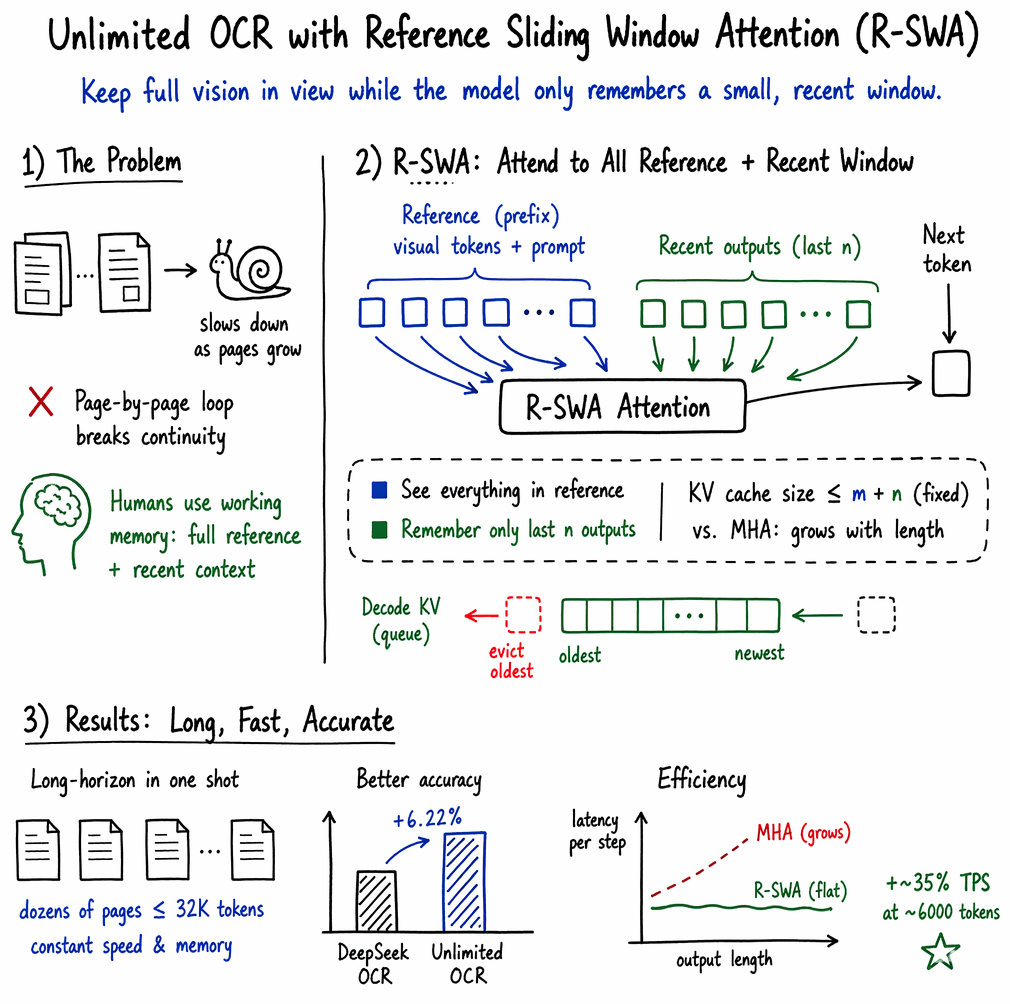
LLM을 디코더로 쓰는 종단간(end-to-end) OCR 모델은 언어의 사전 분포를 활용해 정확도를 높인다. 그러나 출력 시퀀스가 길어질수록 누적된 KV 캐시가 메모리를 끌어올리고 생성을 점점 느리게 만든다. 장기 필사에서 효율이 떨어지지 않는 사람과는 정반대다. Unlimited OCR은 사람의 파싱 작업 기억을 모방해, 디코더의 모든 어텐션을 참조 슬라이딩 윈도우 어텐션(R-SWA)으로 교체하고 디코딩 내내 KV 캐시를 일정하게 유지한다.
사람은 수백 페이지의 책을 옮겨 적고, 몇 시간짜리 음성을 번역하는 장기(long-horizon) 작업에 놀랍도록 능하다. 그런데 바로 이런 작업에서 현재 모델은 무너진다. OCR을 예로 들면, 어떤 기존 모델도 한 번의 forward pass로 열 페이지조차 파싱하지 못한다.
대신 모델은 페이지마다 메모리를 초기화하는 for-loop 방식으로 한 페이지씩 처리한다. 이 차이는 단순한 문맥 부족의 문제가 아니다. 사람은 먼 출력은 기억에서 부드럽게 흐려지되 가까운 문맥으로 진행 상황을 추적하는 연속적 인지 상태를 유지한다. 반면 for-loop는 매 페이지에서 메모리를 완전히 지워, 일관된 장기 과정을 외부 스케줄러가 관리하는 고립된 단기 작업으로 파편화한다. 어느 정도 작동하지만 이는 공학적 우회일 뿐 AGI를 향한 한 걸음이 아니다.
문서를 옮겨 적는 행위를 떠올려 보면, 글자 하나를 베낄 때 이미 쓴 전체 텍스트를 훑지 않는다. 방향을 유지하려고 바로 주변 문맥만 흘긋 본다. 이 일상적 행동은 현재 모델과 근본적으로 다른 어텐션 패턴을 가리킨다. 전체 이력을 다 참조하지 않으니 표준 풀 어텐션이 아니고, 시각·참조 토큰이 순환적 상태 갱신을 겪지 않으니 선형 어텐션도 아니다. 그런 갱신은 시각 특징을 점점 흐리게 해 인식 정확도를 떨어뜨릴 것이다.
사람이 손으로 책을 베낄 때 주의는 보통 세 지점에 모인다. 이미 옮긴 모든 것을 완전히 기억하기보다 일종의 부드러운 망각(soft forgetting)에 의존하며, 이것이 낮은 인지 부하로 장기 파싱을 지속하는 열쇠일 수 있다.
옮겨 적을 원본 소스. OCR에서는 시각 토큰 전체에 해당한다. 어디를 읽는지(know-what) 안다.
막 쓴 소량(보통 몇 글자)의 최근 문맥. 어디까지 진행했는지(know-where)를 추적한다.
이제 막 쓸 다음 글자. 인과적 슬라이딩 윈도우 안의 상태 전이로 진행을 이어 간다.
Unlimited OCR은 DeepSeek OCR을 베이스라인으로 채택한다. DeepEncoder와, 총 3B·활성 500M 파라미터의 혼합전문가(MoE) 구조로 이루어진다. 원본 DeepSeek OCR과 달리 표준 다중헤드 어텐션(MHA)을 R-SWA로 교체한다.
DeepEncoder는 SAM-ViT와 CLIP-ViT를 직렬 연결하고 다리(bridge)에서 16× 토큰 압축을 적용한다. 앞 절반은 윈도우 어텐션으로 원본 이미지 토큰을 처리하고, 전역 어텐션은 압축된 토큰에만 쓴다. 이 설계는 고해상도 이미지를 인코딩할 때 활성값을 낮게 유지해 GPU 메모리를 아낀다. DeepEncoder는 다섯 해상도 모드를 지원하나 두 가지를 쓴다. 다중 페이지용 "Base" 모드(1024×1024)와 단일 페이지용 "Gundam"(동적 해상도)이다. 구체적으로 1024×1024 PDF 이미지를 단 256 토큰으로 압축한다.
이 높은 압축률이 Unlimited OCR에 결정적인 이유는, 시각 토큰이 출력과 함께 상태 전이를 겪지 않기 때문이다. 시각 토큰은 한 번 인코딩되면 장기 파싱 전 과정 동안 정적으로 유지된다.
R-SWA는 본질적으로 어텐션을 크기 m+n의 두 구간 윈도우로 제한한다. m은 접두(prefix) 토큰의 윈도우로 시각 토큰과 프롬프트를 모두 포함하며, 한 번의 추론 동안 고정된다. 페이지 수나 문서 해상도에만 의존할 뿐 디코딩 길이에 따라 변하지 않는다. 디코드 영역의 윈도우 n도 크기가 고정이며 인과적으로 미끄러진다.
P는 길이 Lm의 접두 구간으로 이후 모든 토큰에 전역적으로 보이고, Dn(t)는 디코드 영역 위의 너비 n 인과적 슬라이딩 윈도우다. 토큰 t에서 위치 j로의 어텐션 가중치와 출력 표현은 다음과 같다.
각 디코딩 토큰은 모든 접두 토큰을 지속적 전역 문맥으로 attend하되, 이미 생성된 토큰에 대해서는 경계 지어진 인과 윈도우 안에서만 국소적으로 attend한다. 그 결과 전체 접두 정보 접근을 유지하면서도 늘어나는 디코드 시퀀스의 어텐션 비용을 줄인다.
파랑 = 참조(시각+프롬프트) attend · 주황 = 작업 기억(최근 n) attend · 어두움 = no attend. R-SWA는 바닐라 SWA와 달리 시각 토큰을 상태 전이에서 배제해 시각 토큰 충실도를 보존한다.
DeepSeek OCR 베이스라인은 표현력은 강하나 KV 캐시 압력이 막대한 표준 MHA를 쓴다. R-SWA는 항상 크기 Lm의 전체 접두 캐시를 유지하되, 생성된 연속분에 대해서는 최근 n개 토큰만 보관한다.
표준 MHA의 캐시는 T에 따라 무한히 커지지만, R-SWA의 디코드 측 캐시는 상수 윈도우 크기로 상한된다. 감소를 정량화하기 위해 캐시 비율 ρ(T)를 정의한다.
생성 길이가 충분히 길어 T ≫ n이면 ρ(T) = (Lm+n)/(Lm+T)로 T가 커질수록 감소하고, 디코드 길이가 접두 길이와 윈도우 크기를 압도하면 ρ(T) ≈ (Lm+n)/T → 0이 된다.
따라서 장기 시퀀스 디코딩에서 R-SWA는 KV 캐시 요구를 T에 대한 선형 증가에서 경계 지어진 양 Lm+n으로 낮춰, 표준 MHA 대비 상당한 메모리 절약을 낳는다. R-SWA가 제한된 자원에서 거의 무제한에 가까운 파싱을 가능케 하는 초석이다.
디코딩 길이가 늘어남에 따라 Flash Attention v3 커널의 호출당 시간을 측정하면, DeepSeek OCR의 표준 MHA 커널은 매 디코딩 step마다 지연이 커진다. 반면 Unlimited OCR(UOW)에서는 LLM 디코더 모든 층에 R-SWA를 적용한 직접적 효과로 시간이 일정하게 유지된다. DeepSeek OCR에서 KV 캐시 길이가 특정 정렬 경계를 넘을 때 데이터 전송 효율이 급락하며 발생하는 스파이크도 R-SWA에서는 나타나지 않는다. 추론 중 GPU 메모리 사용 패턴도 동일하다. 원본은 선형으로 증가하지만 Unlimited OCR은 고정이다. 연산 비용과 메모리 사용량의 이 동시 안정성이 바로 장기 파싱을 가능케 하는 요소다.
Unlimited OCR 학습을 위해 약 200만 개 문서 OCR 샘플을 구성하며, 단일 페이지와 다중 페이지 비율은 9:1이다.
단일 페이지 PDF는 Paddle OCR로 주석을 달아 각 블록의 좌표와 내용을 이어 붙여 종단간 검출·파싱 정답을 만든다. 각 요소 좌표는 0–1000 범위로 정규화한다.
다중 페이지 데이터는 단일 페이지를 이어 붙여 합성하며, 2–50 페이지로 이루어진 약 20만 샘플을 무작위 생성하고 페이지 구분자로
DeepSeek OCR을 기반으로 단 200만 PDF 문서 데이터에 추가 학습한 것만으로 Unlimited OCR은 종단간 SOTA를 달성한다. 이는 파싱 작업에서 R-SWA의 유효성을 입증한다.
OmniDocBench v1.5에서 DeepSeek OCR 대비 텍스트 편집거리가 0.035 줄고 표 TEDS가 5.96% 향상된다. 이는 이력 정보가 인과적·연속적으로 슬라이딩 윈도우에 공급되어, 모델이 단 몇 개 토큰만 보고도 OCR 진행 위치를 명확히 파악함을 보여 준다. v1.6에서도 종합 93.92%로 다시 종단간 SOTA에 도달해, 단일 페이지 PDF 수준 OCR에서는 모든 표준 어텐션을 너비 128의 R-SWA로 완전히 대체하는 것이 효과적이고 무손실임을 증명한다.
| 모델 | 크기 | 종합↑ | 텍스트Edit↓ | 수식CDM↑ | 표TEDS↑ | 표TEDS-S↑ | 읽기순서Edit↓ |
|---|---|---|---|---|---|---|---|
| ▸ 종단간 모델 (v1.5) | |||||||
| Gemini-2.5 Pro | — | 88.03 | 0.075 | 85.82 | 85.71 | 90.29 | 0.097 |
| dots.ocr | 3B | 88.41 | 0.048 | 83.22 | 86.78 | 90.62 | 0.053 |
| Qwen3-VL | 235B | 89.15 | 0.069 | 88.14 | 86.21 | 90.55 | 0.068 |
| DeepSeek-OCR 2 | 3B-A0.5B | 89.17 | 0.049 | 86.85 | 85.60 | 90.06 | 0.060 |
| DeepSeek-OCR (베이스라인) | 3B-A0.5B | 87.01 | 0.073 | 83.37 | 84.97 | 88.80 | 0.086 |
| Unlimited-OCR | 3B-A0.5B | 93.23 | 0.038 | 92.61 | 90.93 | 94.07 | 0.045 |
| ↑ 베이스 대비 Δ | +6.22 | −0.035 | +9.24 | +5.96 | +5.27 | −0.041 | |
| ▸ 종단간 모델 (v1.6) | |||||||
| FireRed-OCR | 2B | 93.26 | 0.037 | 95.44 | 88.04 | 91.06 | 0.131 |
| Logics-Parsing-v2 | 4B | 93.33 | 0.041 | 95.65 | 88.42 | 91.98 | 0.137 |
| Qianfan-OCR | 4B | 93.90 | 0.040 | 95.08 | 90.53 | 93.31 | 0.13 |
| Unlimited-OCR | 3B-A0.5B | 93.92 | 0.042 | 95.79 | 90.16 | 93.32 | 0.129 |
나아가 Unlimited OCR은 DeepSeek OCR의 이점을 모두 누린다. 활성 0.5B 파라미터만의 MoE 구조로 추론 효율이 매우 높다. OmniDocBench "Base" 모드에서 5,580 TPS(512 동시성)로 DeepSeek OCR의 4,951 TPS 대비 12.7% 빠르다. 출력이 길수록 이 이점은 더 뚜렷해진다.
OmniDocBench v1.5의 9개 문서 유형 비교에서, Unlimited OCR은 DeepSeek OCR 대비 모든 지표에서 명확하고 일관된 향상을 보인다. 디코더 측 최적화인 R-SWA가 타협 없는 개선, 즉 진정한 "공짜 점심"을 제공함을 보여 준다. DeepSeek OCR 2와 비교해도 텍스트 편집거리·읽기순서 모두 9개 중 7개에서 앞선다. PPT·신문·잡지·노트 같은 복잡한 레이아웃에서도 불리하지 않아, LLM 디코더의 모든 표준 어텐션을 R-SWA로 대체하는 것이 파싱 작업에 완결적이고 건전함을 거듭 확인한다.
장기 파싱은 Unlimited OCR의 새로운 능력이다. 이전 모델을 가로막은 두 장애물은, 첫째 지나치게 긴 출력이 최대 토큰 한도를 쉽게 넘는다는 점, 둘째 출력 지연이 시퀀스 길이에 따라 커져 수십 페이지 OCR이 점점 느려진다는 점이다.
R-SWA를 갖춘 Unlimited OCR은 수십~수백 페이지를 한 번에 prefill하고 첫 페이지부터 마지막까지 연속 파싱한다. 이 과정 내내 KV 캐시가 고정되어 출력 지연이 일정하게 유지된다. 20 페이지를 동시 입력해도 강한 결과를 유지하며, 40+ 페이지에서도 편집거리는 0.11 미만, Distinct-35는 97%다. 반복 오류 사례를 살펴보면 대부분 PDF의 작은 글자가 식별하기 어려운 곳에서 발생하는데, 이는 다중 페이지 조건에서 DeepEncoder "Base" 모드(1024×1024)를 쓴 탓이지 R-SWA가 장기 파싱에서 방향을 잃은 것이 아니다.
| 지표 \ 페이지 | 2 | 5 | 10 | 15 | 20 | 40+ |
|---|---|---|---|---|---|---|
| Distinct-20 ↑ | 99.76% | 99.78% | 97.49% | 99.92% | 98.73% | 96.08% |
| Distinct-35 ↑ | 99.87% | 99.98% | 99.83% | 99.99% | 99.89% | 96.90% |
| 편집거리 ↓ | 0.0362 | 0.0452 | 0.0526 | 0.0787 | 0.0572 | 0.1069 |
이상적 동시성 조건에서 두 모델의 초당 출력 토큰(TPS)을 비교한다. prefill 길이는 10으로 고정하고 나머지 설정은 동일하다. 256 토큰에서는 두 모델 속도가 사실상 같지만, 출력이 길어질수록 DeepSeek OCR의 TPS는 꾸준히 하락하고 6,000 토큰에서 R-SWA를 쓰는 Unlimited OCR에 35% 뒤진다.
표 4 · 이론적 추론 성능 상한 비교(TPS). DeepSeek OCR은 길이가 늘수록 하락하나 Unlimited OCR은 일정하게 유지된다. 일관된 생성 속도가 장기 OCR의 결정적 요건임을 뒷받침한다.
이 보고서는 Unlimited OCR 모델과 그 장기 파싱 능력을 떠받치는 R-SWA 알고리즘을 제안한다. 종단간 모델 디코더의 모든 표준 어텐션을 인과적 참조 기반 SWA로 대체해도 파싱 작업 성능이 무손실임을 검증한다. 이는 모델이 이력 출력의 유용한 정보를 윈도우로 연속적으로 넘기도록 학습함을 뜻하며, 이 부드러운 형태의 망각은 사람이 책을 베껴 쓰는 방식과 일치한다. R-SWA가 향후 더 많은 작업에 적용되어, 어텐션 연산과 메모리 사용량이 더는 장기 파싱 분야의 병목이 되지 않게 하리라 본다.