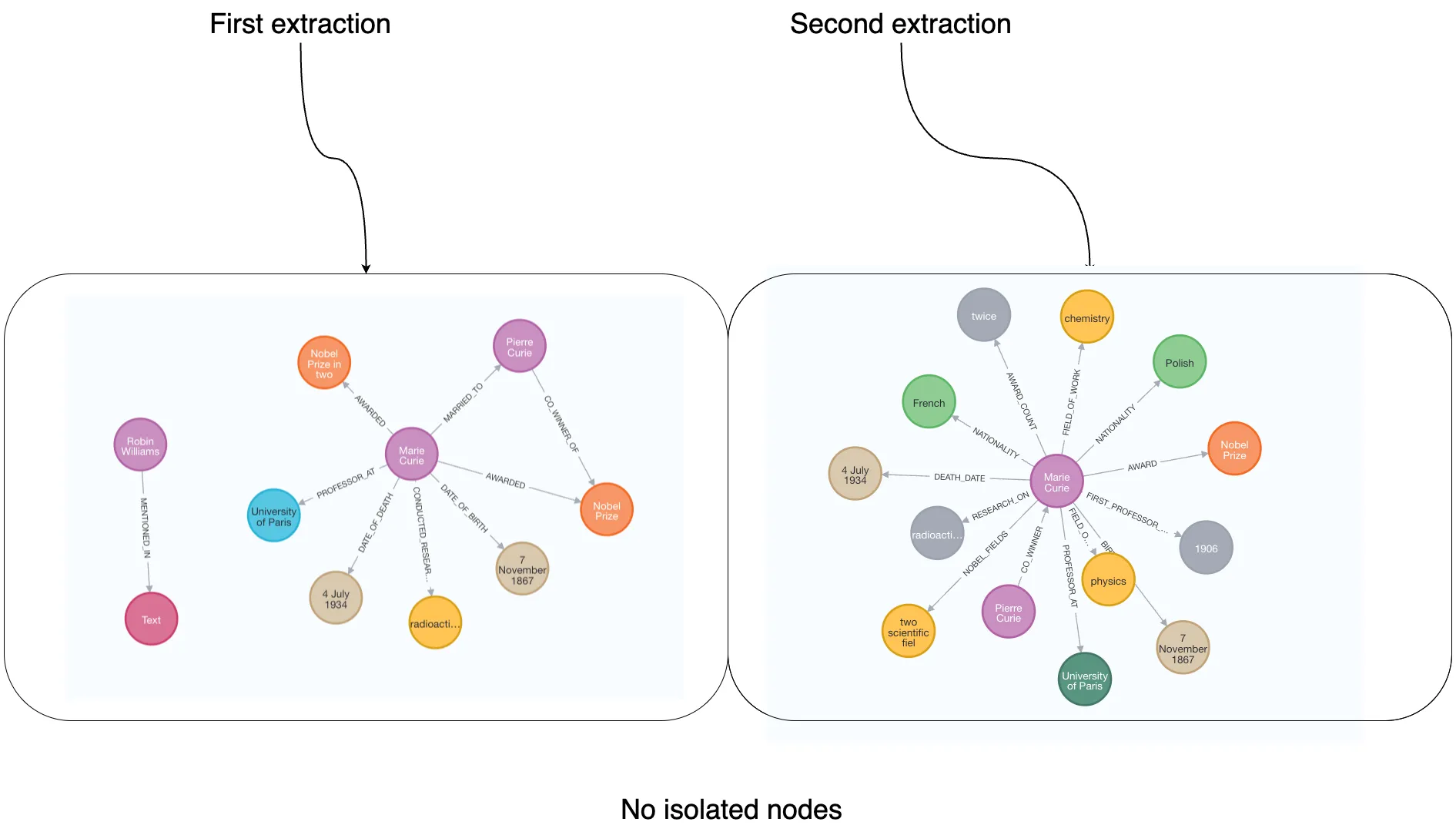
프롬프트 기반 방식에서는 고립된 노드가 생성되지 않으며, 이전 추출과 같이 스키마가 실행 간에 달라져 동일 입력에서도 다른 출력이 발생할 수 있다.
다음으로 그래프 스키마 정의가 보다 일관된 출력 결과 도출에 어떻게 도움이 되는지 살펴본다.
허용 노드 정의
추출된 그래프 구조를 제한하면 모델이 특정 관련 개체와 관계에 집중하도록 유도할 수 있다. 명확한 스키마를 정의하면 추출 간 일관성이 개선되어 출력이 보다 예측 가능하고 필요한 정보와 일치하게 된다. 이는 실행 간 변동성을 줄이고, 추출된 데이터가 표준화된 구조를 따르도록 보장한다. 잘 정의된 스키마를 사용하면 모델이 주요 세부 사항을 누락하거나 예상치 못한 요소를 추가할 가능성이 줄어들어, 더 깔끔하고 사용하기 좋은 그래프를 생성할 수 있다.
allowed_nodes 파라미터를 사용해 추출할 예상 노드 타입을 정의하는 것으로 시작한다.
allowed_nodes = ["Person", "Organization", "Location", "Award", "ResearchField"]
nodes_defined = LLMGraphTransformer(llm=llm, allowed_nodes=allowed_nodes)
data = await allowed_nodes.aconvert_to_graph_documents(documents)
여기서는 LLM이 Person, Organization, Location, Award, ResearchField 등 다섯 가지 노드 타입을 추출하도록 정의했다. 비교를 위해 Neo4j 브라우저에서 두 번의 개별 실행 결과를 시각화한다.
예상 노드 타입을 지정함으로써 보다 일관된 노드 추출을 달성할 수 있다. 다만, 실행 간 일부 변동이 발생할 수 있다. 예를 들어 첫 번째 실행에서는 “radioactivity”가 연구 분야로 추출되었으나 두 번째 실행에서는 그렇지 않았다.
관계가 정의되지 않았으므로 관계 타입도 실행 간에 달라질 수 있으며, 일부 추출은 다른 것보다 더 많은 정보를 포함할 수 있다. 예를 들어, Marie와 Pierre 사이의 MARRIED_TO 관계는 두 추출 모두에 나타나지 않을 수 있다.
허용 관계 정의
노드 타입만 정의하는 것으로는 관계 추출에 변동성이 남는다. 이를 해결하기 위해 관계도 정의하는 방법을 살펴본다. 첫 번째 방법은 사용 가능한 타입 목록을 이용해 허용 관계를 지정하는 것이다.
allowed_nodes = ["Person", "Organization", "Location", "Award", "ResearchField"]
allowed_relationships = ["SPOUSE", "AWARD", "FIELD_OF_RESEARCH", "WORKS_AT", "IN_LOCATION"]
rels_defined = LLMGraphTransformer(
llm=llm,
allowed_nodes=allowed_nodes,
allowed_relationships=allowed_relationships
)
data = await rels_defined.aconvert_to_graph_documents(documents)
다시 한 번 두 번의 개별 추출 결과를 살펴본다.
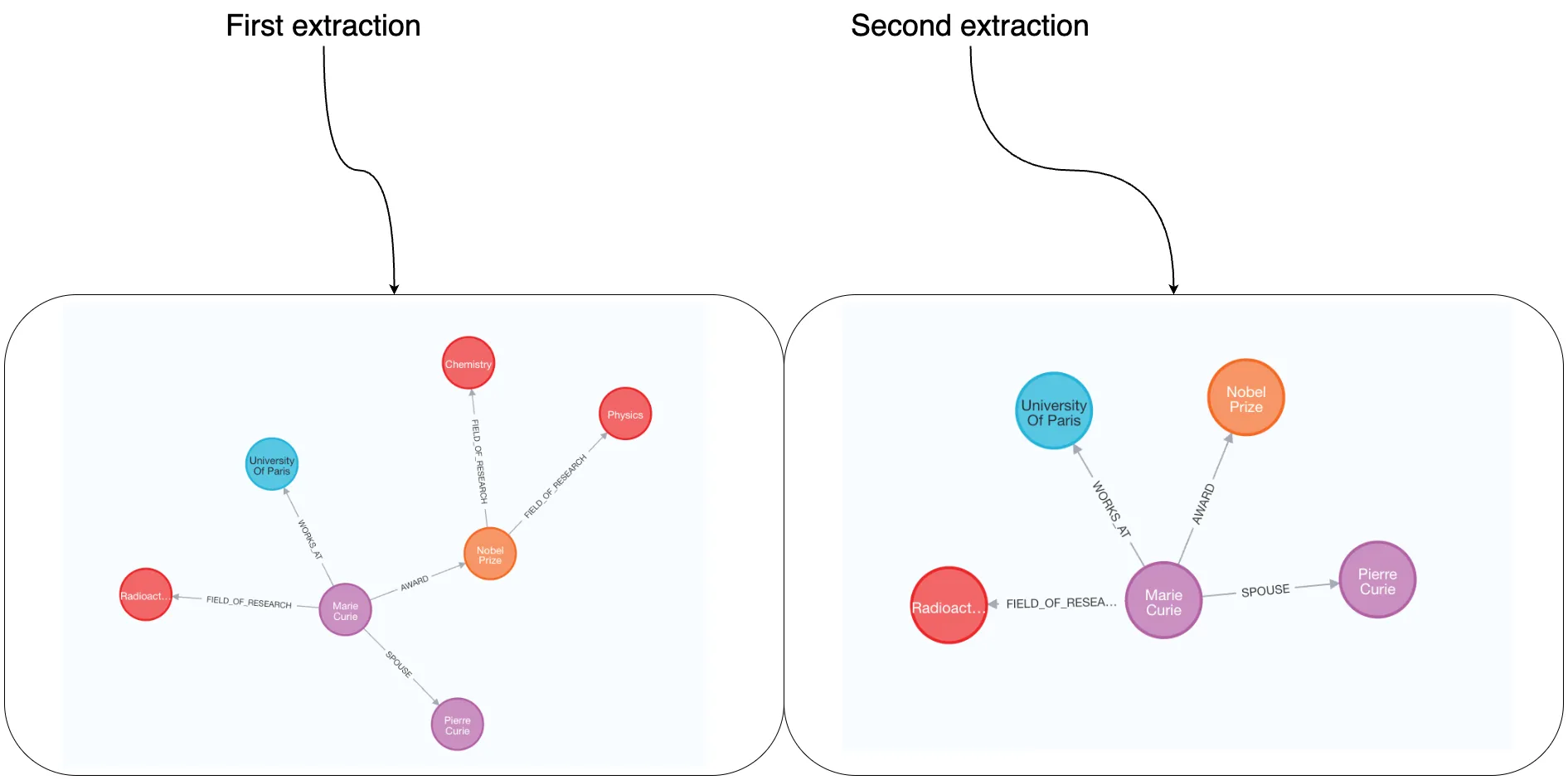
노드와 관계가 모두 정의되면 출력 결과가 훨씬 더 일관된다. 예를 들어, Marie는 항상 상을 수상하고, Pierre의 배우자이며, 파리 대학교에서 근무하는 것으로 나타난다. 다만, 관계가 연결할 수 있는 노드에 대한 제한 없이 일반 목록으로 지정되었기 때문에 여전히 변동이 발생한다. 예를 들어, FIELD_OF_RESEARCH 관계가 Person과 ResearchField 사이에 나타날 수도 있지만, 때로는 Award와 ResearchField를 연결하기도 한다. 또한 관계 방향이 정의되지 않았기 때문에 방향 일관성에 차이가 있을 수 있다.
관계가 연결할 수 있는 노드를 지정하고 관계 방향을 강제하기 위해 아래와 같이 세 개의 요소를 가진 튜플 형식으로 관계를 정의하는 새로운 옵션을 도입했다.
allowed_nodes = ["Person", "Organization", "Location", "Award", "ResearchField"]
allowed_relationships = [
("Person", "SPOUSE", "Person"),
("Person", "AWARD", "Award"),
("Person", "WORKS_AT", "Organization"),
("Organization", "IN_LOCATION", "Location"),
("Person", "FIELD_OF_RESEARCH", "ResearchField")
]
rels_defined = LLMGraphTransformer(
llm=llm,
allowed_nodes=allowed_nodes,
allowed_relationships=allowed_relationships
)
data = await rels_defined.aconvert_to_graph_documents(documents)
이 방식은 관계를 단순한 문자열 목록으로 정의하는 대신, 각 튜플이 소스 노드, 관계 타입, 타깃 노드를 순서대로 나타내게 한다. 결과를 다시 시각화해본다.
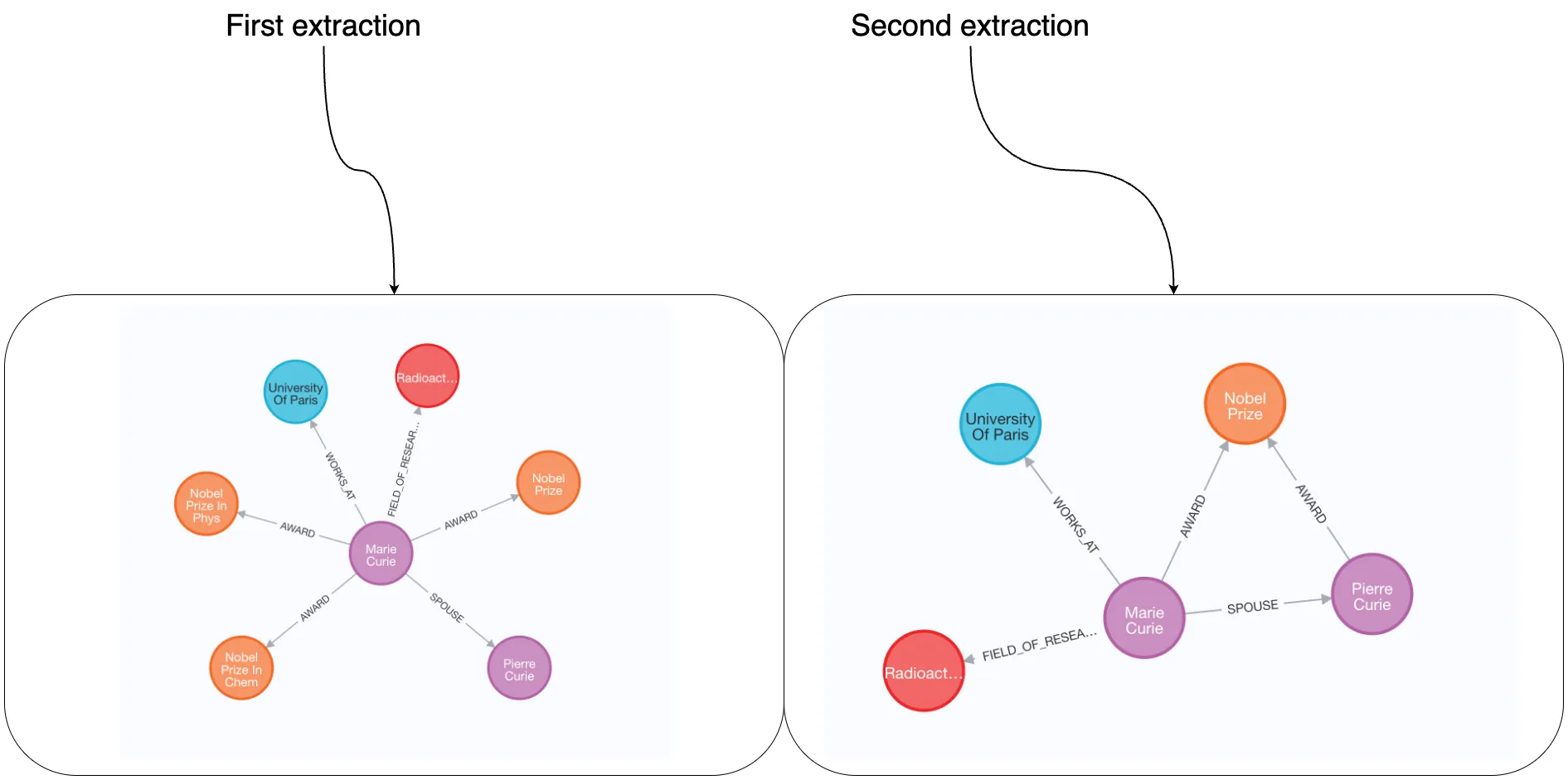
세 개의 튜플 방식을 사용하면 여러 실행에 걸쳐 추출된 그래프에 대해 훨씬 더 일관된 스키마를 제공한다. 다만, LLM의 특성상 추출된 상세 정보 수준에는 여전히 차이가 있을 수 있다. 예를 들어 오른쪽에서는 Pierre가 노벨상을 수상한 것으로 나타나지만, 왼쪽에서는 해당 정보가 누락될 수 있다.
속성 정의
그래프 스키마에 대해 할 수 있는 마지막 개선 사항은 노드와 관계의 속성을 정의하는 것이다. 여기에는 두 가지 옵션이 있다. 첫 번째 옵션은 node_properties 또는 relationship_properties를 True로 설정해 LLM이 추출할 속성을 자율적으로 결정하도록 하는 것이다.
allowed_nodes = ["Person", "Organization", "Location", "Award", "ResearchField"]
allowed_relationships = [
("Person", "SPOUSE", "Person"),
("Person", "AWARD", "Award"),
("Person", "WORKS_AT", "Organization"),
("Organization", "IN_LOCATION", "Location"),
("Person", "FIELD_OF_RESEARCH", "ResearchField")
]
node_properties=True
relationship_properties=True
props_defined = LLMGraphTransformer(
llm=llm,
allowed_nodes=allowed_nodes,
allowed_relationships=allowed_relationships,
node_properties=node_properties,
relationship_properties=relationship_properties
)
data = await props_defined.aconvert_to_graph_documents(documents)
graph.add_graph_documents(data)
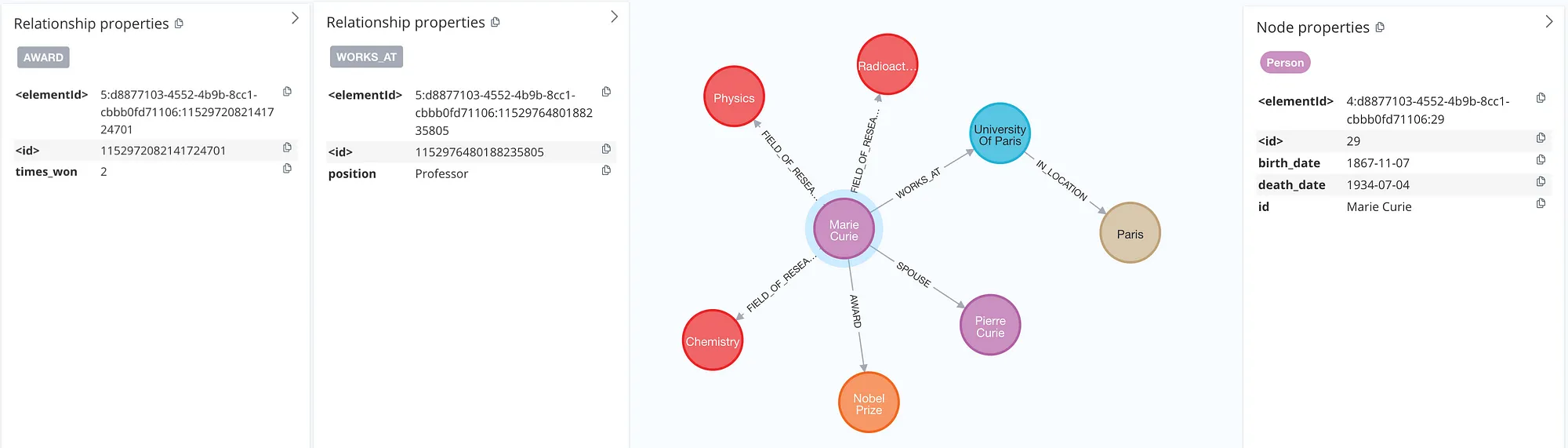
결과를 살펴보면, LLM이 관련 있다고 판단되는 노드와 관계의 속성을 추가하도록 허용되었다. 예를 들어, Marie Curie의 출생 및 사망 날짜, 파리 대학교 교수로서의 역할, 두 번의 노벨상 수상 사실 등이 포함되었다. 이러한 추가 속성은 추출된 정보를 크게 풍부하게 만든다.
두 번째 옵션은 추출할 노드와 관계의 속성을 직접 리스트로 정의하는 것이다.
allowed_nodes = ["Person", "Organization", "Location", "Award", "ResearchField"]
allowed_relationships = [
("Person", "SPOUSE", "Person"),
("Person", "AWARD", "Award"),
("Person", "WORKS_AT", "Organization"),
("Organization", "IN_LOCATION", "Location"),
("Person", "FIELD_OF_RESEARCH", "ResearchField")
]
node_properties=["birth_date", "death_date"]
relationship_properties=["start_date"]
props_defined = LLMGraphTransformer(
llm=llm,
allowed_nodes=allowed_nodes,
allowed_relationships=allowed_relationships,
node_properties=node_properties,
relationship_properties=relationship_properties
)
data = await props_defined.aconvert_to_graph_documents(documents)
graph.add_graph_documents(data)
속성은 단순히 두 개의 리스트로 정의된다. LLM이 추출한 결과를 살펴보면, 출생 및 사망 날짜는 이전 추출과 일치하며 이번에는 Marie가 파리 대학교에서 교수로 임용된 시작 날짜도 추출되었다.
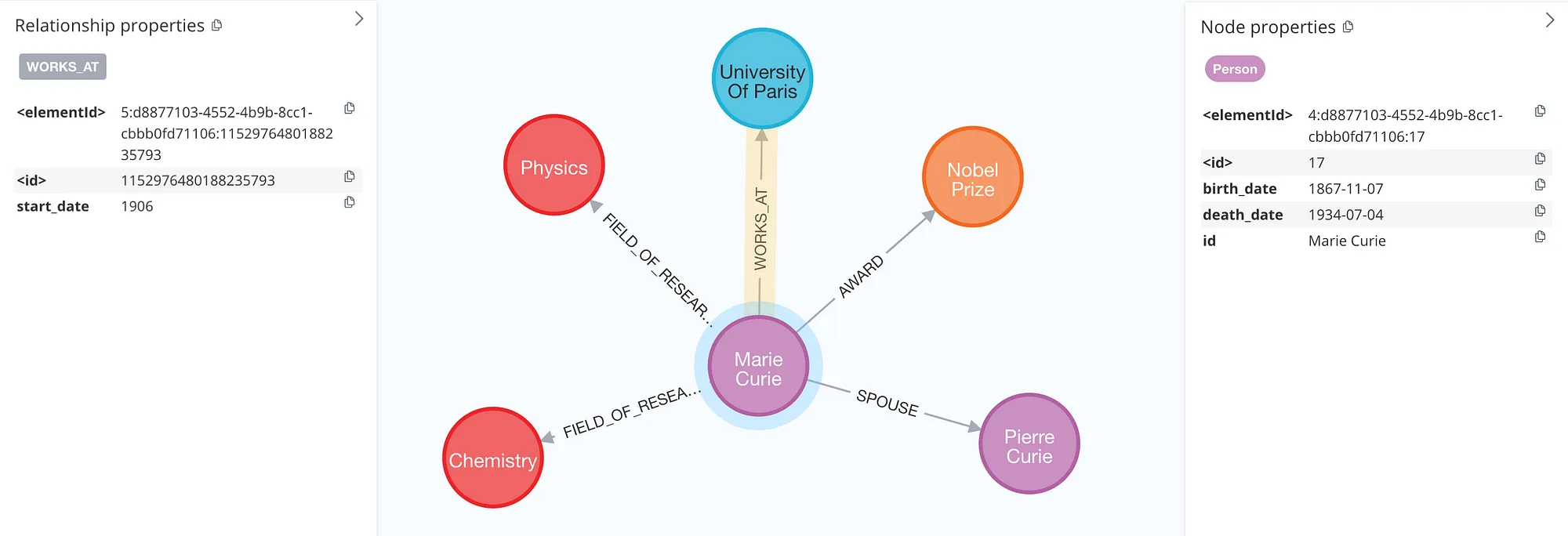
속성은 추출된 정보에 가치 있는 깊이를 추가하지만, 현재 구현에는 다음과 같은 한계가 있다:
- 속성은 도구 기반 방식으로만 추출할 수 있다.
- 모든 속성은 문자열로 추출된다.
- 속성은 노드 레이블이나 관계 타입별로 개별적으로 정의할 수 없고 전역적으로만 정의된다.
- 보다 정밀한 추출을 위한 속성 설명을 커스터마이즈할 옵션이 없다.
엄격 모드
LLM이 정의된 스키마를 완벽하게 따르게 만드는 방법을 완벽하게 구현했다고 생각하더라도, 프롬프트 엔지니어링에 상당한 노력을 기울였음에도 불구하고 특히 성능이 떨어지는 LLM이 지시사항을 완벽하게 준수하도록 만드는 것은 어렵다. 이를 해결하기 위해 후처리 단계인 strict_mode를 도입해, 정의된 그래프 스키마에 부합하지 않는 모든 정보를 제거하여 더 깔끔하고 일관된 결과를 보장한다.
기본적으로 strict_mode는 True로 설정되어 있으나, 다음 코드를 통해 비활성화할 수 있다.
LLMGraphTransformer(
llm=llm,
allowed_nodes=allowed_nodes,
allowed_relationships=allowed_relationships,
strict_mode=False
)
엄격 모드를 끄면, LLM이 출력 구조에 대해 창의적 자유를 행사할 수 있어 정의된 그래프 스키마 외의 노드나 관계 타입이 나타날 수 있다.
그래프 문서를 그래프 데이터베이스에 가져오기
LLM 그래프 트랜스포머로 추출한 그래프 문서는 add_graph_documents 메소드를 사용해 Neo4j와 같은 그래프 데이터베이스로 가져와 추가 분석이나 애플리케이션에 활용할 수 있다. 다양한 사용 사례에 맞춰 데이터를 가져오는 여러 옵션을 살펴본다.
기본 가져오기
다음 코드를 사용해 노드와 관계를 Neo4j로 가져올 수 있다.
graph.add_graph_documents(graph_documents)
이 메소드는 제공된 그래프 문서의 모든 노드와 관계를 그대로 가져온다. 이 방식은 본 포스트 전반에 걸쳐 다양한 LLM 및 스키마 구성 결과를 검토하는 데 사용되었다.
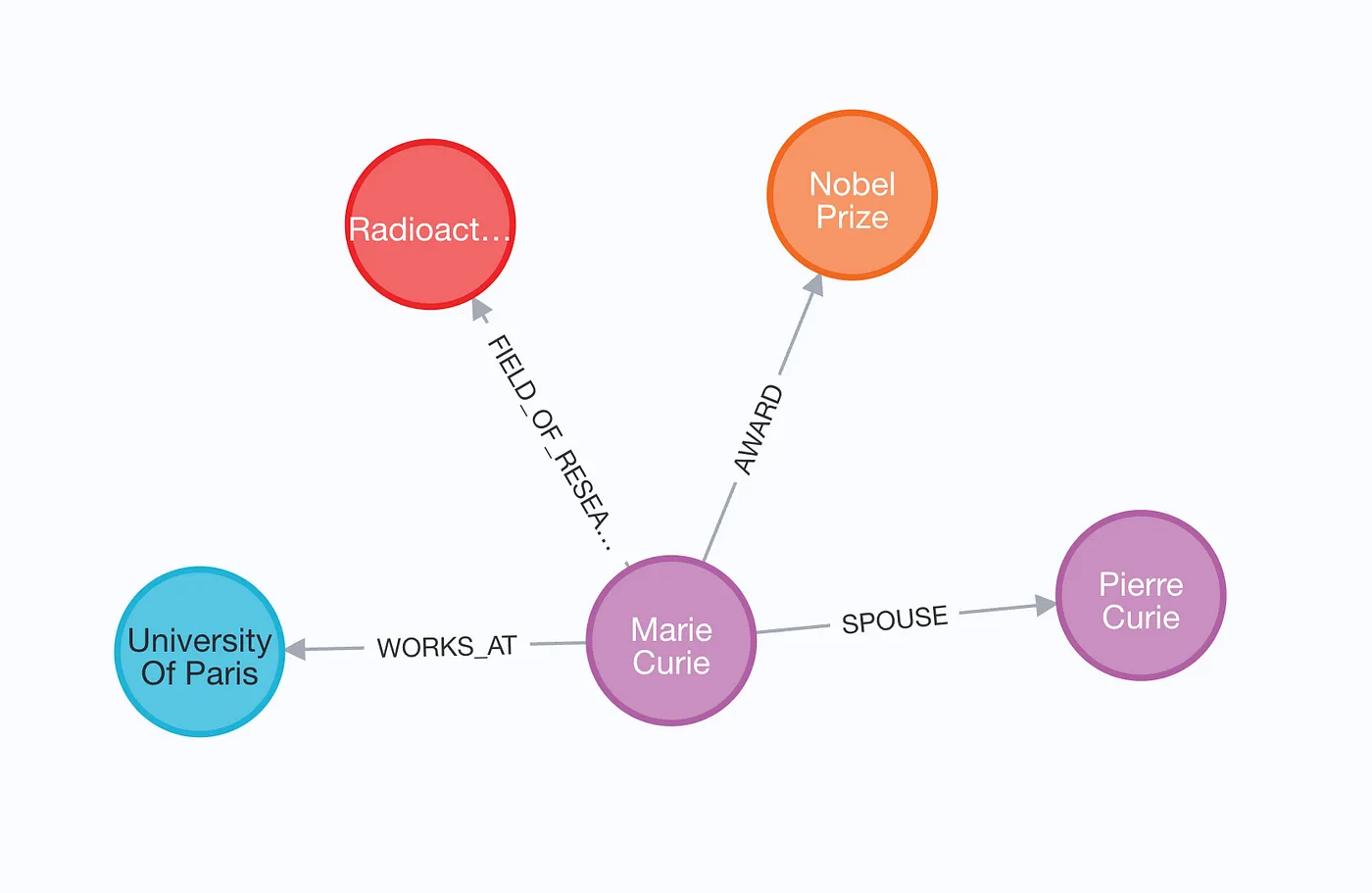
기본 엔터티 레이블
대부분의 그래프 데이터베이스는 데이터 가져오기와 검색 최적화를 위해 인덱스를 지원한다. Neo4j에서는 특정 노드 레이블에 대해서만 인덱스를 설정할 수 있다. 모든 노드 레이블을 미리 알 수 없으므로, baseEntityLabel 파라미터를 사용해 각 노드에 보조 기본 레이블을 추가하면, 그래프 내 모든 가능한 노드 레이블에 대해 인덱스를 만들지 않고도 인덱싱을 활용해 효율적인 가져오기와 검색이 가능하다.
graph.add_graph_documents(graph_documents, baseEntityLabel=True)
앞서 언급한 바와 같이, baseEntityLabel 파라미터를 사용하면 각 노드에 추가로 Entity 레이블이 부여된다.
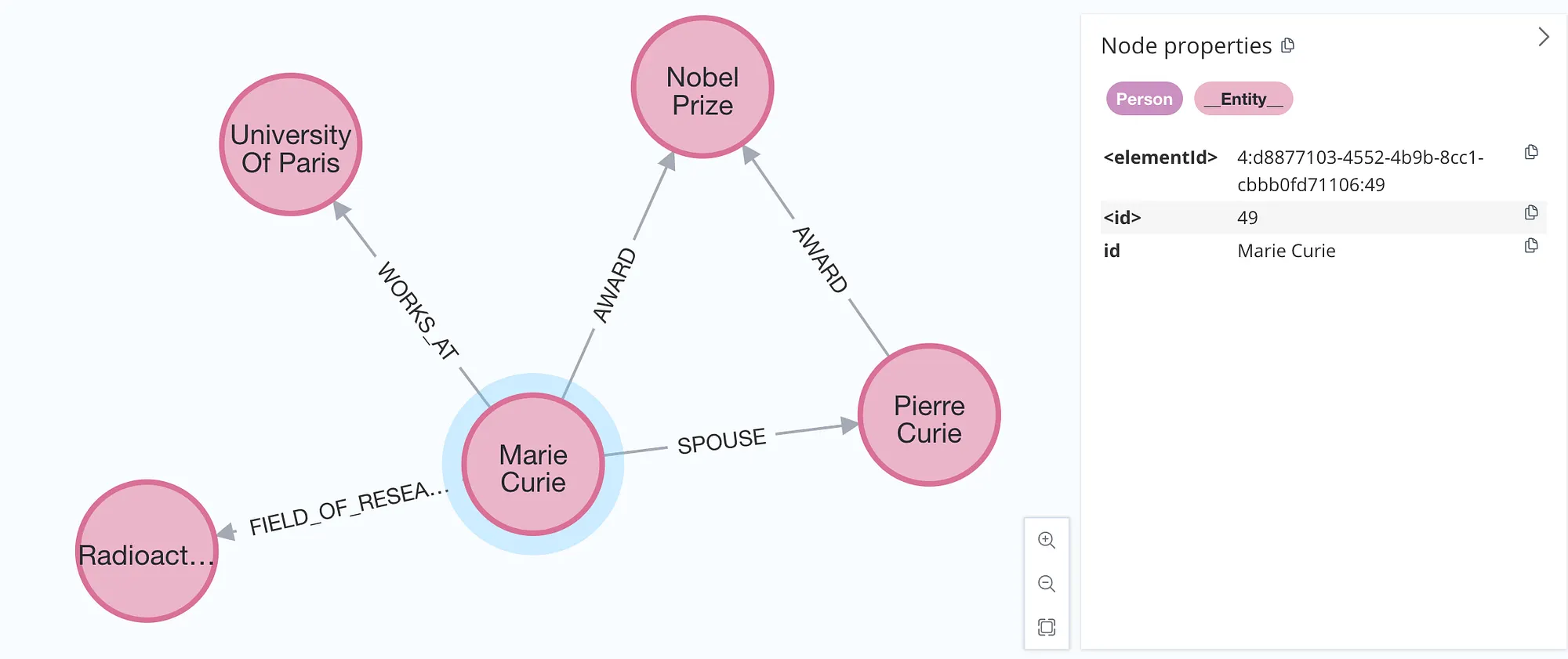
원본 문서 포함
마지막 옵션은 추출된 노드와 관계의 원본 문서를 함께 가져오는 것이다. 이 방법은 각 개체가 어떤 문서에서 추출되었는지 추적할 수 있게 해준다. include_source 파라미터를 사용해 원본 문서를 가져올 수 있다.
graph.add_graph_documents(graph_documents, include_source=True)
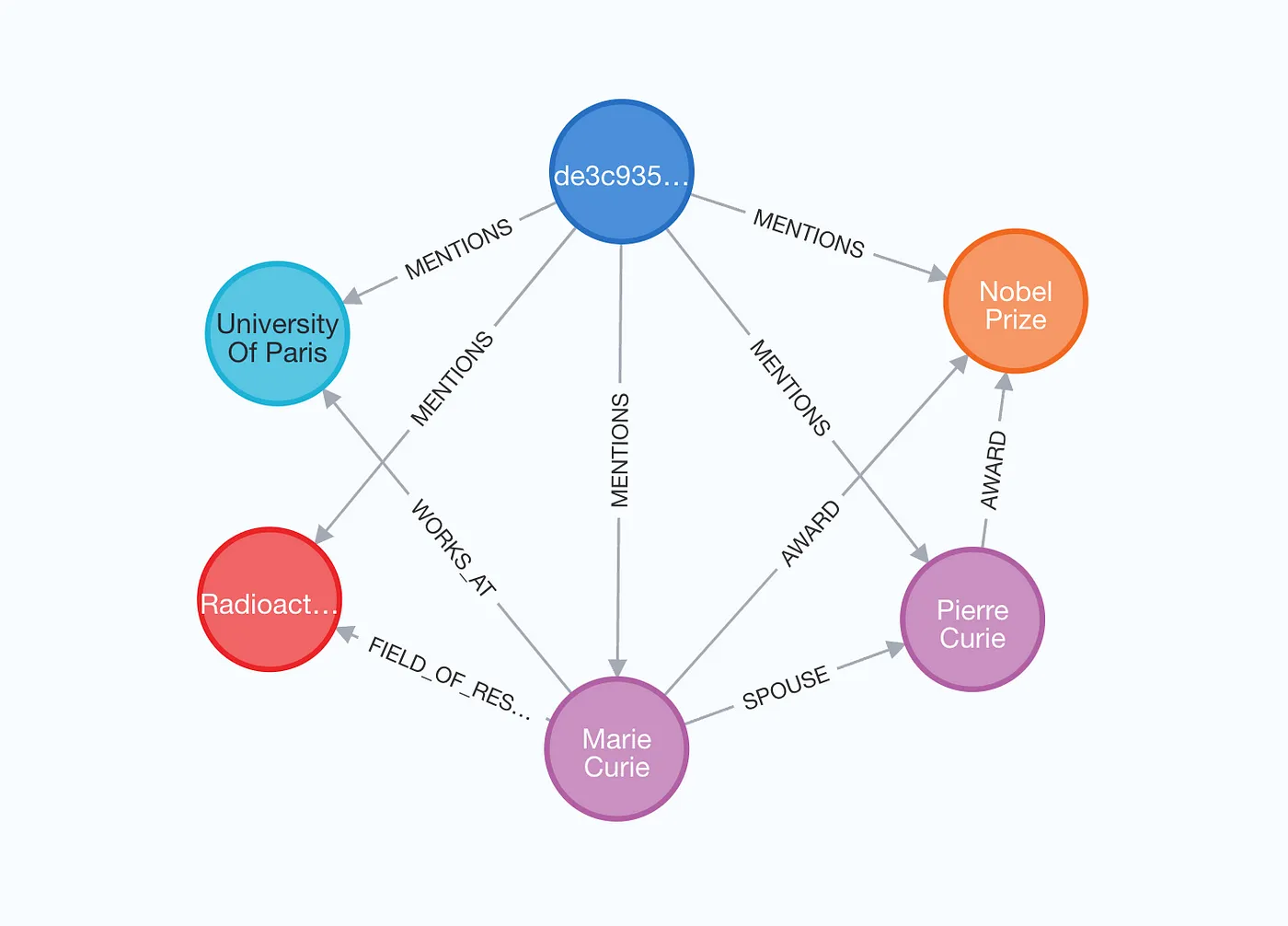
가져온 그래프를 확인하면, 원본 문서가 파란색으로 강조되고, 그 문서에서 추출된 모든 개체가 MENTIONS 관계로 연결된 결과를 확인할 수 있다. 이 모드는 구조화된 검색과 비구조화된 검색 방식을 모두 활용하는 검색기를 구축할 수 있게 한다.
요약
이 포스트에서는 LangChain의 LLM 그래프 트랜스포머와 텍스트로부터 지식 그래프를 구축하는 두 가지 모드를 살펴봤다. 주된 방식인 도구 기반 모드는 구조화된 출력과 함수 호출을 활용해 프롬프트 엔지니어링을 줄이고 속성 추출을 가능하게 한다. 반면 프롬프트 기반 모드는 도구 사용이 불가능할 때 유용하며 few-shot 예시로 LLM을 안내한다. 다만, 프롬프트 기반 추출은 속성 추출을 지원하지 않으며 고립된 노드도 생성하지 않는다.
명확한 그래프 스키마, 즉 허용 노드와 관계 타입을 정의하면 추출의 일관성과 성능이 개선됨을 확인했다. 제한된 스키마는 출력이 원하는 구조를 따르도록 보장해 보다 예측 가능하고 신뢰할 수 있으며 적용 가능하게 만든다. 도구 기반이든 프롬프트 기반이든, LLM 그래프 트랜스포머는 비정형 데이터를 보다 조직적이고 구조화된 형태로 표현해 RAG 애플리케이션과 다단계 쿼리 처리에 도움을 준다.
코드는 GitHub에서 확인할 수 있다. 또한 Neo4j가 제공하는 호스팅된 LLM Graph Builder 애플리케이션을 사용해 노코드 환경에서 LLM 그래프 트랜스포머를 체험할 수도 있다.