A Path Towards Autonomous Machine Intelligence: Exploring Hierachical Predictive Architectures
자율 기계 지능을 향한 길: 계층적 예측 아키텍처 탐구
서론
이 글은 “자율 기계 지능을 향한 길” 연구 논문에 제시된 개념에 대한 광범위하고 비기술적인 개요를 제공한다. 기술적인 세부 사항은 관심 있는 독자가 추가적으로 탐구하도록 남겨둔다. 이 논문은 메타의 수석 AI 과학자인 얀 르쿤이 인간과 동물처럼 학습하고 추론하며 계획할 수 있는 지능형 기계를 개발하기 위한 아키텍처와 훈련 패러다임을 제안하는 흥미로운 논문이다.
인간과 유사한 기계 지능 달성의 과제
르쿤은 인간과 유사한 기계 지능을 달성하기 위해 해결해야 할 인공지능(AI) 연구의 세 가지 주요 과제를 제시한다. 첫째, 기계는 인간과 동물만큼 효율적으로 학습하기 위해 세계 모델을 어떻게 사용할 수 있는가? 둘째, 기계는 기울기 기반 학습과 호환되는 방식으로 어떻게 추론하고 계획할 수 있는가? 셋째, 기계는 여러 추상화 수준과 여러 시간 척도로 지각과 행동 계획을 나타내는 방법을 어떻게 학습할 수 있는가?
제안된 아키텍처
이러한 과제를 해결하기 위해 르쿤은 지능적인 행동을 생성하기 위해 함께 작동하는 여러 모듈로 구성된 그림 1의 인지 아키텍처를 제안한다. 모든 모듈은 미분 가능하며 많은 모듈이 기울기 기반 학습을 통해 훈련 가능하다. 각 모듈의 기능에 대한 간략한 요약은 다음과 같다.
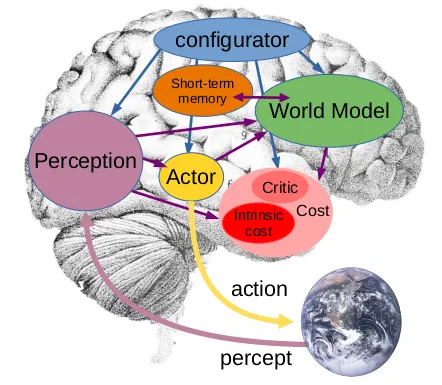
그림 1
- 설정기(Configurator): 다른 모듈의 활동을 조정하는 실행 제어를 수행한다.
- 지각(Perception): 지각 입력을 사용하여 현재 세계 상태를 추정한다.
- 세계 모델(World Model): 세계가 어떻게 작동하는지에 대한 내부 모델이다. 액터 모듈이 제안한 상상된 행동 시퀀스의 함수로 가능한 미래 세계 상태를 예측한다.
- 비평가(Critic): 에이전트의 불쾌감 수준을 측정하는 “에너지”라는 단일 스칼라 출력을 계산한다. 에너지를 줄이거나 불쾌감을 줄이는 것이 에이전트의 행동 동기가 된다. 동물 세계에서 이것은 동물이 배고픔, 두려움, 고통 등을 줄이려고 하는 것으로 생각할 수 있다.
- 단기 기억(Short-term memory): 현재 및 예측된 세계 상태를 추적한다.
- 액터(Actor): 미래 에너지/불쾌감을 최소화하는 최적의 행동 시퀀스를 찾고 행동을 출력한다.
세계 모델 학습
르쿤이 강조하는 중요한 측면 중 하나는 기계가 세계 모델을 학습하는 것의 중요성이다. 세계 모델은 세계가 어떻게 작동하는지에 대한 내부 표현이다. 이를 통해 동물과 인간은 이전 경험에서 배운 것을 일반화하여 적은 시행착오로 새로운 기술을 학습할 수 있다. 르쿤은 기계가 비지도 또는 자기 지도 방식으로 세계 모델을 학습하고 이러한 모델을 사용하여 예측, 추론 및 계획해야 한다고 제안한다. 인간의 상식은 강력한 세계 모델을 가진 것의 표현으로 생각할 수 있다.
모델의 계층 구조
인간과 동물은 기본 지식을 빠르게 습득하고 그 위에 더 추상적인 개념을 구축하는 모델의 계층 구조를 학습한다. 르쿤은 동물과 인간의 전두엽에 다양한 작업에 대해 동적으로 구성 가능한 단일 세계 모델 엔진을 가지고 있다고 제안한다. 이를 통해 작업 간에 지식을 공유하고 유추를 통해 추론할 수 있다. 기계가 더 높은 수준의 일반 지능을 나타내려면 이러한 계층적 모델을 모방해야 한다.
계층적 예측 아키텍처(HPAs)
이 논문의 핵심은 공동 임베딩 예측 아키텍처(JEPA)이다. 논문에는 많은 세부 사항이 제공되지만 여기서는 생략하고 다음 블로그 게시물에서 요약하려고 노력할 것이다. JEPA 아키텍처는 인코딩 과정을 통해 세계의 표현을 생성하고 이러한 표현 간의 관계를 학습한다. 학습된 관계는 현재 상태와 미래 상태 간의 관계일 수 있다. 표현을 사용하면 모델이 관련 없는 세부 사항을 추상화할 수 있으므로 모델이 기본 관계를 더 쉽게 학습하고 훨씬 더 높은 수준의 일반화를 허용한다.
“일반적인 JEPA는 그림 2에 나와 있다. 두 변수 x와 y는 두 개의 인코더에 입력되어 표현 Sx와 Sy를 생성한다. 이 두 인코더는 다를 수 있다. 동일한 아키텍처를 가질 필요도 없고 매개변수를 공유할 필요도 없다. 이를 통해 x와 y는 본질적으로 다를 수 있다(예: 비디오와 오디오).” (LeCun, 2022).
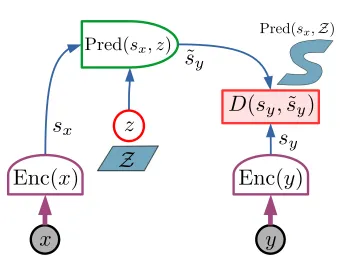
그림 2
JEPA의 확장 버전은 여러 시간 척도와 여러 추상화 수준에서 예측할 수 있는 계층적 JEPA(H-JEPA)이다. “직관적으로 낮은 수준의 표현은 입력에 대한 많은 세부 정보를 포함하며 단기적으로 예측하는 데 사용할 수 있다. 그러나 동일한 수준의 세부 정보로 정확한 장기 예측을 생성하는 것은 어려울 수 있다. 반대로 높은 수준의 추상적 표현은 많은 세부 정보를 제거하는 대신 장기 예측을 가능하게 할 수 있다.” (LeCun, 2022). 이러한 다중 수준의 세계 상태 및 행동 표현을 통해 복잡한 작업을 점차적으로 더 자세한 하위 작업으로 분해할 수 있다.
모드 1: 반응적 행동
에이전트는 두 가지 행동 모드를 보인다. 모드 1에서 에이전트는 지각과 아마도 단기 기억을 기반으로 직접 행동을 생성한다. 이 반응적 행동은 복잡한 추론이나 계획을 포함하지 않는다. 액터의 구성 요소인 정책 모듈은 추가 정보를 위해 단기 기억에 접근할 수 있는 순수한 반응적 정책을 구현한다.
모드 2: 추론 및 계획
모드 2에서 에이전트는 세계 모델과 비용 모듈을 사용하여 추론과 계획에 참여한다. 지각 모듈은 현재 세계 상태를 추정하고 액터는 초기 행동 시퀀스를 제안한다. 세계 모델은 제안된 행동 시퀀스를 기반으로 가능한 미래 상태를 예측하고 비용 모듈은 예측된 상태와 관련된 총 비용을 추정한다. 그런 다음 액터는 기울기 기반 방법을 사용하여 추정된 비용을 최소화하도록 행동 시퀀스를 최적화한다.
모드 2에서 모드 1로: 새로운 기술 학습
추론 과정을 보다 효율적으로 만들기 위해 에이전트는 모드 2 추론에서 비롯된 최적의 행동을 근사화하도록 정책 모듈을 훈련할 수 있다. 그런 다음 이 훈련된 정책 모듈을 모드 1에서 사용하여 복잡한 계획 없이 직접 행동을 생성할 수 있다. 이 과정을 통해 에이전트는 반응적 정책 모듈로 컴파일된 새로운 기술을 습득할 수 있다.
결론
“자율 기계 지능을 향한 길” 연구 논문은 기계가 인간과 유사한 행동을 모방하는 방법을 학습할 수 있는 모델 아키텍처를 제시한다. 제안된 구조는 인간의 뇌가 작동한다고 생각되는 방식에서 많은 영감을 얻은 것으로 보인다. 계층적 예측 아키텍처와 같은 제안의 일부 측면은 구현 가능한 것으로 보이며 실제로 이 아키텍처를 테스트하는 논문의 요약을 후속 조치할 것이다. 이 논문은 전체 아키텍처를 어떻게 구현할 수 있는지에 대해서는 덜 명확하며 르쿤이 미래 연구자들이 기여할 수 있기를 바라는 부분이라고 생각한다.